






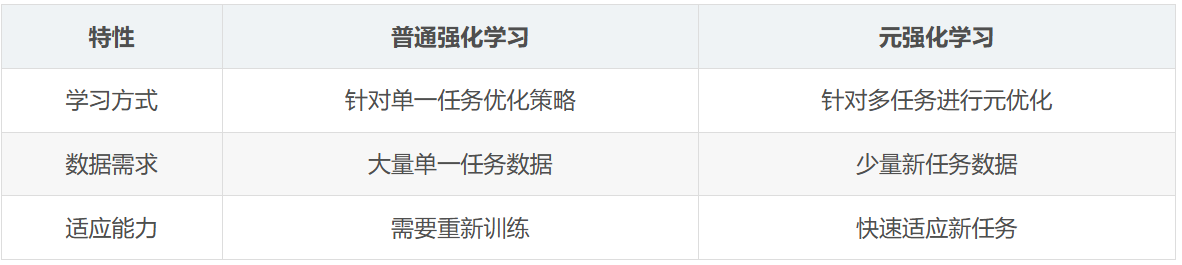
什么是元学习?
元学习,又称“学习的学习”,是一种让机器在不同任务之间快速适应和泛化的学习方式。传统机器学习模型通常需要大量数据进行训练,并且在遇到新任务时需要重新训练,而元学习的目标是通过在一系列不同但相关的任务上进行训练,使模型能够快速适应新任务。
元学习分为三大类:
基于优化的元学习:学习一种优化算法,使模型能够在新任务上快速优化。
基于模型的元学习:学习模型本身的结构和动态,使其在少量任务数据下快速调整。
基于元表示的元学习:学习适应新任务所需的表示,这通常涉及特征提取。
元学习的应用
元学习在以下领域中有着广泛应用:
强化学习任务的泛化
少样本学习(Few-shot Learning)
多任务学习(Multi-task Learning)
什么是元强化学习
元强化学习结合了元学习和强化学习的概念,目标是构建一种能够在不同任务之间迅速适应的强化学习算法。在标准的强化学习任务中,算法往往只专注于单一任务,而元强化学习希望通过在一系列不同任务上进行训练,使得模型能够快速适应新的任务,类似于人类的学习方式。简言之,元强化学习是“学会如何学习”,强化学习则是“学会策略”。
元强化学习的工作原理主要包括以下几个阶段:
任务分布:元强化学习从一组任务分布中抽取多个任务进行训练。
内层优化:对于每个任务,训练一个特定的强化学习策略。
外层优化:通过比较不同任务的表现,调整整体的模型参数,使得其在新任务上能够快速适应。
元强化学习与普通强化学习的区别
元强化学习的主要算法
1、基于梯度的元强化学习算法
MAML(Model-Agnostic Meta-Learning)
- 核心思想:通过训练初始参数,使得模型在新的任务上能够通过少量的梯度更新快速适应。
- 算法流程:
- 任务采样:从任务分布中随机采样任务。
- 任务内更新:对每个任务,基于初始参数执行几步梯度更新,得到新任务的优化参数。
- 元更新:通过多个任务的损失值,更新初始参数,使其在新任务上表现良好。
代码样例
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import gym
import matplotlib.pyplot as plt
import time
from collections import deque
# 定义策略网络
class PolicyNetwork(nn.Module):
def __init__(self, input_size, output_size, hidden_size=128):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.softmax(self.fc2(x), dim=-1)
return x
def get_action_probs(self, state):
if isinstance(state, tuple):
state = state[0]
state = torch.FloatTensor(state).unsqueeze(0)
return self(state)
# 包装环境以跟踪episode奖励
class EpisodeRewardWrapper(gym.Wrapper):
def __init__(self, env):
super().__init__(env)
self.episode_reward = 0
def reset(self, **kwargs):
self.episode_reward = 0
return self.env.reset(**kwargs)
def step(self, action):
state, reward, done, _, info = self.env.step(action)
self.episode_reward += reward
return state, reward, done, info
# MAML 训练过程
def maml_train(env_name="CartPole-v1", num_tasks=5, num_iterations=100,
meta_lr=0.01, inner_lr=0.1, inner_steps=5,
gamma=0.95, horizon=200, eval_freq=10):
#meta_lr 指定元学习率,用于元优化器的更新步骤。元学习率控制元参数(即模型的初始参数)在每次元更新时的调整幅度。
#inner_lr 指定内部学习率,用于在每个任务上的适应步骤。内部学习率控制模型参数在单个任务上的快速适应。
#inner_lr 指定在每个任务上进行内部适应的步骤数。即在每个任务上,模型会使用内部学习率进行多少次的参数更新。
#horizon 指定每个episode的最大步数
#eval_freq 指定评估策略的频率。即在每10个元训练迭代后,评估当前策略在测试环境上的性能。
# 创建多个环境并包装
envs = [EpisodeRewardWrapper(gym.make(env_name)) for _ in range(num_tasks)]
test_env = EpisodeRewardWrapper(gym.make(env_name))
# 初始化策略网络
input_size = envs[0].observation_space.shape[0]
output_size = envs[0].action_space.n
policy = PolicyNetwork(input_size, output_size)
meta_optimizer = optim.Adam(policy.parameters(), lr=meta_lr)
# 用于记录训练过程中的奖励
train_rewards = []
