







目录
1.MADDPG算法简介
MADDPG是多智能体强化学习算法中的经典算法,它使用CTDE框架。
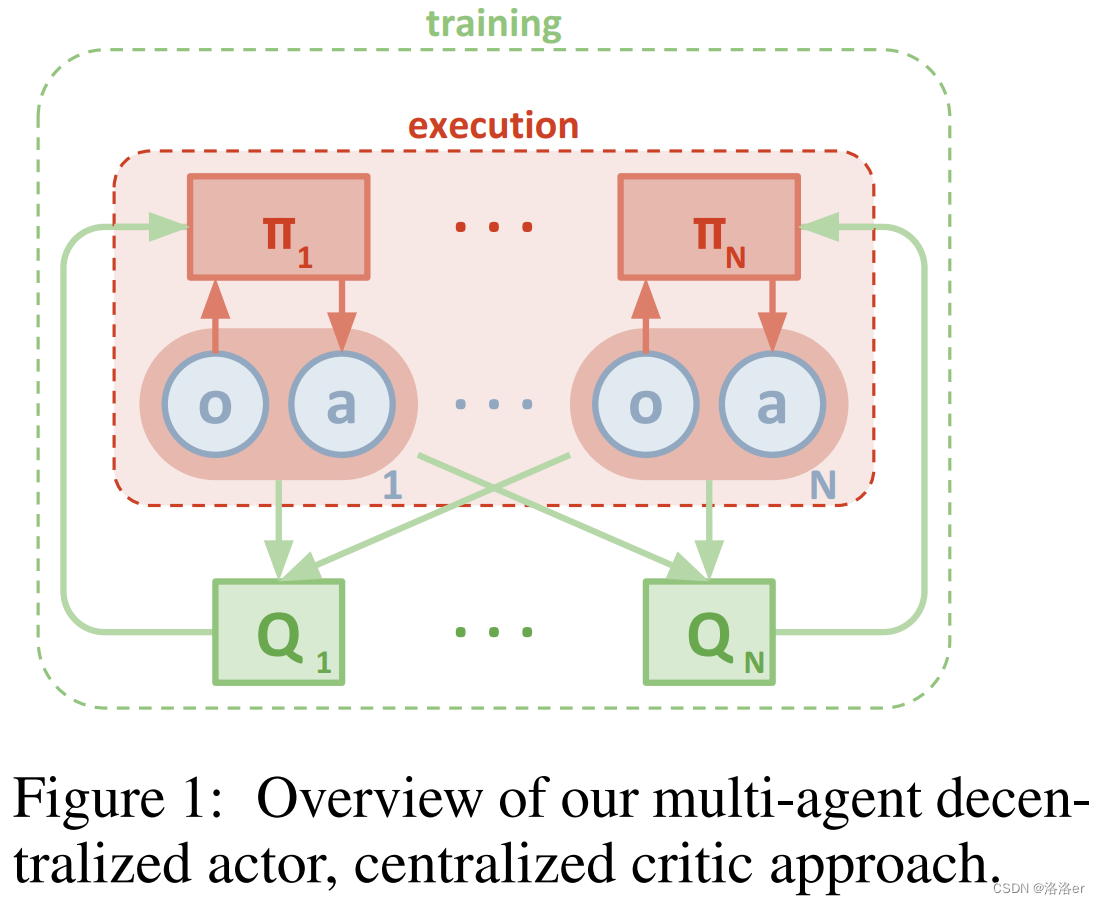
本文从代码实现的角度,解释算法中重要的代码为什么这样写,或许能对MADDPG算法有更深的理解,而不只是停留在看懂论文做实验却无从下手。
但是源码都是tensorflow-v1版本的,理解和调试都比较困难,并且不利于后续作为其他强化学习算法实现的基础,所以我在文章中使用tensorflow-v2版本来实现MADDPG算法,整体而言比源码tensorlfow-v1更好理解。
2.实验环境搭建
Windows11+conda环境
python==3.7tensorflow-gpu==2.5.0tensorflow_tensorflow_probability==1.14.0gym==0.10.0
仿真游戏环境 multiagent-particle-envs
仿真游戏环境github链接,下载到工程文件夹内,在上述建立的conda环境中,cd multiagent-particle-envs使用pip install -e .安装multiagent-particle-envs。
完整的代码见:white-bubbleee/MADDPG-tf2: 使用tensorflow2实现多智能体强化学习算法MADDPG
如果需要pytorch版本的MADDPG算法代码,可以参考white-bubbleee/MADDPG-torch: 使用pytorch实现多智能体强化学习算法MADDPG
3.实验代码
代码分为四个文件:
- maddpg.py 主要算法文件
- distribution.py 其他接口函数定义文件
- args_config.py 参数文件
- train_maddpg.py 训练用的文件
如果只需要运行代码做实验的话,完整的代码链接附在文章的4.实验结果部分,仅供参考。
3.1 maddpg.py
1.导入一些要使用的包以及函数
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.keras.layers import Dense, Input, Concatenate
from tensorflow.keras.models import Model
from base.replaybuffer import ReplayBuffer
from base.trainer import ACAgent, Trainer
import numpy as np
import gym
from ..common.distribution import gen_action_for_discrete, gen_action_for_continuous
from utils.logger import set_logger
logger = set_logger(__name__, output_file="maddpg.log")
DATA_TYPE = tf.float64 # 定义所有tensorflow变量的类型是tf.float64,保证变量类型一致性,否则会出错
2.MADDPG中单个智能体的结构基类
(1)单个智能体的有关参数
- 动作维度
act_dim - 状态(观测维度)
obs_dim - 当前智能体在maddpg所有智能体内的索引
agent_index
超参数部分:
- 智能体网络隐层的大小
num_units - 是否要使用局部q网络,即是否是ddpg
local_q_func
全局参数部分:
- 参数包
args,在train_maddpg.py文件中也是args_list - 全部agent的动作维度参数
action_dim - 全部agent的观测维度参数
obs_dim - 学习率
args.lr
参照openAI,以上这些超参数及其其他有关参数的取值,全部定义在args_config.py 参数文件
(2)单个智能体的有关网络的结构
单个智能体各有四个网络:actor critic target_actor target_critic

