









🕶️师兄简介:机械专业,通过自学成功进入IT领域,求学期间实现经济独立,对自学、兼职、计算机、学习规划等有独到见解!「点击了解更多」
🤖师兄致力解决在大学生活与学习中遇到的各种问题.
🎁 公众号「渣师兄」内回复「渣学」可获得超 5T 的新生见面礼!
🔗官方网站: 渣学网 →「zhaxueit.cn」→ 大学生活与学习一站式解决方案.
🙏找师兄帮忙「无偿」请➕💓:zhaxueit
📓进资源群「每日分享」【免费】(坑位有限)也请➕💓:zhaxueit 并备注「进群」
👀个人主页:@渣师兄 ,欢迎关注、私信师兄!
🐐 登高必自卑,行远必自迩.
🍇 我始终坚信越努力越幸运
⭐️ 那些打不倒我们的终将会让我们变得强大
🍑 希望在编程道路上深耕的小伙伴都会越来越好
文章目录
Python爬虫爬取动态网页的操作流程!
目标:掌握爬取动态网页的操作流程
爬取动态网页的操作流程详解(浏览器控制台流程)
第一步:打开动态加载的网页
第二步:按下F12进行检查找到网络选项内的XHR栏等待抓包
第三步:刷新动态网页
第四步:对动态网页进行一些操作使异步加载的数据包加载出来(动态数据包也就是XHR内的数据包)
第五步:分析动态加载的数据包
第六步:利用python模拟发送请求!
爬取动态网页【重中之重】
目标:
1:掌握什么是动态网页
2:掌握抓取动态网页的步骤以及方法
3:掌握抓取动态网页的注意事项
什么是动态网页
答:动态网页应该具备下面其中一个特点
特点1:网页的数据在源代码中查不到(网页源代码内没有你要找的数据)(比如腾讯招聘)
特点2:当你在网页中点击下一页或者其他操作时,网页局部刷新(比如小米应用网)