test_rewards = []
for iteration in range(num_iterations):
# 用于存储每个任务的适应后参数
adapted_policies = []
# 内循环:在每个任务上进行适应
for env in envs:
# 克隆原始策略
adapted_policy = PolicyNetwork(input_size, output_size)
adapted_policy.load_state_dict(policy.state_dict())
inner_optimizer = optim.SGD(adapted_policy.parameters(), lr=inner_lr)
# 在任务上进行几步训练
state = env.reset()
for _ in range(inner_steps):
if isinstance(state, tuple):
state = state[0]
# 获取动作概率
action_probs = adapted_policy.get_action_probs(state)
action = np.random.choice(len(action_probs[0]), p=action_probs[0].detach().numpy())
# 执行动作
next_state, reward, done, _ = env.step(action)
# 计算损失(策略梯度)
loss = -torch.log(action_probs[0, action]) * reward
# 更新参数
inner_optimizer.zero_grad()
loss.backward()
inner_optimizer.step()
state = next_state
if done:
break
# 保存适应后的策略
adapted_policies.append(adapted_policy)
# 外循环:元更新
meta_loss = 0
meta_optimizer.zero_grad()
for i, adapted_policy in enumerate(adapted_policies):
# 在每个任务上评估适应后的策略
env = envs[i]
state = env.reset()
episode_reward = 0
for _ in range(horizon):
if isinstance(state, tuple):
state = state[0]
# 获取动作概率
action_probs = adapted_policy.get_action_probs(state)
action = np.argmax(action_probs[0].detach().numpy())
# 执行动作
next_state, reward, done, _ = env.step(action)
episode_reward += reward
state = next_state
if done:
break
# 计算元梯度
# 这里我们使用适应后的策略与原始策略的参数差作为梯度
for param, adapted_param in zip(policy.parameters(), adapted_policy.parameters()):
if param.grad is None:
param.grad = torch.zeros_like(param)
param.grad.data += (adapted_param.data - param.data) / num_tasks
# 更新元参数
meta_optimizer.step() #优化器在调用 optimizer.step() 时,会使用 param.grad 中的值来更新参数。
# 记录训练奖励(使用包装器中的episode_reward)
train_rewards.append(np.mean([env.episode_reward for env in envs]))
# 定期评估策略
if iteration % eval_freq == 0 or iteration == num_iterations - 1:
test_reward = evaluate_policy(policy, test_env, horizon)
test_rewards.append(test_reward)
print(f"Iteration {iteration}, Train Reward: {train_rewards[-1]:.2f}, Test Reward: {test_reward:.2f}")
# 绘制学习曲线
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_rewards, label='Training Reward')
plt.xlabel('Iteration')
plt.ylabel('Reward')
plt.title('Training Reward Over Iterations')
plt.subplot(1, 2, 2)
plt.plot(test_rewards, label='Test Reward', color='orange')
plt.xlabel('Iteration')
plt.ylabel('Reward')
plt.title('Test Reward Over Iterations')
plt.tight_layout()
plt.show()
return policy
def evaluate_policy(policy, env, horizon=200):
state = env.reset()
episode_reward = 0
