







 本文介绍了滚动数组作为动态规划的一种空间优化技巧,通过斐波那契数列和0/1背包问题举例,阐述如何通过观察dp方程来减少空间复杂度。滚动数组通过覆盖旧数据,只保留必要的状态,实现从二维到一维的降维,从而在某些情况下降低空间需求。在0/1背包问题中,通过倒序更新保证了数据的正确性。通过理解和熟练运用滚动数组,可以在解决动态规划问题时有效地节省空间。
本文介绍了滚动数组作为动态规划的一种空间优化技巧,通过斐波那契数列和0/1背包问题举例,阐述如何通过观察dp方程来减少空间复杂度。滚动数组通过覆盖旧数据,只保留必要的状态,实现从二维到一维的降维,从而在某些情况下降低空间需求。在0/1背包问题中,通过倒序更新保证了数据的正确性。通过理解和熟练运用滚动数组,可以在解决动态规划问题时有效地节省空间。
前提概要
首先呢,滚动数组是一种能够在动态规划中降低空间复杂度的方法,
有时某些二维dp方程可以直接降阶到一维,在某些题目中甚至可以降低时间复杂度,是一种极为巧妙的思想,
简要来说就是通过观察dp方程来判断需要使用哪些数据,可以抛弃哪些数据,
一旦找到关系,就可以用新的数据不断覆盖旧的数据量来减少空间的使用,
接下来我会介绍一些简单例题来具体解释一下滚动数组的作用。
先以斐波那契数列为例
我们先以斐波那契数列来简单感受一下滚动数组的魅力,先上一段经典的代码(使用滚动数组)
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[37];
a[0]=1;
a[1]=1;
//求斐波那契数列第37个数
for(int i=2;i<=36;i++){
a[i]=a[i-1]+a[i-2];
}
printf("%d\n",a[36]);
return 0;
}
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[3];
a[0] = 1;
a[1] = 1;
for(int i = 1;i <= 35;i++)
{
a[2] = a[0] + a[1];
a[0] = a[1];
a[1] = a[2];
}
printf("%d\n",a[2]);
return 0;
}
通过观察斐波那契数列方程 f(n)= f(n-1)+ f(n-2),我们可以发现,
我们实际上只需要前两个递推的数求和即可,于是我们可以使用数组的前三个位置来分别存贮数据, 待计算完之后,再用新的数据将旧数据覆盖。
这样我们 本来需要用三十多个位置的数组,最终却只用了三个位置, 大大减少了空间复杂度。
对于某些只需要最终答案的题目,我们可以抛弃掉当中一些不必要存贮的数据,来减少空间的使用。
再以0/1背包为例
这里我们以HDU2602的bone collector题目为例子,
对于每一个状态,我们都可以判断这次是取还是不取或是取不下。
枚举第i个物品,枚举j代表背包可以放的下的体积。
若不取或者取不下,那么结果就是dp[i-1][j],
若取,就由前面的状态预留出weight[i]的位置再加上i物品的价值,即dp[i-1][j-weight[i]]+value[i]。
可得二维dp方程dp[i][j]=max(dp[i-1][j],dp[i-1][j-weight[i]]+value[i])
我们先来看二维的dp矩阵,
背包价值是{1,2,3,4,5},对应的体积是{5,4,3,2,1};

