







 该文介绍如何在Postgres数据库中处理重复数据,通过查询每个id_card的最小ID并删除其余记录来保持唯一性。具体步骤包括查询重复数据、构建删除SQL语句,并提供了创建用户表及插入数据的SQL示例。
该文介绍如何在Postgres数据库中处理重复数据,通过查询每个id_card的最小ID并删除其余记录来保持唯一性。具体步骤包括查询重复数据、构建删除SQL语句,并提供了创建用户表及插入数据的SQL示例。
postgres、mysql查询重复数据并删除只保留一条
1.文章以postgres数据库为例。例如有一张用户表,id是主键,现在有id_card重复的数据。(表中id为2和5的数据)。建表sql语句在文章最后
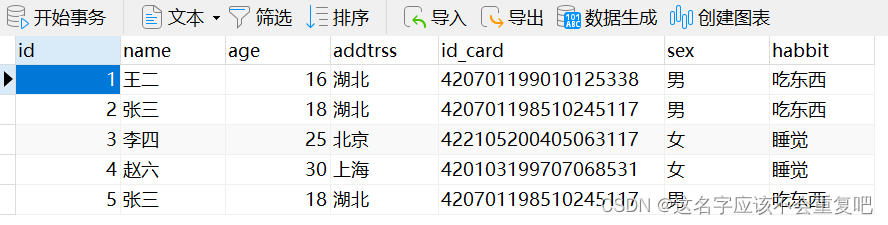
2.查询重复数据并删除
SELECT MIN ( ID ) AS min_id FROM “user” GROUP BY id_card 。意思是根据id_card查询出所有的用户id(一个id对应一个id_card),然后执行完整sql表示将其余的id数据都删除,因为id本来就是不重复的,就达到了每条id保留一条的效果
SELECT * FROM "user"
WHERE
ID NOT IN ( SELECT MIN ( ID ) AS min_id FROM "user" GROUP BY id_card )
delete FROM "user"
WHERE
ID NOT IN ( SELECT MIN ( ID ) AS min_id FROM "user" GROUP BY id_card )
3.建表以及数据sql语句
DROP TABLE IF EXISTS "public"."user";
CREATE TABLE "public"."user" (
"id" int4 NOT NULL,
"name" varchar(255) COLLATE "pg_catalog"."default",
"age" int4,
"addtrss" varchar(255) COLLATE "pg_catalog"."default",
"id_card" varchar(255) COLLATE "pg_catalog"."default",
"sex" varchar(255) COLLATE "pg_catalog"."default",
"habbit" varchar(255) COLLATE "pg_catalog"."default"
)
;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO "public"."user" VALUES (1, '王二', 16, '湖北', '420701199010125338', '男', '吃东西');
INSERT INTO "public"."user" VALUES (2, '张三', 18, '湖北', '420701198510245117', '男', '吃东西');
INSERT INTO "public"."user" VALUES (3, '李四', 25, '北京', '422105200405063117', '女', '睡觉');
INSERT INTO "public"."user" VALUES (4, '赵六', 30, '上海', '420103199707068531', '女', '睡觉');
INSERT INTO "public"."user" VALUES (5, '张三', 18, '湖北', '420701198510245117', '男', '吃东西');
-- ----------------------------
-- Primary Key structure for table user
-- ----------------------------
ALTER TABLE "public"."user" ADD CONSTRAINT "user_pkey" PRIMARY KEY ("id");

















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









