







1 前言
1.1 研究背景
岩石是现代建筑业和制造业的重要原材料,除了作为原材料使用以外,还可以对其进行勘探开发挖掘岩油气藏,若能智能且准确地识别岩石岩性、计算岩石含油量,这将会是一笔巨大的社会财富。
天然岩石有多种来源和用途,根据其不同的特征,可分为火成岩、沉积岩和变质岩三类。岩石的探测与识别是地质调查研究和矿产资源勘查的基础工作,岩石的精准识别与分类对地质的探测与识别极为重要,一般可通过多种方式进行鉴定,例如重磁、测井、地震、遥感、电磁、地球化学、手标本及薄片分析方法等方法。而现场的工作条件通常仅限于目视方法,包括对细粒岩石使用放大镜,视觉检测评估诸如颜色、成分、粒度和结构等属性。
近些年来,卫星和遥感技术的进步推动了多光谱遥感技术的发展,以分类不同类型的地物,包括岩石。但是,利用遥感技术在野外获取超高分辨率岩石图像的成本很高。因此,利用无人机和卫星携带的高光谱技术进行数据采集的高成本往往阻碍了岩石岩性识别的自动化。
而图像采集和计算机图像模式识别技术的迅速发展,使得从野外采集的图像中识别岩石的自动系统得以发展。这些技术为辅助地质学家判断和识别岩石岩性提供了极大的便利,也极大推进了深度学习算法在这一方向的落地可能。
1.2 研究任务
利用图像处理技术和深度学习算法解决以下两个任务:
(1)岩性识别与分类
以白光环境下拍摄的岩石样本图像数据为基础,设计合适的机器学习或深度学习算法,构建岩石样本岩性智能识别模型。
(2)计算岩石含油面积百分含量
以荧光环境下拍摄的岩石样本图像数据为基础,借助石油在紫外线的照射下具有发光的特性,设计合适算法计算图像中岩石的含油面积百分比含量。
2 数据探索
2.1 类别不平衡问题
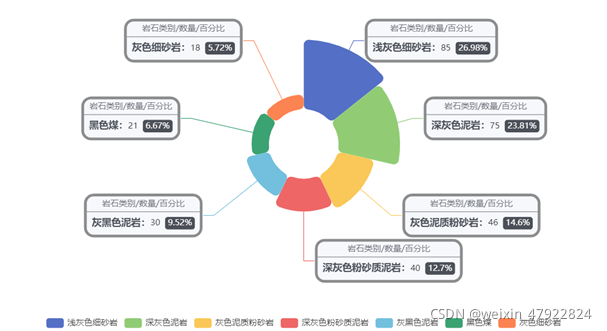
所提供的岩石样本数据中,存在着严重的类别不平衡问题,如图 2‑1所示。其中浅灰色细砂岩样本数量最多,占全体数据的26.98%;深灰色泥岩次之,占比23.81%;灰色细砂岩的样本数量最少,仅有5.72%,不足浅灰色细砂岩的四分之一。
如此类别不平衡的数据集,模型很容易过度拟合样本更多的类别,同时忽视对小样本类别的学习。因此类别不平衡问题是模型训练时不可忽视的重要问题。传统的处理类别不平衡问题的方法主要是重采样,重采样可划分为两类,一是对数量多的类别欠采样,二是对数量少的类别过采样。重采样后的数据集具有平衡的类别,但数据集中包含的信息并不会因此增加,故而可能会导致模型欠拟合于数量少的类别而过拟合数量多的类别。因此,可换个角度,从损失函数方面考虑类别不平衡问题的处理。
2.2 数据质量问题
经观察发现,样本中提供的七类岩石的类内差异较大,同时也可能混杂有标注错误的样本。以深灰色粉砂质泥岩为例,抽选编号为73、81、137的样本,如图 2‑2第一行所示。从中可见,同一类岩石的颜色、形态可能大相径庭,这无疑加大了分类的难度。图 2‑2按列展示了不同类别岩石可能存在的相似情况,在缺乏专业知识的人眼中,每一组图片可能相差无几(可能是错误标记)。此外,如此巨大的类内差异和微小的类间差异很容易掩盖错误标注的样本,从而误导模型训练时优化的方向,降低模型识别能力。