done = False
for _ in range(horizon):
action_probs = policy.get_action_probs(state)
action = np.argmax(action_probs[0].detach().numpy())
state, reward, done, _ = env.step(action)
episode_reward += reward
if done:
break
return episode_reward
# 训练 MAML 算法
start_time = time.time()
trained_policy = maml_train(env_name="CartPole-v1",
num_tasks=5,
num_iterations=500,
meta_lr=0.01,
inner_lr=0.1,
inner_steps=10,
gamma=0.95,
horizon=200,
eval_freq=10)
end_time = time.time()
cost_time = end_time - start_time
print(f"Training completed in {round(cost_time, 2)} seconds")
运行效果
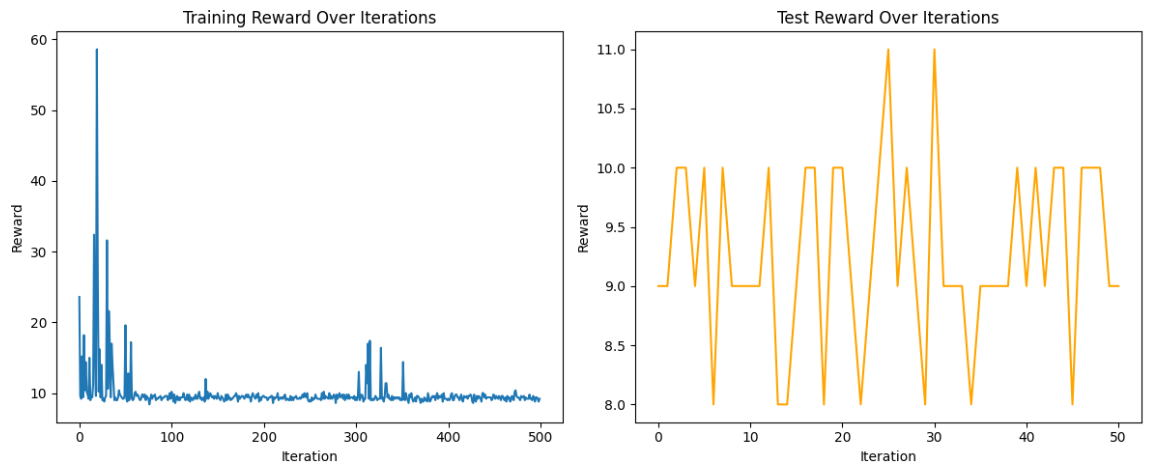
优点:
- 快速适应新任务:通过少量梯度更新实现策略调整,适用于需要快速适应的场景。
- 模型无关性:可与各种机器学习模型结合,应用范围广。
- 缺点:
- 对任务分布敏感:在训练任务与新任务分布差异大时,性能下降显著。
- 计算成本高:需大量数据进行迭代更新,对计算资源要求高。
- 超参数敏感:学习率、迭代次数等超参数对性能影响大,需仔细调整。
- 应用场景:
- 小样本学习:如快速适应新类别的分类任务。
- 机器人策略调整:在少量试错中优化机械臂抓取策略。
MAESN(Meta-Reinforcement Learning of Structured Exploration Strategies)
- 核心思想:在MAML的基础上,在策略的输入部分增加了一个隐层特征作为随机噪声,提供时间上较为连续的随机探索,有利于智能体根据当前任务的MDP调整其整体的策略探索。
- 实现代码
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import gym
import matplotlib.pyplot as plt
import time
from collections import deque
# 定义策略网络
class PolicyNetwork(nn.Module):
def __init__(self, input_size, output_size, hidden_size=128):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.softmax(self.fc2(x), dim=-1)
return x
def get_action_probs(self, state, noise=None):
if isinstance(state, tuple):
state = state[0]
state = torch.FloatTensor(state).unsqueeze(0)
if noise is not None:
state = torch.cat([state, noise], dim=-1)
return self(state)
# 定义噪声生成网络
class NoiseNetwork(nn.Module):
def __init__(self, input_size, noise_size, hidden_size=64):
super(NoiseNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, noise_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.tanh(self.fc2(x))
return x
# 包装环境以跟踪episode奖励
class EpisodeRewardWrapper(gym.Wrapper):
def __init__(self, env):
super().__init__(env)
self.episode_reward = 0
def reset(self, **kwargs):
self.episode_reward = 0
return self.env.reset(**kwargs)
def step(self, action):
state, reward, done, _, info = self.env.step(action)
self.episode_reward += reward
return state, reward, done, info
# MAESN 训练过程
def maesn_train(env_name="CartPole-v1", num_tasks=5, num_iterations=100,
meta_lr=0.01, inner_lr=0.1, inner_steps=5,
gamma=0.95, horizon=200, eval_freq=10, noise_size=10):
# 创建多个环境并包装
envs = [EpisodeRewardWrapper(gym.make(env_name)) for _ in range(num_tasks)]
test_env = EpisodeRewardWrapper(gym.make(env_name))
