







1.数据结构知识
1.1算法复杂度分析
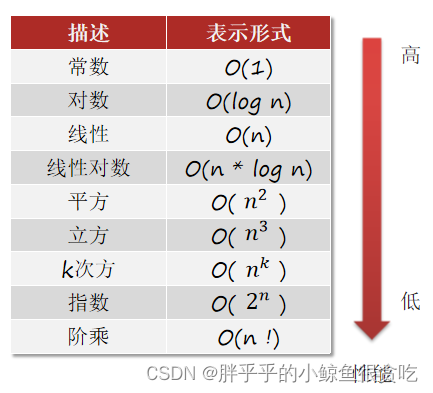
(1)时间复杂度:随着数据规模的增加,运行代码需要的时间变化。
大O表示法;
常见时间复杂度表示形式:
(2)空间复杂度:随着数据规模的增加,运行代码需要的内存空间变化。
1.2数据结构
(1)数组
1.描述:物理上是一片连续的存储空间,存储同一数据类型的一种数据结构。
2.下标从0开始
(1)寻址公式;如果从1开始会多一个cpu执行指令;
arr[i] = baseAddress + i * dataTypeSize
(2)链表
- 链表中的每一个元素称为节点(node)
- 物理存储上非连续的存储结构;
- 单向链表和双向链表
(3)哈希表
- 散列表(Hash Table)又名哈希表/Hash表,是根据键(Key)直接访问在内存存储位置值(Value)的数据结构,它是由数组演化而来的,利用了数组支持按照下标进行随机访问数据的特性。
- 哈希函数:计算key对应在hash表中的位置;
- 哈希碰撞:多个key对应哈希表中的一个槽位;
- 解决哈希碰撞的方式:拉链法(每个hash槽对应一个链表或红黑树,最后遍历找到对应的值。)
(4)树
1.二叉树:每个节点最多有两个分叉(左子树和右子树),每个分叉最多有两个节点。
2.二叉查找树:在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值;
3.红黑树:为了防止二叉树退化为链表的这种极端情况;
2.集合体系结构
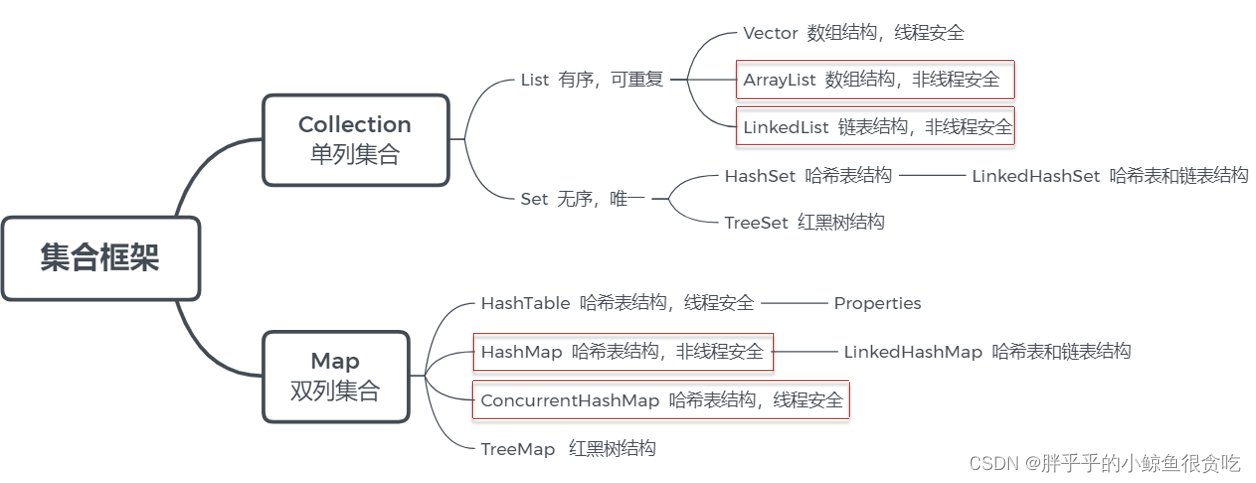
2.1list系列
(1)ArrayList
/**
* 默认初始的容量(CAPACITY)
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 用于空实例的共享空数组实例
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 用于默认大小的空实例的共享空数组实例。
* 我们将其与 EMPTY_ELEMENTDATA 区分开来,以了解添加第一个元素时要膨胀多少
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 存储 ArrayList 元素的数组缓冲区。 ArrayList 的容量就是这个数组缓冲区的长度。
* 当添加第一个元素时,任何具有 elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA 的空 ArrayList * 都将扩展为 DEFAULT_CAPACITY
* 当前对象不参与序列化
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList 的大小(它包含的元素数量)
* @serial
*/
private int size;