特点3:当你在网页中进行一些操作时(滑动滑轮等),数据才加载出来(比如豆瓣电影)
动态网站:腾讯招聘、小米应用网、豆瓣电影、有道翻译等等
抓取动态网页的步骤以及方法(小米应用网为例------局部刷新的url网站)
第一步:按下F12进入检查,找到网络选项开始进行抓包
第二步:动态加载的数据包一般都是json格式的,对动态网页进行操作让数据加载出来,然后直接筛选XHR格式的数据包即可
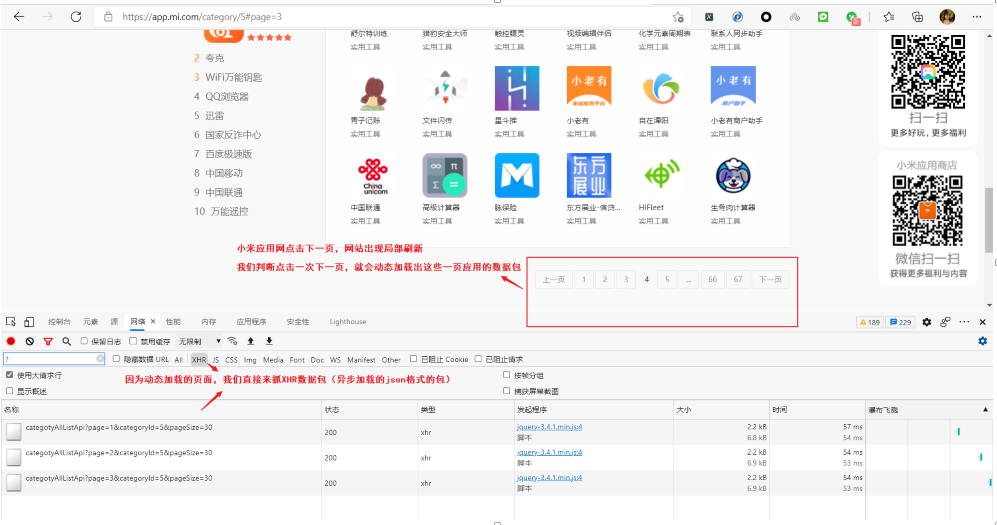
第三步:分析XHR选项内的数据包,找到真正要抓取的那个数据包(包含数据的数据包)
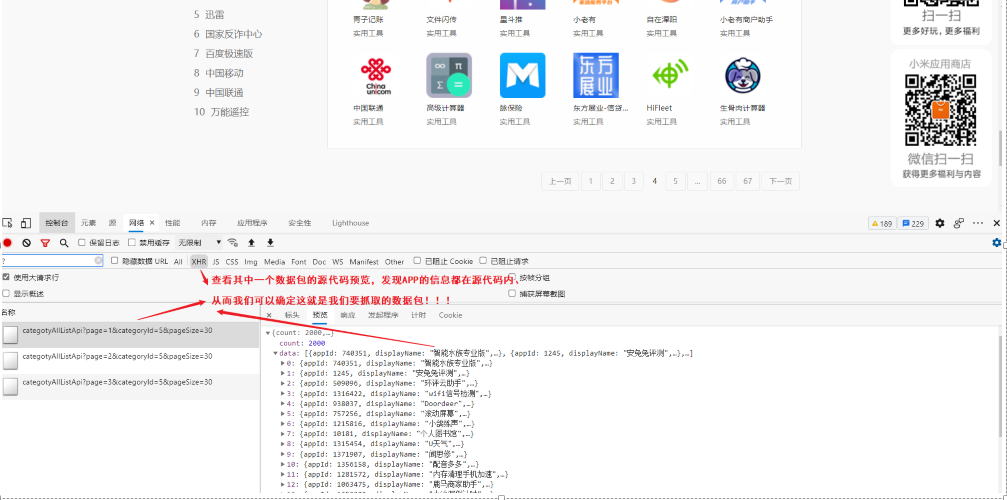
第四步:分析请求的url以及请求方式,如果是get请求,着重分析查询参数,post请求着重分析Form_data,找到所有动态加载的数据包其中的规律
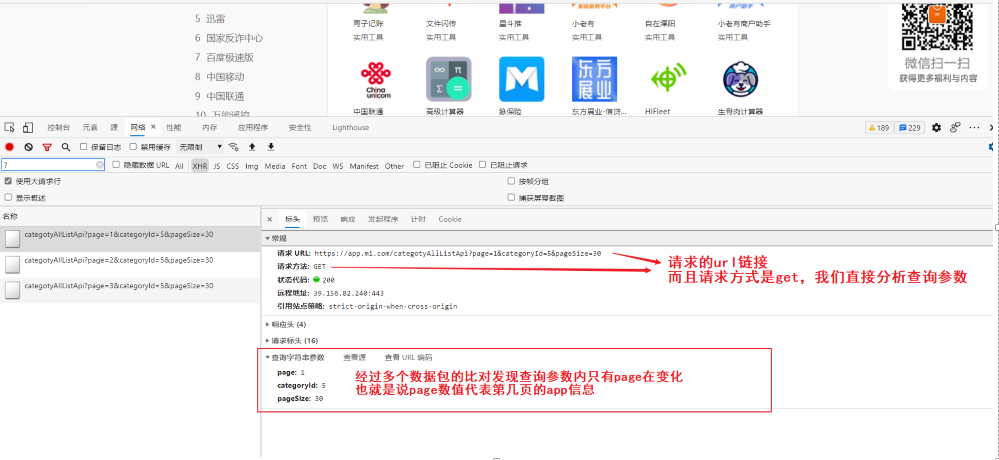
第五步:利用 python 程序模拟浏览器向上面的 url 发送请求即可(构建查询参数)
抓取动态网页的注意事项
1:动态加载的网页其中动态加载的数据包一般都是json格式(python中的字典格式)的字符串
2:requests模块向目标url发送请求获取对象的 json 方法可以将 json 格式的字符串转换为 Python 格式的字典!


















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