# 初始化策略网络和噪声网络
input_size = envs[0].observation_space.shape[0] + noise_size
output_size = envs[0].action_space.n
policy = PolicyNetwork(input_size, output_size)
noise_network = NoiseNetwork(envs[0].observation_space.shape[0], noise_size)
meta_optimizer = optim.Adam(list(policy.parameters()) + list(noise_network.parameters()), lr=meta_lr)
# 用于记录训练过程中的奖励
train_rewards = []
test_rewards = []
for iteration in range(num_iterations):
# 用于存储每个任务的适应后参数
adapted_policies = []
adapted_noise_networks = []
# 内循环:在每个任务上进行适应
for env in envs:
# 克隆原始策略和噪声网络
adapted_policy = PolicyNetwork(input_size, output_size)
adapted_policy.load_state_dict(policy.state_dict())
adapted_noise_network = NoiseNetwork(envs[0].observation_space.shape[0], noise_size)
adapted_noise_network.load_state_dict(noise_network.state_dict())
inner_optimizer = optim.SGD(list(adapted_policy.parameters()) + list(adapted_noise_network.parameters()),
lr=inner_lr)
# 在任务上进行几步训练
state = env.reset()
for _ in range(inner_steps):
if isinstance(state, tuple):
state = state[0]
# 生成噪声,在噪声网络的输入中添加随机噪声
noise_input = torch.FloatTensor(state).unsqueeze(0) + torch.randn_like(torch.FloatTensor(state).unsqueeze(0)) * 0.1
noise = adapted_noise_network(noise_input)
# 对噪声网络的输出进行随机缩放
noise = noise * (torch.rand(1) + 0.5)
# 获取动作概率
action_probs = adapted_policy.get_action_probs(state, noise)
action = np.random.choice(len(action_probs[0]), p=action_probs[0].detach().numpy())
# 执行动作
next_state, reward, done, _ = env.step(action)
# 计算损失(策略梯度)
loss = -torch.log(action_probs[0, action]) * reward
# 更新参数
inner_optimizer.zero_grad()
loss.backward()
inner_optimizer.step()
state = next_state
if done:
break
# 保存适应后的策略和噪声网络
adapted_policies.append(adapted_policy)
adapted_noise_networks.append(adapted_noise_network)
# 外循环:元更新
meta_loss = 0
meta_optimizer.zero_grad()
for i, (adapted_policy, adapted_noise_network) in enumerate(
zip(adapted_policies, adapted_noise_networks)):
# 在每个任务上评估适应后的策略
env = envs[i]
state = env.reset()
episode_reward = 0
for _ in range(horizon):
if isinstance(state, tuple):
state = state[0]
# 生成噪声
noise_input = torch.FloatTensor(state).unsqueeze(0) + torch.randn_like(torch.FloatTensor(state).unsqueeze(0)) * 0.1
noise = adapted_noise_network(noise_input)
noise = noise * (torch.rand(1) + 0.5)
# 获取动作概率
action_probs = adapted_policy.get_action_probs(state, noise)
action = np.argmax(action_probs[0].detach().numpy())
# 执行动作
next_state, reward, done, _ = env.step(action)
episode_reward += reward
state = next_state
if done:
break
