




 本文介绍了MADDPG算法,它是基于DPG和DDPG的演化,用于解决连续状态和控制空间的问题。核心原理是Actor-Critic架构,Actor寻找最大Q值,Critic评估并指导Actor更新。算法利用神经网络处理连续性,采用固定网络技术以稳定更新过程。
本文介绍了MADDPG算法,它是基于DPG和DDPG的演化,用于解决连续状态和控制空间的问题。核心原理是Actor-Critic架构,Actor寻找最大Q值,Critic评估并指导Actor更新。算法利用神经网络处理连续性,采用固定网络技术以稳定更新过程。
MADDPG(Multi-agent Deep Deterministic Policy Gradient)由以下三部分演变而来:确定性策略梯度算法DPG(Deterministic Policy Gradient),深度确定性策略梯度算法DDPG(Deep Deterministic Policy Gradient)和多智能体深度确定性策略梯度算法MADDPG(Multi-agent Deeep Deterministic Policy Gradient),也就是说,整个算法的基础是DPG,并采用深度神经网络来解决控制空间不连续的问题,最后加入多个智能体,成为MADDPG。
因此,MADDPG主要解决的是连续状态空间及连续控制空间的问题。
首先,用一张图来表示DDPG的整体结构,其中,S表示智能体状态,A表示智能体的动作,Q值为从任务开始到结束智能体状态的总奖励值。而Actor-Critic网络则用来寻找最大的Q值。可以理解为Actor是演员,Critic是评论家。
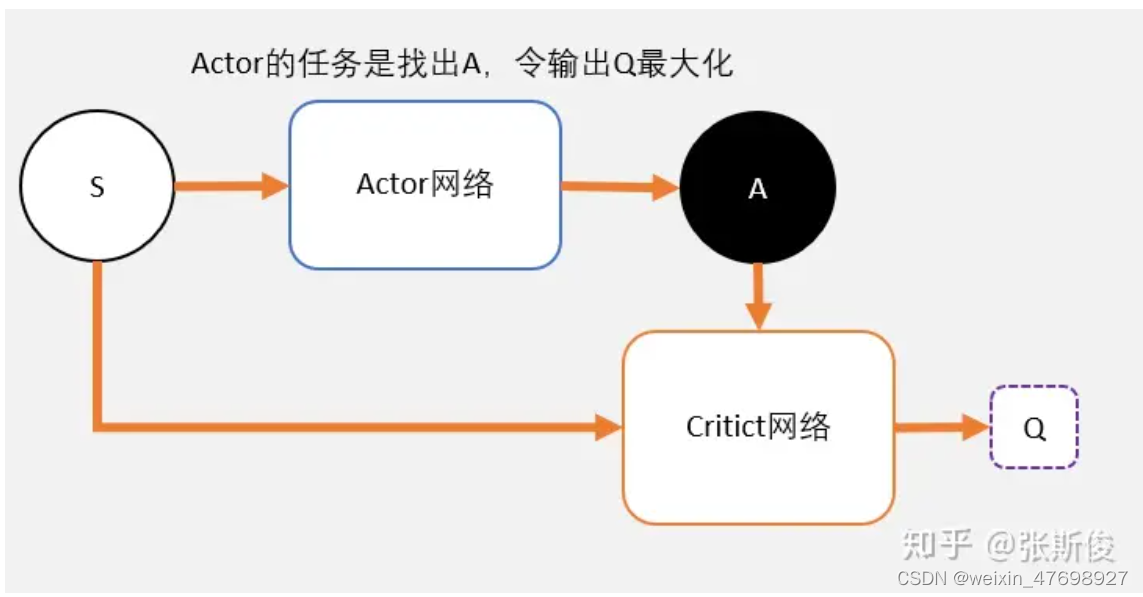
Actor在进行表演,Critic根据Actor的表演打分。Actor通过Critic给出的分数去学习和优化:如果Critic给的分数高,那么Actor会增加这个动作的输出概率;相反,如果Critic给的分数低,那么就减少这个动作输出的概率。那么Actor和Critic网络具体是怎么实现的呢?在这里要首先提到DQN。
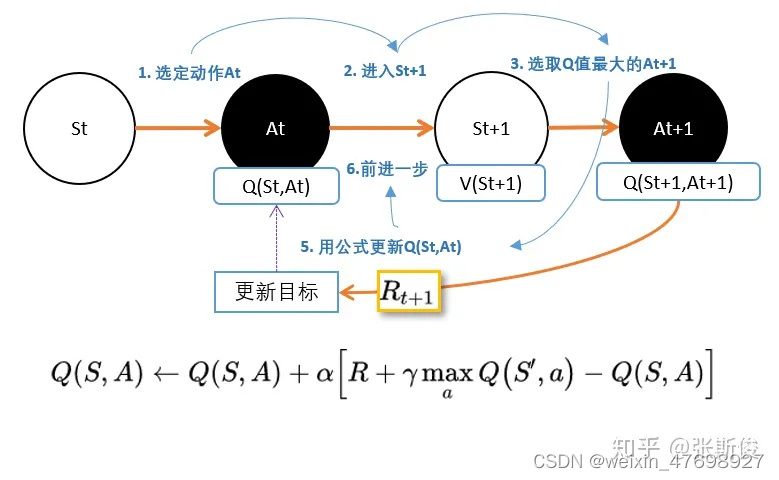
DQN是更新的动作的q值:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