以dp[4][j]->dp[5][j]为例,此时第5个物品的体积为1,价值为5
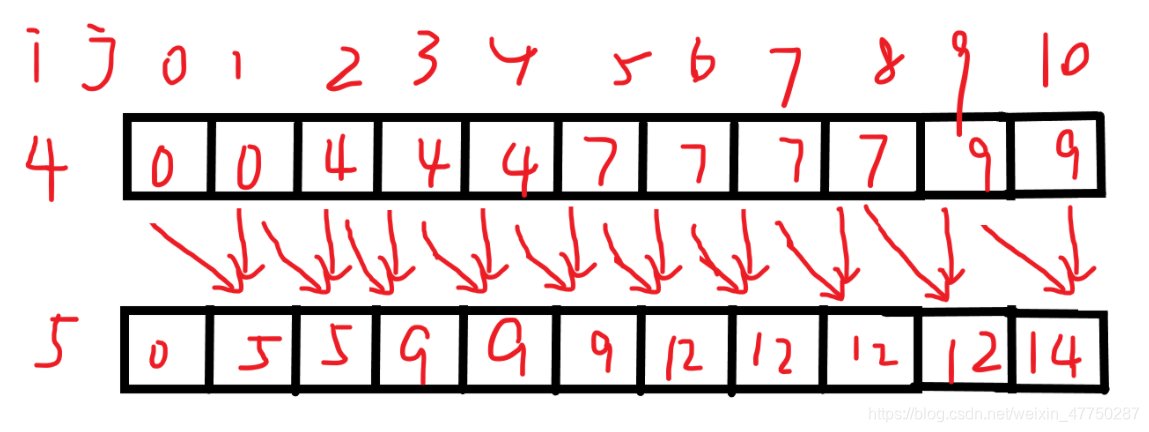
我们可以清楚的看出来,dp方程递归过程是不断地由上一行的数据传递到下一行,
比如最后dp[5][10]是由dp[5][10]=max(dp[4,10],dp[4,9]+5))=14推得的,
也就是说当我们递推到dp[i][j]时,对于那些只要求最终最佳答案的题目来说,只需要i-1这行的数据即可,至于上面的i-2,i-3都是不需要的数据,
题目如果并没有要求中间的状态(比如输出背包的方案),我们就可以将其省略来节省空间的使用。
所以我们可以只用一维数组dp[j]来记录数据dp[i][j]的状态,在更新的过程中不断用新的数据dp[j] (dp[i][j]) 覆盖掉旧的数据dp[j](dp[i-1][j])。
为什么j维度在01背包是逆序,完全背包是正序呢
- 我相信会有很多同学对01背包第二维j为什么是倒着递推有疑惑。
我们从正序进行,假设当i=5,j=9时,那么此时dp[9]是由前面的dp[8]和dp[9]递推更新,那么现在dp[9]实际上存贮的是递推得到的dp[5][9]而并非旧数据dp[4][9],那么也就不能保证dp[5][10]的递推成功(dp[5][10]正确值应该是由dp[4][10]和dp[4][9]递推得到的) ,但正序的做法却意味着可以多次调用前面的数据,相当于多次取用物品,也就是完全背包(物品可取次数为无限次)的思路了。 - 那该怎么确保不覆盖dp[9]存贮的数据dp[4][9]呢,那么倒序就起作用了。假设当i=5,j=10时,dp[10]内的数据存贮的是dp[4][10]的数据,由于j从尾部开始枚举,dp[10]就会由dp[9]和dp[10]递推得到(dp[9]存贮的是dp[4][9],dp[10]存贮的是dp[4][10]),那么此时dp[10]的值就更新为了dp[5][10]。然后依次类推,因为是倒序的缘故,那么接下来枚举的j都要比先前的j要来的小,所以当某个位置更新数据时,并不会调用其位置后面的数据,一定会是先调用其位置之前的旧数据,然后再将当前位置更新覆盖掉原来的旧数据,也就保证了数据更新的有序性。
小结
对于动态规划题目来说,我们可以先写出最原始的dp方程,再通过观察dp方程,使用滚动数组进行优化,我们需要思考如何更新数据和覆盖数据来达到降维的目的(可能需要很长的时间思考,不过熟能生巧)。
具体代码解析
#include<bits/stdc++.h>
using namespace std;
const int maxn = 1e3+10;
int t,n,v;
int dp[maxn];
int value[maxn];
int weight[maxn];
int main()
{
scanf("%d",&t);
while(t--)
{
memset(dp,0,sizeof dp);
scanf("%d %d",&n,&v);
for(int i = 1;i <= n;i++)
scanf("%d",&value[i]);
for(int i = 1;i <= n;i++)
scanf("%d",&weight[i]);
// for(int i = 1;i <= n;i++) 原始二维dp方程
// for(int j = 0;j <= v;j++)
// {
// if(j >= weight[i]) //若取得下,则可以选择取或不取
// dp[i][j]=max(dp[i-1][j],dp[i-1][j-weight[i]]+value[i]);
// else
// dp[i][j]=dp[i-1][j];
// }
for(int i = 1;i <= n;i++) //使用滚动数组优化后的dp方程
for(int j = v;j >= weight[i];j--) //倒序保证数据更新的有序性,保证只取一次,正序则是完全背包的写法
dp[j]=max(dp[j],dp[j - weight[i]] + value[i]);
printf("%d\n",dp[v]);
}
return 0;
}

















 1976
1976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