众所周知,拍摄环境对照片呈现的内容影响极大。如果按干燥程度区分,可将环境简单分为干燥、潮湿、有水三类;按光照情况划分,则可分为光照好和光照差两类。
以灰黑色泥岩为例,选取五个不同环境下拍摄的典型样本进行展示,如图 2‑3。对比40号和51号图像,可见越潮湿的岩石颜色越深。结合309号和198号图像,可发现当岩石间有水时,水面的反光甚至会掩盖岩石的纹理细节,即使在光照不好的情况下也不例外。整体上看,光照情况越好的图像的纹理细节越清晰,对岩石颜色的反映越真实。

此外在部分的岩石样本数据中,还存在着掺杂其他类别岩石或杂物的情况。以类别为浅灰色细砂岩的235号照片为例,如图 2‑4所示。图像混杂了大量橙色、褐色和黑色的小石块,同时落入一片树叶,遮挡将近八分之一的区域。如此杂乱的数据无疑是对数据预处理和模型提取特征能力的一大挑战。

2.3 图像格式问题
样本图像中存在bmp和jpg两种格式,且两种格式的图像大小和风格均有巨大差异。bmp格式图像无明显背景,大小为3000x4096(像素)。此类照片受环境因素影响大,光照、潮湿程度各异,且往往混有其他岩石或物体。jpg格式图片存在显著蓝色背景、大小为2048x2448(像素)。此类照片光照差异不大,岩石中的杂物也不多,但其中的岩石多为细小的碎块,难以提取纹理特征。

3 数据预处理
由于数据集中照片的分辨率较高且样本数较少,可选择通过裁切图像的方式增加样本数量。根据不同的模型特点,本文有针对性地使用了随机裁剪和网格裁剪这两种略有不同的增强方式,其示意图如图 3‑1。
其中随机裁剪即在原图上随机剪出预设大小的小块图像作为全新的样本,这种方式的优点在于生成的样本数量多,模型有机会学习到原始图像的所有信息。但由于该方式的随机性较强,难以预料裁剪出的内容,因此当数据质量不高时,依靠随机裁剪扩增的样本中可能包含大量的噪声。
而网格裁剪即按照预设的网格,将图像裁剪为相同尺寸的小块。使用网格裁剪扩增的样本具有固定的数量和内容,虽然会损失一部分横跨网格的信息,但更便于进行数据分析和预处理,从而剔除噪声数据。

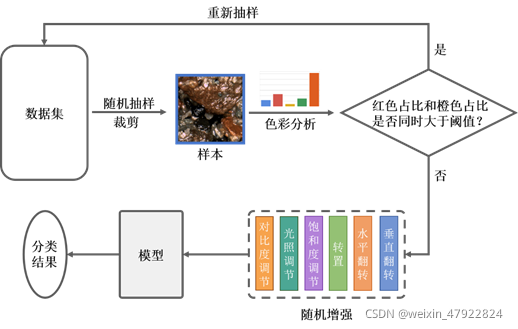
通过前文的探索性数据分析,常发现某不知名红褐色石头混杂在样本中,且不属于任何一类。因此在裁剪后,选择计算红色和橙色在样本中所占的比例,通过实验确定阈值,从而剔除以红褐色岩石为主体的样本。此外,根据前文可知同一类岩石可能因光照、潮湿程度等环境因素改变颜色、纹理。因此为了增加模型的鲁棒性,选择采用随机增强策略对样本进行随机变换。
图像增强是一项通过简单图像变换使数据特征更明显的技术,现已逐渐推广到数据扩增用途。而随机增强即预先选择多种图像变换方案,并以一定概率随机组合这些变换,使得样本图像千变万化,从而训练模型提取图像中最关键的特征信息,使模型具有更强的泛化能力。为对抗样本中存在的光照、潮湿等环境因素的影响,选择水平翻转、垂直翻转、随机饱和度调节、随机亮度调节、随机对比度调节五种基础增强方案,并在训练模型时随机组合这些基础方案。以16号样本为例,五种基础增强方案的示意图如图 3‑2。

