






 本文深入探讨了深度强化学习中的Q学习算法。通过建立Q_eval和target_model两个模型,阐述了如何从当前状态选择最佳行动并预测未来奖励。Q值代表当前状态采取特定行动的潜在价值,而max(Q_target)表示对未来可能的最大奖励的估计。通过结合即时奖励R和未来奖励的预期,模型进行训练以优化决策过程。
本文深入探讨了深度强化学习中的Q学习算法。通过建立Q_eval和target_model两个模型,阐述了如何从当前状态选择最佳行动并预测未来奖励。Q值代表当前状态采取特定行动的潜在价值,而max(Q_target)表示对未来可能的最大奖励的估计。通过结合即时奖励R和未来奖励的预期,模型进行训练以优化决策过程。
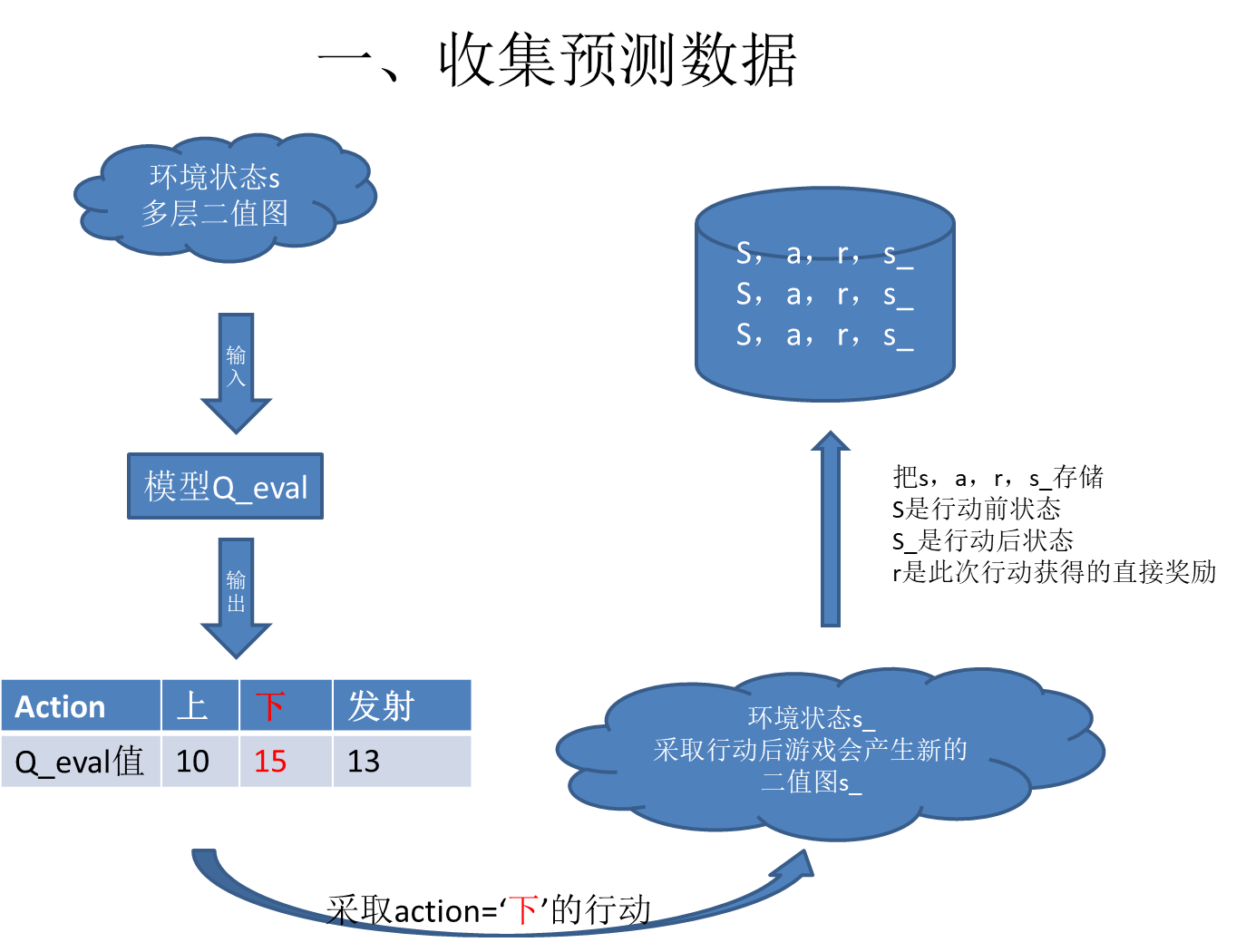
1、先建立模型Q_eval,随机初始化
2、让图像二值化为状态State,作为模型输入,假定模型输出3个Q值(Q就是衡量该行为的价值,Q最大就采用这个行为Act)该图Act=‘下’
3、状态State 在Act行为下,产生新状态S_,这时你根据游戏形势给他一个奖励Reward
简化为(State,Act,Reward,State_)即(s,a,r,s_)
4、保存(s,a,r,s_)

