







neo4j批量插入效率低问题解决
1.问题场景
使用neo4j命令一条条插入数据时非常慢。有几万或者几十万数据时需要几个小时。
2.解决办法
将数据写入到csv文件中,然后使用neo4j命令直接读取csv文件。(csv文件必须要有第一行的
字段名,user.csv放在/var/lib/neo4j/import/文件夹下,可通过配置修改默认存放目录)
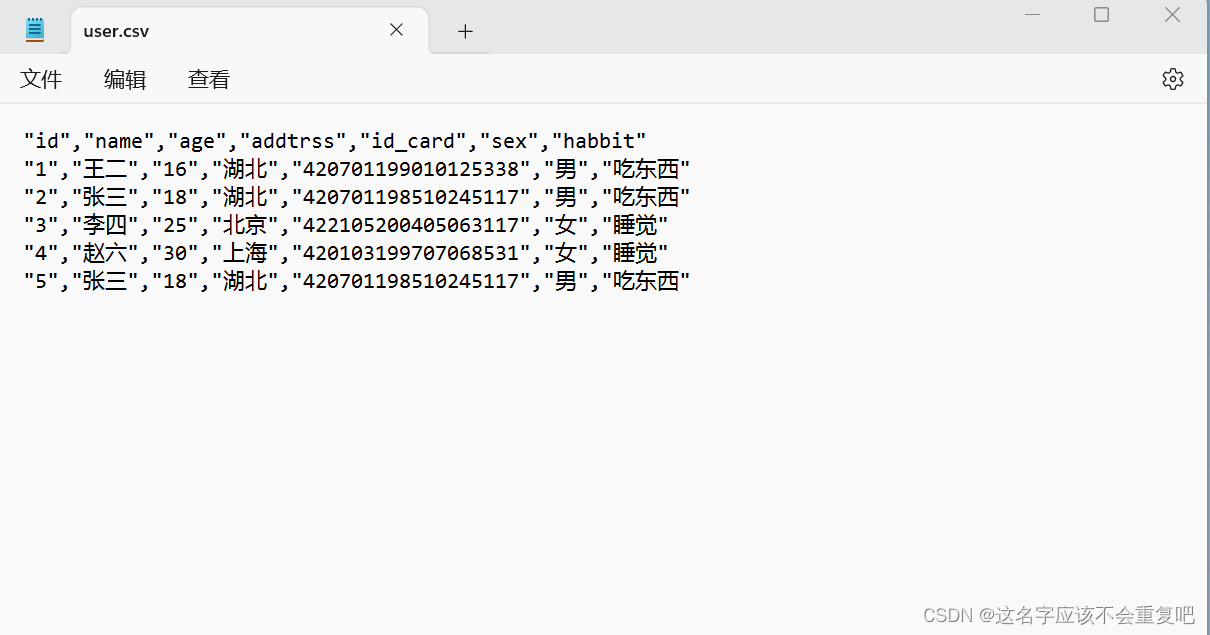
2.1.例如有user.csv文件内容如下图所示,则导入命令为
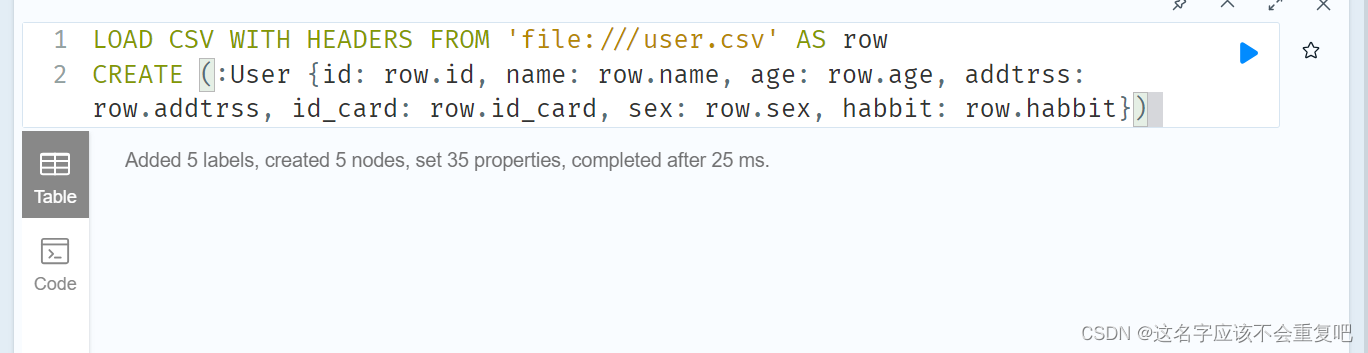
LOAD CSV WITH HEADERS FROM 'file:///user.csv' AS row CREATE (:User {id: row.id, name: row.name, age: row.age, addtrss: row.addtrss, id_card: row.id_card, sex: row.sex, habbit: row.habbit})
包含开启事务,自动提交的命令
:auto USING PERIODIC COMMIT 10 LOAD CSV WITH HEADERS FROM 'file:///user.csv' AS row CREATE (:User {id: row.id, name: row.name, age: row.age, addtrss: row.addtrss, id_card: row.id_card, sex: row.sex, habbit: row.habbit})
2.2.可以只插入自己需要的字段的数据,例如还是上面user.csv文件,但只需要其中id,name,age字段,则可以修改语句为:
LOAD CSV WITH HEADERS FROM 'file:///user.csv' AS row CREATE (:User {id: row.id, name: row.name, age: row.age})
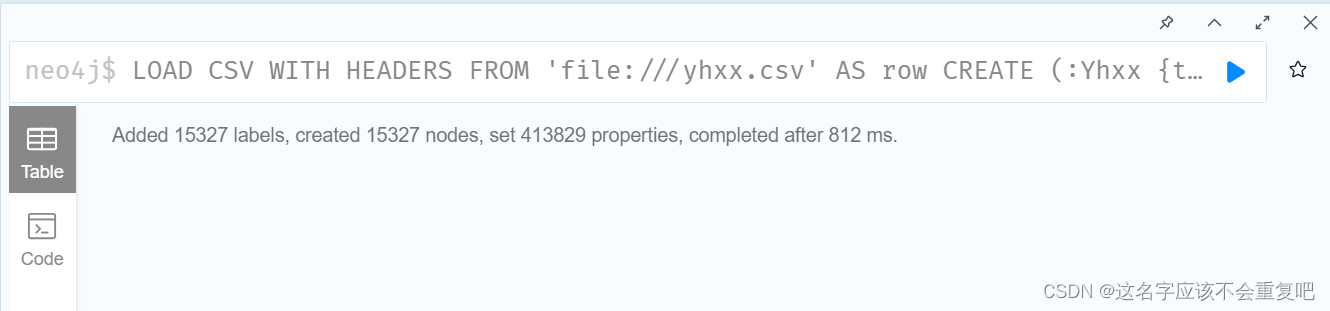
2.3.读取一万条数据测试
可以看到插入15000条数据只用了1秒钟。
2.4.导入关系
请确保在执行导入命令之前,已经在Neo4j数据库中创建了适当的标签和索引,以便正确地导入数据。
LOAD CSV WITH HEADERS FROM 'file:///your_file.csv' AS row MATCH (sourceNode:Label1 {property1: row.sourceProperty}) MATCH (targetNode:Label2 {property2: row.targetProperty}) CREATE (sourceNode)-[:RELATIONSHIP_TYPE]->(targetNode)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