# 计算元梯度
# 这里我们使用适应后的策略与原始策略的参数差作为梯度
for param, adapted_param in zip(policy.parameters(), adapted_policy.parameters()):
if param.grad is None:
param.grad = torch.zeros_like(param)
param.grad.data += (adapted_param.data - param.data) / num_tasks
for param, adapted_param in zip(noise_network.parameters(), adapted_noise_network.parameters()):
if param.grad is None:
param.grad = torch.zeros_like(param)
param.grad.data += (adapted_param.data - param.data) / num_tasks
# 更新元参数
meta_optimizer.step()
# 记录训练奖励(使用包装器中的episode_reward)
train_rewards.append(np.mean([env.episode_reward for env in envs]))
# 定期评估策略
if iteration % eval_freq == 0 or iteration == num_iterations - 1:
test_reward = evaluate_policy(policy, noise_network, test_env, horizon)
test_rewards.append(test_reward)
print(f"Iteration {iteration}, Train Reward: {train_rewards[-1]:.2f}, Test Reward: {test_reward:.2f}")
# 绘制学习曲线
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_rewards, label='Training Reward')
plt.xlabel('Iteration')
plt.ylabel('Reward')
plt.title('Training Reward Over Iterations')
plt.subplot(1, 2, 2)
plt.plot(test_rewards, label='Test Reward', color='orange')
plt.xlabel('Iteration')
plt.ylabel('Reward')
plt.title('Test Reward Over Iterations')
plt.tight_layout()
plt.show()
return policy, noise_network
def evaluate_policy(policy, noise_network, env, horizon=200):
state = env.reset()
episode_reward = 0
done = False
for _ in range(horizon):
if isinstance(state, tuple):
state = state[0]
# 生成噪声
noise_input = torch.FloatTensor(state).unsqueeze(0) + torch.randn_like(torch.FloatTensor(state).unsqueeze(0)) * 0.1
noise = noise_network(noise_input)
noise = noise * (torch.rand(1) + 0.5)
action_probs = policy.get_action_probs(state, noise)
action = np.argmax(action_probs[0].detach().numpy())
state, reward, done, _ = env.step(action)
episode_reward += reward
if done:
break
return episode_reward
# 训练 MAESN 算法
start_time = time.time()
trained_policy, trained_noise_network = maesn_train(env_name="CartPole-v1",
num_tasks=5,
num_iterations=500,
meta_lr=0.01,
inner_lr=0.1,
inner_steps=10,
gamma=0.95,
horizon=200,
eval_freq=10)
end_time = time.time()
cost_time = end_time - start_time
print(f"Training completed in {round(cost_time, 2)} seconds")
- 运行效果
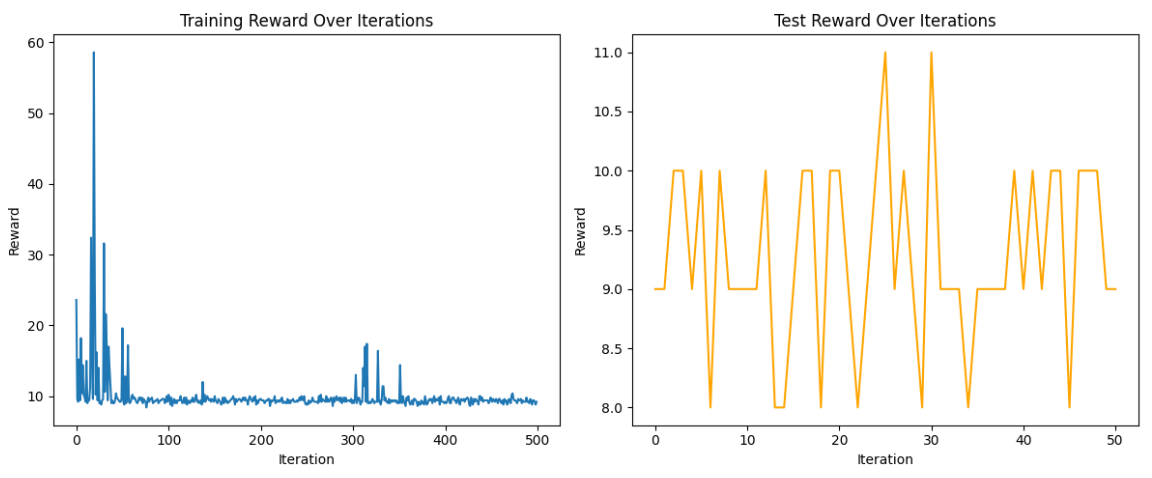
- 优点:
- 高效探索能力:通过隐层特征增强策略探索能力,提升新任务适应速度。
- 时间连贯随机性:隐层状态提供时间跨度更大的随机性,支持更连贯的探索行为。
- 缺点:
- 实现复杂度高:需同时优化策略参数与隐层分布参数,增加训练难度。
- 对噪声敏感:隐层噪声的设计与采样需谨慎,否则可能影响策略稳定性。
- 应用场景:
- 复杂环境探索:如需要高效探索的迷宫导航任务。
- 多目标优化:在存在多个潜在目标的场景中,实现策略的快速调整。
2、基于模型的元强化学习算法
RL^2(Reinforcement Learning Squared)