1.源码分析
2.底层原理:
(1)通过动态数组来实现的;
(2)初始容量:在没有指定长度的情况下初始容量为0,只有第一次添加数据的时候,初始容量为10;
比如:ArrayList list=new ArrayList(10)没有进行扩容;
(3)扩容机制:扩容的的时候是原来的1.5倍,每一次都需要数组拷贝;
3.添加逻辑:
(1)确保数组已使用长度+1能够存的下下一个数据;
(2)如果+1之后存不下,则进行扩容;
扩容逻辑:grow方法,扩容为原来的1.5倍,进行数组拷贝;
(3)将数据添加到size的位置上;
4.数组和集合转换:
(1)Arrays.asList转换list之后,如果修改了数组的内容,list会受影响,因为它的底层使用的Arrays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个内存地址。
(2)list用了toArray转数组后,如果修改了list内容,数组不会影响,当调用了toArray以后,在底层是它是进行了数组的拷贝,跟原来的元素就没啥关系了,所以即使list修改了以后,数组也不受影响。
(2)LinkedList
1.底层结构:双向链表;
2.ArrayList和LinkedList的区别:
- 底层结构
- 操作效率
- 所占内存
- 线程安全:都不是线性安全的;如果想要保证线性安全性(在方法内部使用;操作加锁)
2.2map系列
(1)hashMap的实现原理
HashMap的底层是使用hash表的数据结构来存储,即数组或者红黑树。
- 当我们往里面put元素的时候,利用key进行hash计算得到对应hash表中的位置;
- 存储时:如果key相同,则覆盖掉原始值;key不同(出现了冲突)则将数据放入链表或者红黑树中。
- 获取时:对key进行hash计算,找到对应的下标,然后再进行比较,从而找到对应的值;
JDK1.7和JDK1.8中,HashMap的区别:
- DK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
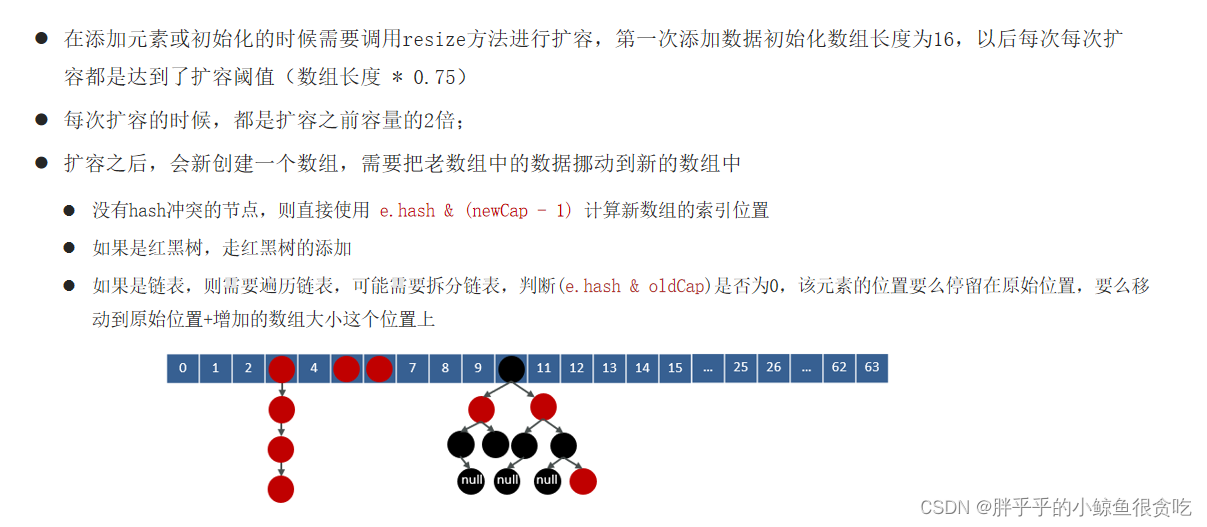
- jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
(2)hashMap中put方法的具体流程

扩容阈值 == 数组容量 * 加载因子
A.加载方式
HashMap是懒惰加载,在创建对象时并没有初始化数组;
在无参的构造函数中,设置了默认的加载因子是0.75;
B.put方法的具体流程
1. 判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
2. 根据键值key计算hash值得到数组索引
3. 判断table[i]==null,条件成立,直接新建节点添加
4. 如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据。然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作。遍历过程中若发现key已经存在直接覆盖value 5. 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
(3)hashMap的寻址算法
HashMap的寻址算法
计算对象的 hashCode() 再进行调用 hash() 方法进行二次哈希, hashcode值右移16位再异或运算,让哈希分布更为均匀 最后 (capacity – 1) & hash 得到索引
为什么hashMap的数组长度一定是2的次幂
1. 计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模 2. 扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
(4)hashMap的扩容机制
(5)hashMap在1.7情况下的多线程死循环问题
(6)HashSet和HashMap的泣别
1. HashMap实现了Map接口,HashSet实现了Set接口
2. HashMap用于存储键值对,而HashSet用于存储对象。
3.HashMap不允许有重复的键,可以允许有重复的值。HashSet不允许有重复元素。
4.HashMap允许有一个键为空,多个值为空,HashSet允许有一个空值。
5.HashMap中使用put()将元素加入map中,而HashSet使用add()将元素放入set中。
6.HashMap比较快,因为其使用唯一的键来获取对象。
(7)HashTable和HashMap的区别
1、两者父类不同
- HashMap是继承自AbstractMap类;
- Hashtable是继承自Dictionary类。
- 不过它们都实现了同时 实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
2、对外提供的接口不同
Hashtable比HashMap多提供了elments() 和contains() 两个方法。elements() 方法用于返回此Hashtable中的value的枚举。 contains()方法判断该Hashtable是否包含传入的value。3、对null的支持不同
- Hashtable:key和value都不能为null。
- HashMap:key可以为null,但是这样的key只能有一个,因为必须保证key的唯一性;可以有多个 key值对应的value为null。
4、安全性不同
- HashMap是线程不安全的,在多线程并发的环境下,可能会产生死锁等问题,因此需要开发人员自 己处理多线程的安全问题。
- Hashtable是线程安全的,它的每个方法上都有synchronized 关键字,因此可直接用于多线程中。 虽然HashMap是线程不安全的,但是它的效率远远高于Hashtable,这样设计是合理的,因为大部 分的使用场景都是单线程。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。 ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为 ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。

















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