综上所述,数据预处理技术路线图如下图 3‑3。
4 基于DCNN的岩性智能识别与分类
经过一系列的探索性数据分析,发现除轮廓、色彩等信息对岩石分类有帮助外,岩石的局部纹理特征也对分类效果起着至关重要的作用。因此,本文构建了全局-局部模型,用以提取图像全局和局部的纹理特征,再使用精心设计的融合模块将两种特征合并,馈入前馈神经网络,得到分类结果。
除此之外,注意到所提供的岩石图像中可能混入了其他种类的岩石,这会在一定程度上影响模型分类结果。因此本文基于EfficientNet-B3和MobileNet-V3构建了两个仅关注局部纹理的岩性识别与分类模型,借助置信学习剔除噪声数据,并提出了滑动窗口预测法以综合考量图像主体所属的类别,进一步削弱由图像数据质量问题带来的负面影响。
最后,再以“硬投票(Hard Voting)”的方式对三个模型的预测结果进行融合,从而得到更为鲁棒且精确的预测结果。
4.1 基于随机裁剪数据的图像分类模型
本节基于ResNeXt-50进行改进,充分融合图像的全局与局部信息,采用随机裁剪与图像缩放得到的图像作为训练集进行模型训练,得到最终的“全局-局部模型”。
4.1.1 ResNeXt网络构架
随着计算机硬件设备的不断升级,计算机视觉领域迅猛发展,用于图像识别的网络架构层出不穷。众所周知,网络的深度是决定模型性能的关键因素。理论上可以通过增加网络的层数,让模型获得提取更复杂、更有效的特征的能力,从而使得模型获得更好的性能。但2016年何凯明等人在ResNet 一文中指出网络的层数与模型的性能并非成正比的关系,深度高的模型甚至比深度低的模型效果可能更差,即网络退化。因此,何凯明团队提出“残差结构”来解决网络退化问题,如下图 4‑1所示。
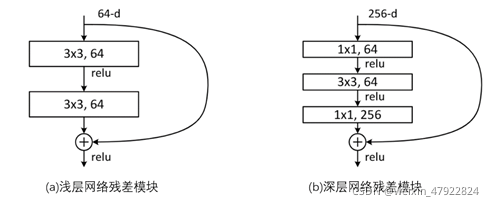
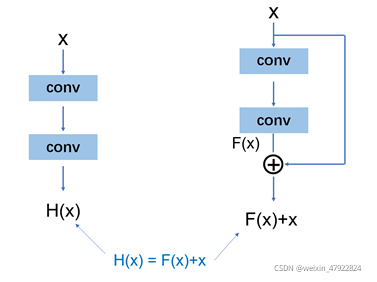
当输入为 x x x 时,网络学习到的特征为 H ( x ) H(x) H(x),由于存在网络退化现象,ResNet 在原来的模块中增加一个旁路(shortcut),此时模型学习到的原始特征为 F ( x ) + x F(x)+x F(x)+x ,网络便只需学习 H ( x ) − x = F ( x ) H(x)-x=F(x) H(x)−x=F(x) 的残差信息,这与直接学习原始特征的网络相比更为简单且有效。此外,当残差为0时,该堆叠模块仅做了简单的恒等映射,不会使模型的性能下降,从而解决了模型层数越多,网络性能越差的问题。
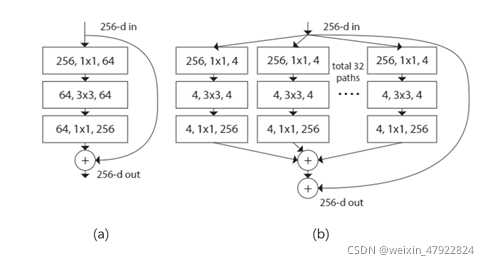
ResNeXt 是由Facebook在2017年提出的一种基于ResNet改进的网络架构。ResNeXt将ResNet网络中的“直线式”残差结构改为多分支的同构结构,其与ResNet的区别如图 4‑3所示。
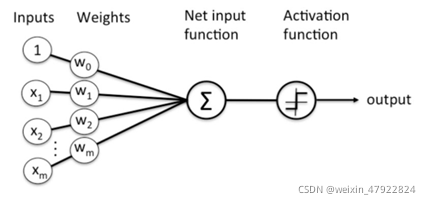
下图 4‑4为一个没有偏置项的线性激活神经元,它是一个最简单的“split-transform-merge”结构,它将输入的 m m m 个元素,分配到 m m m 个分支进行权重加权,最后对所有的支路求和。由此神经网络的一个单元可以如下式所示:
F ( x ) = ∑ i = 1 m w i ∗ x i F(x)=\sum_{i=1}^{m}{w_i}*x_i\\ F(x)=i=1∑mwi∗xi
而ResNeXt就是借鉴了“split-transform-merge”想法,将原本的残差模块分成多个小组(即多种特征)进行独立的同构变换,最后再对其进行特征融合。ResNeXt的残差结构可以用如下公式表示:
y = x + ∑ i − 1 C T i ( x ) y=x+\sum_{i-1}^{C}{T_i(x)}\\ y=x+i−1∑CTi(x)
其中,C 表示每个残差模块中的分组个数, T i T_i Ti 表示特征 x x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