- 核心思想:利用RNN的记忆能力,使得模型能够记住之前任务的经验,从而在新任务上快速适应。
- 算法流程:
- 任务采样:从任务分布中采样多个任务。
- RNN输入:将每个任务的状态、动作和奖励输入RNN。
- 策略输出:RNN通过记忆上一个任务的经验,输出当前任务的策略。
- 元优化:通过每个任务的表现优化RNN的参数。
实现代码
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import gym
import matplotlib.pyplot as plt
# 定义策略网络(包含RNN)
class RL2Policy(nn.Module):
def __init__(self, input_size, output_size, hidden_size=128):
super(RL2Policy, self).__init__()
#输入维度: input_size + output_size + 1。这表示GRU的输入是由原始输入特征(input_size)、动作的one-hot编码(output_size)以及一个额外的奖励信号(+1)组合而成的。
#batch_first=True: 指定输入张量的形状为(batch_size, sequence_length, input_size)
#GRU(Gated Recurrent Unit)是一种循环神经网络(RNN)的变体,旨在解决标准RNN中的梯度消失和梯度爆炸问题
self.rnn = nn.GRU(input_size + output_size + 1, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden=None):
#隐藏状态用于存储和传递序列处理过程中的上下文信息。在处理序列数据时,每个时间步的输出不仅依赖于当前输入,还依赖于之前的所有输入。
out, hidden = self.rnn(x, hidden)
logits = self.fc(out)
probs = torch.softmax(logits, dim=-1)
return probs, hidden
# 任务采样函数, 创建多个相同类型的环境实例
def sample_tasks(env_name, num_tasks):
envs = [gym.make(env_name) for _ in range(num_tasks)]
return envs
# 训练函数
def train_rl2(env_name="CartPole-v1", num_tasks=5, num_iterations=100,
lr=0.01, hidden_size=128, horizon=200, gamma=0.95):
envs = sample_tasks(env_name, num_tasks)
input_size = envs[0].observation_space.shape[0]
output_size = envs[0].action_space.n
policy = RL2Policy(input_size, output_size, hidden_size)
optimizer = optim.Adam(policy.parameters(), lr=lr)
draw_loss = []
draw_return = []
for iteration in range(num_iterations):
all_losses = []
all_returns = []
for env in envs:
state = env.reset()
hidden = None
episode_states = []
episode_actions = []
episode_rewards = []
for t in range(horizon):
if isinstance(state, tuple):
state = state[0]
state_tensor = torch.FloatTensor(state).unsqueeze(0).unsqueeze(0)
if t > 0:
# 修改:将动作转换为one-hot编码, 使用one-hot编码可以将这些离散的动作表示为向量,使得它们可以被神经网络有效地处理
prev_action_onehot = torch.zeros((1, 1, output_size))
prev_action_onehot[0, 0, episode_actions[-1]] = 1
prev_reward = torch.FloatTensor([episode_rewards[-1]]).unsqueeze(0).unsqueeze(0)
rnn_input = torch.cat([state_tensor, prev_action_onehot, prev_reward], dim=-1)
else:
zero_action = torch.zeros((1, 1, output_size))
zero_reward = torch.zeros((1, 1, 1))
rnn_input = torch.cat([state_tensor, zero_action, zero_reward], dim=-1)
action_probs, hidden = policy(rnn_input, hidden)
action = torch.multinomial(action_probs.squeeze(0), 1).item() #从一个概率分布中采样一个动作
next_state, reward, done, _, _ = env.step(action)
episode_states.append(state)
