






前言
我在翻看源码一段时间后,对past_key_value稍微有了一点点了解,现在我回来吧这个东西补充上,来获取速度更快的qwen大模型推理!
同样的对话
这是没有用到

这是用了past_key_value的token速度
看最后一个数字,这速度提升,令人感到愉悦
past_key_value做了什么?
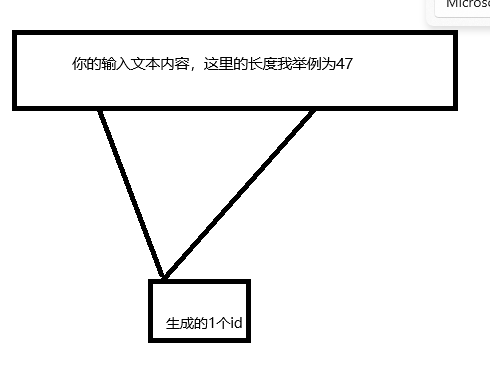
首先,大模型的底还是rnn模型,既输入一段字(这里举列,输入内容生成的ids),然后结合先前的内容,再输出下一个字,再结合先前的内容输出下一个字,如下图
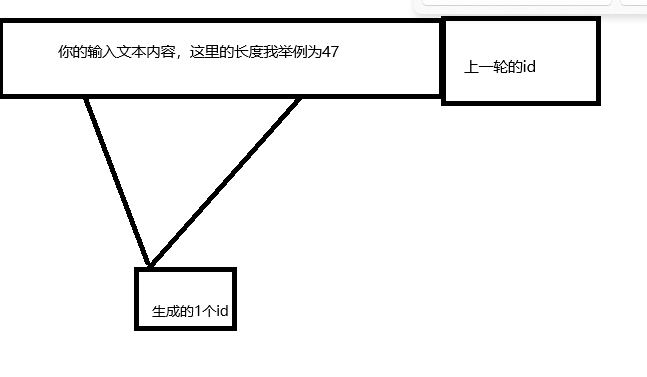
然后,大模型将生成的新的id合并到原本输入文本内容中,再次跑,再次生成一个新的id,再次跑再次生成一个id。。。如下图
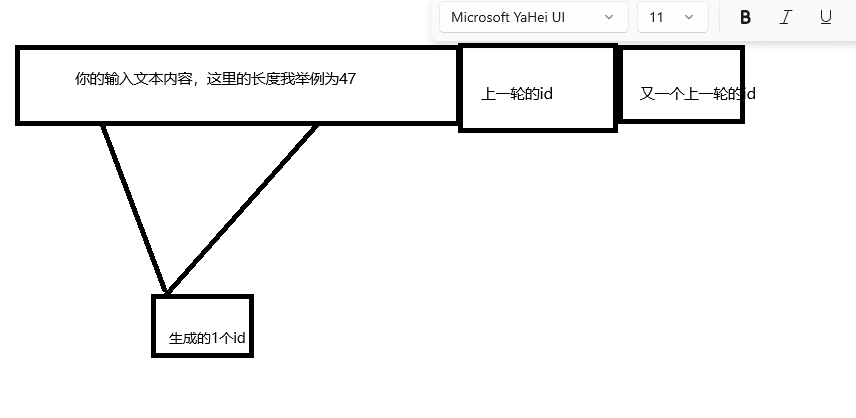
直到达到结束生成器的判定条件,以qwen2为例子,是输入内容为结束标识符,或者达到最大长度。
而这个模型,在运行过程中,会有大量的注意力机制在运行,可以理解成,每次运行时,如果你的decoder层有24个(qwen2 0.5b的数量),那么你的模型就要重复的去跑这些decoder层·,但其实这些层的结果,有一些是不需要反复运行的,如每一个decoder层中都会有一个attention层
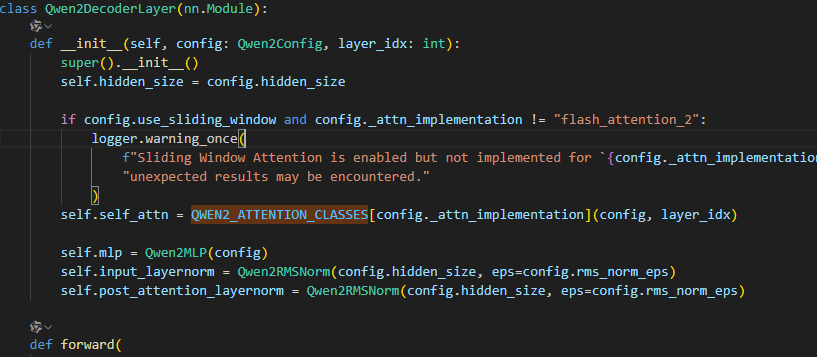
这个attention层中,k和v是可以被缓存的,这样可以节约大量的decoder使用attention时的计算量。
而Q不缓存,是因为Q具有一定的不稳定性,Q向量是由当前的输入生成的,每次生成新的token时,其对应的Q向量都会变化。如果缓存Q向量,由于其不断变化的特性,会导致缓存需要频繁更新,这不仅增加了计算成本,还可能抵消缓存带来的好处。
而K和V的稳定性:相比之下,K和V向量通常是由编码器部分的输出计算得出的,对于给定的输入序列,它们的值相对稳定。
代码变更,导出past_key_values
首先,先前我们导出的没有past_key_values的模型,是关闭了use_cache的,现在我们需要重新打开这个参数,找到Qwen2Model的推理层,将use_cache修改为默认true
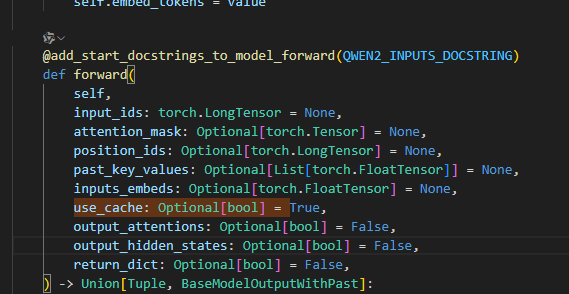
然后,修改Qwen2Model和Qwen2ForCausalLM的输出层,这里我为了安逸,从外界传入一个值控制这里的输出内容。
Qwen2Model只要hidden_status和next_cache
截图
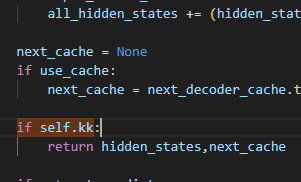
代码
#这个kk是我从外面传入的控制器
if self.kk:
return hidden_states,next_cache
Qwen2ForCausalLM则只要logits和上面qwen2model输出的next_cache。这里注意,需要对next_cache做一些处理,不然导出模型时会很难看
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
logits = self.lm_head(hidden_states)
logits = logits.float()
if(self.kk):
o_past_key_values= outputs[1]
#通过这个处理,将_past_key_values从一个对象变成一个pytorch数组,如果不这么做,最后导出模型的时候,会出现导出一堆的输出层,这样可以只有一个输出层
opkv = torch.stack([torch.stack(row) for row in o_past_key_values])
return logits,opkv
导出这个模型,我们这里生成一个dim为0的input,以防止在onnx模型导出时,出现什么变故
def build_cache_random(model):
num_hidden_layers = model.base_model.num_hidden_layers
kvszie = 2
# 1,2,?,64
qvshape = [1,2,0,64]
return np.ones([num_hidden_layers,kvszie]+qvshape)
input_names = ["input_ids","attention_mask","position_ids"]
input_names.append("past_key_values")
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
