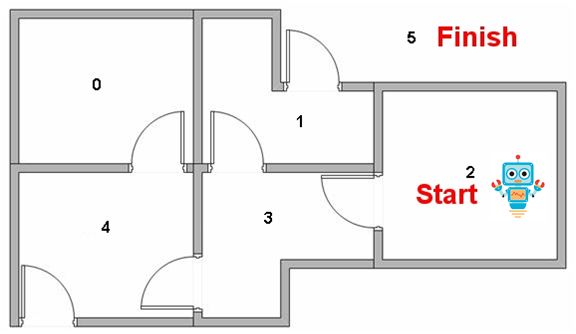
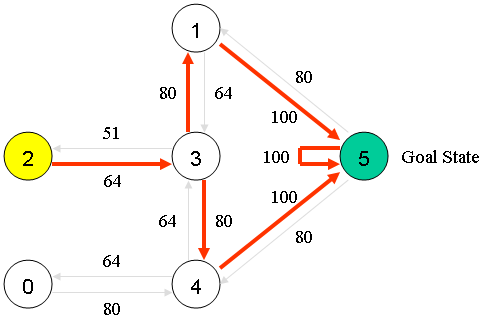
假设建筑物中有5个房间,如上图所示。我们将每个房间的编号设为0到4.建筑物的外部可以被认为是一个大房间(5)。当然,5号房间的回报率为100,其他所有与目标房间的直接连接奖励为100。 Q(1,5)= R(1,5)+ 0.8 * Max [] = 100 + 0.8 * 0 = 100 机器人从状态2开始,我们希望他能够学习到房子外面状态5。 状态列表: 状态0可到达








 本文通过一个建筑物中5个房间的例子,解释了Q学习如何帮助机器人从状态2学习到达目标状态5。介绍了Q-table的初始化和更新过程,通过不断随机选择初始状态并根据R-table进行转移,逐步优化Q-table,最终实现无监督学习的目标。
本文通过一个建筑物中5个房间的例子,解释了Q学习如何帮助机器人从状态2学习到达目标状态5。介绍了Q-table的初始化和更新过程,通过不断随机选择初始状态并根据R-table进行转移,逐步优化Q-table,最终实现无监督学习的目标。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