actor 的网络结构
根据maddpg算法伪代码展示,仅看圆圈1部分, μ θ i \mu_{\theta_{i}} μθi代表智能体i的actor网络;
显然该actor输入为当前智能体的观测值 o i o_{i} oi,输出为当前智能体的动作值 a i a_{i} ai;
因此,该网络的输入维度是(batch_size, obs_dim),输出维度是(batch_size, act_dim);
或者也可以是(1,obs_dim)===>(1, act_dim);
所以在这里,参照openai的maddpg的源代码,定义actor网络的结构为如下:

最后,定义一个actor创建函数如下:
def build_actor(self, action_bound=None):
obs_input = Input(shape=(self.obs_dim,))
out = Dense(self.num_units, activation='relu')(obs_input)
out = Dense(self.num_units, activation='relu')(out)
out = Dense(self.act_dim, activation=None)(out)
out = tf.cast(out, DATA_TYPE)
actor = Model(inputs=obs_input, outputs=out)
return actor
critic的网络结构
根据maddpg算法伪代码展示,仅看圆圈2部分, Q i μ Q_{i}^{\mu} Qiμ代表智能体i的critic网络;
显然该critic输入为当前智能体的状态值 x i x_{i} xi和所有智能体的联合动作值 a 1 , a 2 , … , a N a_1,a_2, \dots, a_{N} a1,a2,…,aN,输出为当前所有智能体critic网络参数下的 q i q_{i} qi;
论文中关于 x x x的解释如下:

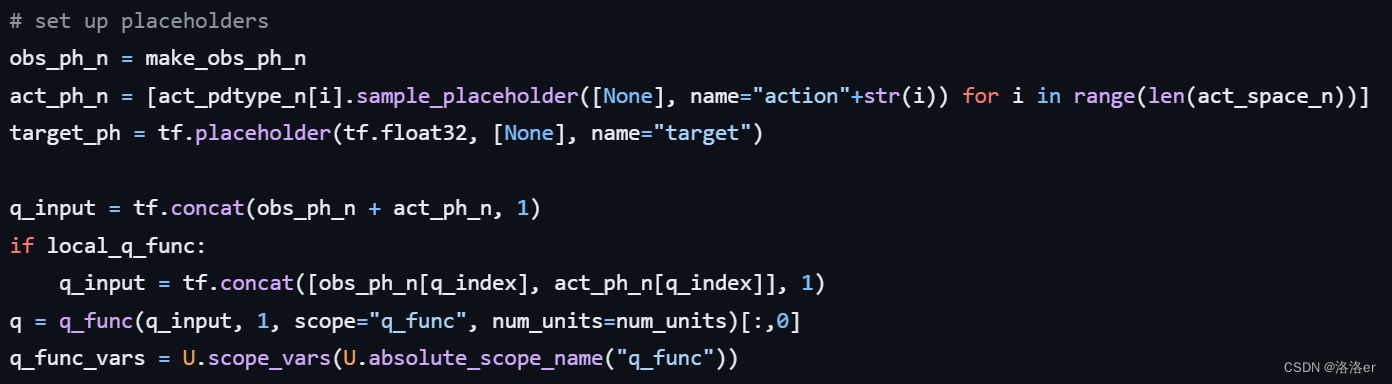

可见,源码中critic的输入形式(maddpg算法)是(batch_size, 所有智能体的obs+所有智能体的act);
因此,我在critic网络中,定义其输入维度是(batch_size, sum(obs_dim)+sum(act_dim)),输出维度是(batch_size, 1)。

最后,定义一个critic创建函数如下:
def build_critic(self):
# ddpg or maddpg
if self.local_q_func: # ddpg,critic的输入是自己的(obs, act)
obs_input = Input(shape=(self.obs_dim,))
act_input = Input(shape=(self.act_dim,))
concatenated = Concatenate(axis=1)([obs_input, act_input])
if not self.local_q_func: # maddpg
obs_input_list = [Input(shape=(self.obs_dim,)) for _ in range(self.nums_agents)]
act_input_list = [Input(shape=(self.act_dim,)) for _ in range(self.nums_agents)]
concatenated_obs = Concatenate(axis=1)(obs_input_list)
concatenated_act = Concatenate(axis=1)(act_input_list)
concatenated = Concatenate(axis=1)([concatenated_obs, concatenated_act])
out = Dense(self.num_units, activation='relu')(concatenated)
out = Dense(self.num_units, activation='relu')(out)
out = Dense(1, activation=None)(out)
out = tf.cast(out, DATA_TYPE)
critic = Model(inputs=obs_input_list + act_input_list if not self.local_q_func else [obs_input, act_input],
outputs=out)
return critic
target_actor和target_critic 和上面两个的结构分别一模一样。
(3)优化器部分
actor网络:self.actor_optimizer = tf.keras.optimizers.Adam(args.lr),学习率args.lr
critic网络:self.critic_optimizer = tf.keras.optimizers.Adam(args.lr), 学习率args.lr
target_actor和target_critic这两个网络的参数不需要被优化,它们的参数分别由actor网络和critic网络的参数来更新得到,因此没有对应的优化器。
(4)MADDPGAgent完整代码
class MADDPGAgent(ACAgent):
def __init__(self, name, action_dim, obs_dim, agent_index, args, local_q_func=False):
super().__init__(name, action_dim, obs_dim, agent_index, args)
self.name = name + "_agent_" + str(agent_index) # 当前智能体的索引,在maddpg中有多个agent
self.act_dim = action_dim[agent_index] # 当前智能体的动作维度
self.obs_dim = obs_dim[agent_index][0] # 当前智能体的观测维度
self.act_total = sum(action_dim)
self.obs_total = sum([obs_dim[i][0] for i in range(len(obs_dim))])
self.num_units = args.num_units
self.local_q_func = local_q_func
self.nums_agents = len(action_dim)
self.actor = self.build_actor()
self.critic = self.build_critic()
self.target_actor = self.build_actor()
self.target_critic = self.build_critic()
self.actor_optimizer = tf.keras.optimizers.Adam(args.lr)
self.critic_optimizer = tf.keras.optimizers.Adam(args.lr)
def build_actor(self, action_bound=None):
obs_input = Input(shape=(self.obs_dim,))
out = Dense(self.num_units, activation='relu')(obs_input)
out = Dense(self.num_units, activation='relu')(out)
out = Dense(self.act_dim, activation=None)(out)
out = tf.cast(out, DATA_TYPE)
actor = Model(inputs 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