input_ids = model_inputs.data['input_ids']
attention_mask = model_inputs.data['attention_mask']
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)
past_key_values =torch.from_numpy( build_cache_random(model)).to("cuda:0").to(torch.float32)
output_names = ["last_hidden_state"]
output_names .append( "past_key_values")
torch.onnx.export(outmodel, (input_ids,attention_mask,position_ids,past_key_values) ,input_names=input_names ,output_names=output_names , f="./onnx/model32.onnx" ,dynamic_axes={'input_ids':[1],'attention_mask':[1],'position_ids':[1],'last_hidden_state':[1],'past_key_values':[4]},opset_version=18)
运行代码变更,添加past_key_values
然后,我们吧上次改的代码中的运行部分稍作变更,将输出部分的下标1的past_key_values再重新输入到下次模型运行过程,这样整个流程就算结束了.代码如下
这里修改先前的runForCausalLM方法
# 这里模拟ForCausalLM方法
def runForCausalLM(self ,input_ids,past_key_values=None):
inputs = self.prepare_inputs_for_generation(input_ids,None,None,past_key_values,None)
inputs = {"input_ids": inputs['input_ids'],"attention_mask":inputs["attention_mask"],"position_ids":inputs["position_ids"],"past_key_values.1":inputs["past_key_values"]}
output_names = [output.name for output in self.model.get_outputs()]
outputs=self.model.run(output_names,inputs)
return outputs
然后,只需要对base运行类做出简单修改就好了
def prepare_inputs_for_generation(self, input_ids,position_ids=None, attention_mask=None, past_key_values=None, inputs_embeds=None):
if attention_mask is None:
attention_mask = np.ones_like(input_ids,dtype=np.int64)
if(past_key_values is None):
past_length = 0
else:
past_length = past_key_values[0][0].shape[2]
def generate(self,input_ids,stream=None,tokenizer = None):
....
past_key_values = None
while(not this_peer_finished):
outputs = self.runForCausalLM(input_ids,past_key_values)
logits = outputs[0].astype(np.float32)
....
针对上次的代码做出以上变更后,就可以得到速度超大幅度提升的qwen2大模型了!
下一步计划?
我以前以为,qwen大模型的大体推理逻辑大差不差,但前段时间试着导出qwen2-math时,撞墙了,似乎有些许不同,接下来要多看看qwen2大模型的实现细节,以及如果内容超长了,如何通过继续输出的命令,来让大模型一直推理。此外,目前的大模型导出都是用的float32,导致体积奇大无比,下一步必须要考虑如何量化我的模型,不然这么大的体积,到7b那亏啊,我不是炸了吗


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