episode_actions.append(action)
episode_rewards.append(reward)
state = next_state
if done:
break
# 计算损失
total_return = 0
losses = []
for t in reversed(range(len(episode_states))):
state = episode_states[t]
action = episode_actions[t]
reward = episode_rewards[t]
total_return = reward + total_return*gamma
state_tensor = torch.FloatTensor(state).unsqueeze(0).unsqueeze(0)
if t > 0:
# 修改:将动作转换为one-hot编码
prev_action_onehot = torch.zeros((1, 1, output_size))
prev_action_onehot[0, 0, episode_actions[t - 1]] = 1
prev_reward = torch.FloatTensor([episode_rewards[t - 1]]).unsqueeze(0).unsqueeze(0)
rnn_input = torch.cat([state_tensor, prev_action_onehot, prev_reward], dim=-1)
else:
zero_action = torch.zeros((1, 1, output_size))
zero_reward = torch.zeros((1, 1, 1))
rnn_input = torch.cat([state_tensor, zero_action, zero_reward], dim=-1)
action_probs, _ = policy(rnn_input)
log_prob = torch.log(action_probs.squeeze(0)[0, action])
loss = -log_prob * total_return
losses.append(loss)
episode_loss = torch.stack(losses).sum()
all_losses.append(episode_loss)
all_returns.append(np.sum(episode_rewards))
# 元优化
optimizer.zero_grad()
meta_loss = torch.stack(all_losses).mean()
meta_loss.backward()
optimizer.step()
meta_return = np.mean(all_returns)
draw_loss.append(meta_loss)
draw_return.append(meta_return)
print(f"Iteration {iteration}, Loss: {meta_loss.item():.4f}, Return: {meta_return.item():.4f}")
# 绘制损失图
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(draw_loss, label='Loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('Training Loss over Iterations')
plt.legend()
# 绘制回报图
plt.subplot(1, 2, 2)
plt.plot(draw_return, label='Return', color='orange')
plt.xlabel('Iteration')
plt.ylabel('Return')
plt.title('Training Return over Iterations')
plt.legend()
plt.tight_layout()
plt.show()
return policy
# 训练 RL² 算法
trained_policy = train_rl2(env_name="CartPole-v1",
num_tasks=5,
num_iterations=500,
lr=0.01,
hidden_size=128,
horizon=200,
gamma=0.95)
运行效果
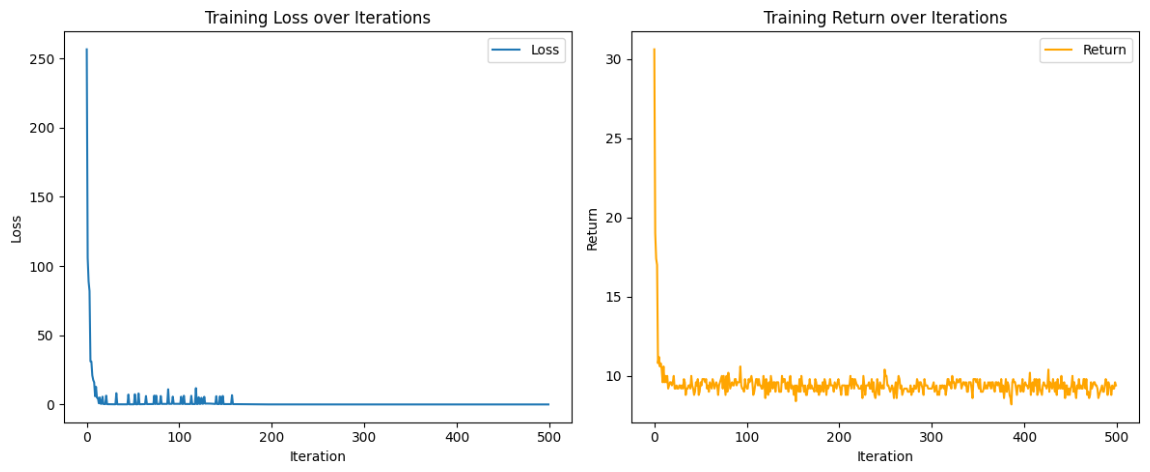
优点:
- 简单直观:通过RNN直接建模任务历史,实现策略的元学习,易于理解和实现。
- 端到端训练:将任务推断与策略更新整合在RNN中,简化训练流程。
- 缺点:
- 采样效率低:依赖在线策略,需大量交互数据,训练成本高。
- 任务推断能力有限:RNN难以处理长序列或复杂任务依赖关系,推断能力受限。
- 应用场景:
- 简单任务序列学习:如快速适应不同游戏规则的小规模任务。
- 动态环境决策:在任务规则变化不剧烈的场景中,实现策略的动态调整。
3、基于上下文(概率推断)的元强化学习算法
PEARL(Probabilistic Embeddings for Actor-Critic RL)
- 核心思想:PEARL是一种基于actor-critic框架的元强化学习方法,特别设计用于处理部分可观测环境中的问题。将元学习问题建模为概率推断,通过推断任务潜在表示调整策略。
- 算法流程:通过学习一个环境编码器,提取当前环境的关键特征,并将这些特征用于指导演员网络如何调整策略以最适应新环境。
- 实现代码
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Normal
