




xpath库 解析网页数据
- 安装第三方库 pip install lxml
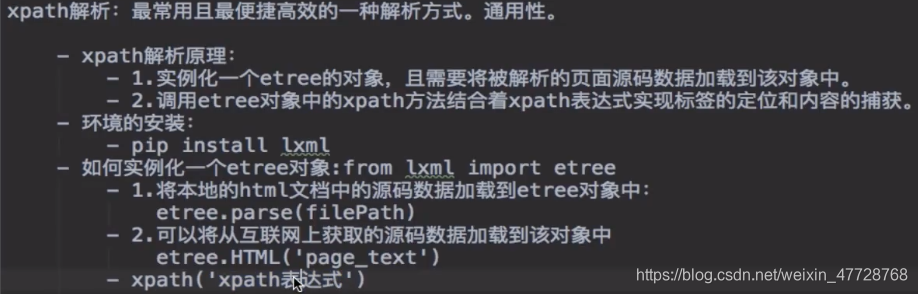
下列例子:

# codeing = utf-8
from lxml import etree
htm = '如上图'
data = etree.HTML(htm)
# xpath基本用法
data.xpath('//html/div/ul/li') # //为从跟节点开始查找,可以不用逐级查找,比如可以: '//ul/li'
# 记住这样返回的是个储存地址列表
data.xpath('//html/div/ul/li[1]') # 查找第一个元素,记住xpath中索引是从 1 开始的
data.xpath('//html/div/ul/li[1]/a/text()')[a] # 使用text()提取文本信息,注意提取出后是列表
# 输出结果:first item
data.xpath('//div/ul/li[@class = "item-inactive"]/a/text()') # 第三行,它的类是唯一性,用class属性直接定位查找提取,同样可以写: '//*[@class = "item-inactive"]/a/text()'
# 输出结果: third item
data.xpath('//a[@href = "link1.html"]/text()') # 从根节点查找到 a ,通过 href 属性查找提取;同样可以写: '//*[@href = "link1.html"]/text()'
data.xpath('//li[3]/a/@href') # 提取 li[3]中的 href 属性值
data.xpath('//li/@class') # 提取所有 class 属性值,没定位则所有
# xpath高级用法
all_a = data.xpath('//li[starts-with(@class,'item-')]') # 提取 class 为 item- 开头的所有内容
for i in all_a:
all_a.append(i.xpath('a/text()')[0]) # 继续提取all_a中的a下的文本信息
# 同样可以一步到位: '//li[starts-with(@class,'item-')]/a/text()' # 直接提取
data.xpath('//ul/text()') # 这样只能提取ul节点下的文本信息
data.xpath('string(//ul)') # 使用string()函数提取全部文本

















 1430
1430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