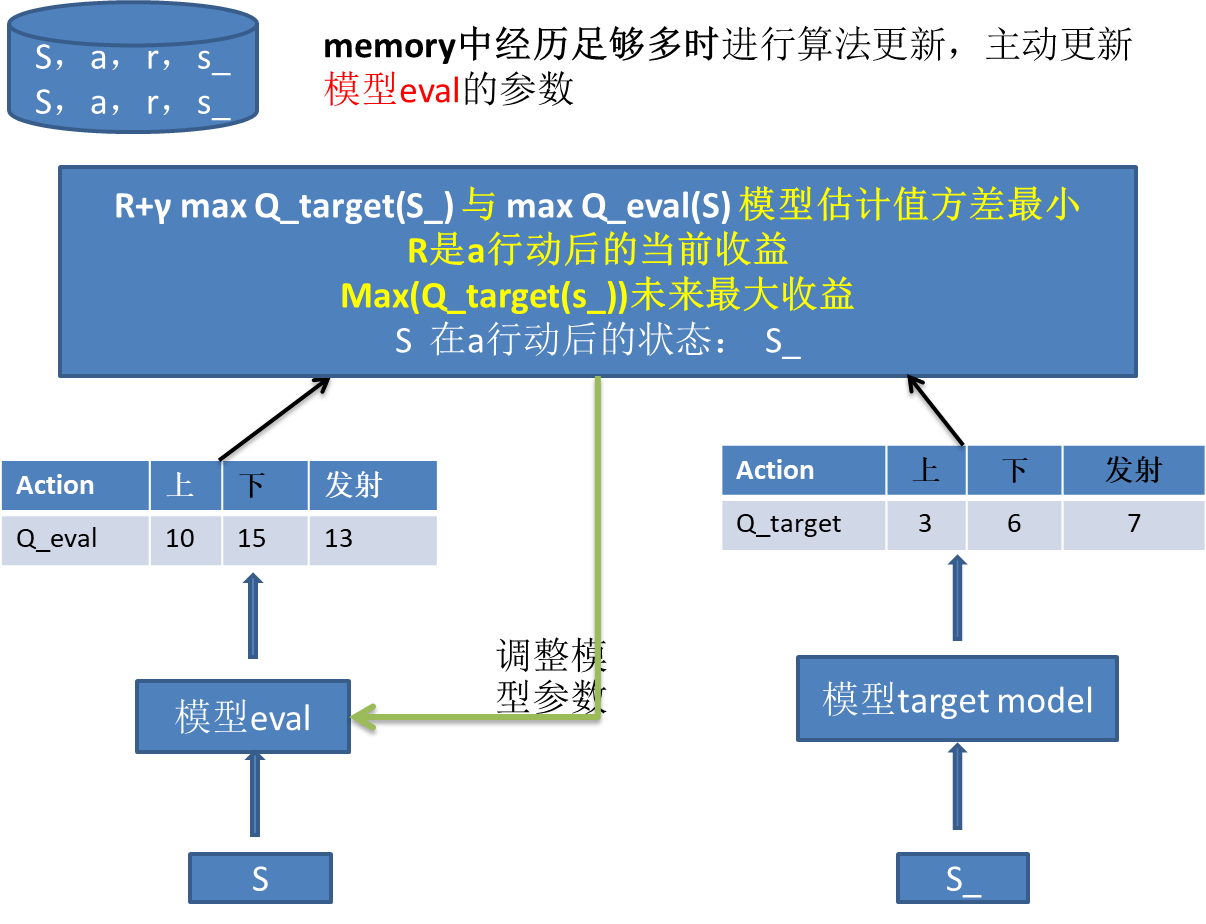
1、再建立一个模型target_model,与模型eval一样,这个模型参数更新比较慢。
2、S_输入模型target,用来计算未来的价值Q值。(为何是未来的Q值呢?类似递归)
该图就是Q_target =【3,6,9】,用哪个值呢?用最大的9 。 也就是max(Q_target)
3、然后R+max(Q_target)作为输出目标,即:
S- --> R+max(Q_target) 也就是 状态S对应 R(当前奖励)+0.8*max(Q_target)(未来奖励)
用这个训练模型eval。
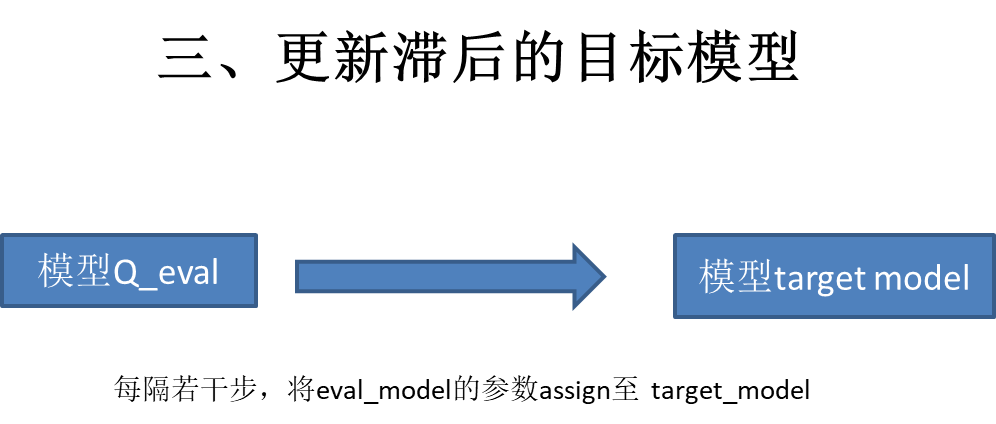
--------------------------------
关键理解:为何当前状态S 采用A 行动价值为 R+0.8*max(Q_target)
R是你给他的奖励,由编程者决定
max(Q_target)为何是未来的奖励?
因为他是S后面的状态S_输入的输出,也就是下一步可能的奖励,S_后面还有3个Act,我们应该会选择价值最高的那个行动。因此S的价值就是 R+0.8*max(Q_target),未来确定性还不好说乘个系数0.8
模型Q_eval的输出Q值,Q值理解就是当前状态S,采取Act行动的最大价值(也就是奖励)
Q=Q_eval模型(S) =【10,15,13】 Q(A)=15就是当前A=‘下’行为的价值
Q=Q_target模型(S_)=【3,6,9】 max(Q)=9可以理解为未来采用适当行为有可能得到的最大价值


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