import gym
from collections import deque, namedtuple
import random
import matplotlib.pyplot as plt
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 经验回放缓冲区
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
self.Transition = namedtuple('Transition',
('state', 'action', 'reward', 'next_state', 'done'))
def add(self, state, action, reward, next_state, done):
self.buffer.append(self.Transition(state, action, reward, next_state, done))
def sample(self, batch_size):
transitions = random.sample(self.buffer, batch_size)
batch = self.Transition(*zip(*transitions))
states = torch.FloatTensor(batch.state).to(device)
actions = torch.FloatTensor(batch.action).to(device)
rewards = torch.FloatTensor(batch.reward).unsqueeze(1).to(device)
next_states = torch.FloatTensor(batch.next_state).to(device)
dones = torch.FloatTensor(batch.done).unsqueeze(1).to(device)
return states, actions, rewards, next_states, dones
def __len__(self):
return len(self.buffer)
# 编码器网络 - 学习任务的潜在表示
class Encoder(nn.Module):
def __init__(self, state_dim, action_dim, latent_dim, hidden_dim):
# state_dim: 状态的维度。它表示每个状态向量的长度。
# action_dim: 动作的维度。它表示每个动作向量的长度。
# latent_dim: 潜在表示的维度。它表示编码器输出的潜在向量的长度。
# hidden_dim: 隐藏层的维度。它表示编码器中隐藏层的神经元数量。
super(Encoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(state_dim + action_dim + 1, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU()
)
self.mean = nn.Linear(hidden_dim, latent_dim) #用于从隐藏表示中计算潜在表示的均值。
self.log_std = nn.Linear(hidden_dim, latent_dim) #用于从隐藏表示中计算潜在表示的对数标准差。
self.latent_dim = latent_dim
def forward(self, context):
# context: [batch_size, seq_len, state_dim + action_dim + 1]
# batch_size: 批处理大小。
# seq_len: 序列长度,表示每个任务上下文的长度。
# state_dim + action_dim + 1: 每个时间步的状态、动作和奖励的拼接。
batch_size, seq_len, _ = context.shape
# 处理序列数据
h = self.encoder(context.reshape(batch_size * seq_len, -1)) #将输入 context 重塑为 [batch_size * seq_len, state_dim + action_dim + 1]
h = h.reshape(batch_size, seq_len, -1) #将 h 重塑为 [batch_size, seq_len, hidden_dim]
# 聚合序列信息(使用平均池化)
h = torch.mean(h, dim=1)
# 计算均值和标准差
mean = self.mean(h)
log_std = self.log_std(h)
log_std = torch.clamp(log_std, -20, 2) # 限制标准差范围
return mean, log_std
def sample(self, mean, log_std):
std = log_std.exp()
dist = Normal(mean, std) #创建正态分布
return dist.rsample() # 重参数化技巧
#使用 rsample() 方法从正态分布中采样,这是一种重参数化技巧,用于在反向传播中保持梯度。
# 策略网络 - 基于潜在表示和状态生成动作
class Policy(nn.Module):
def __init__(self, state_dim, action_dim, latent_dim, hidden_dim, max_action):
super(Policy, self).__init__()
self.latent_dim = latent_dim
self.policy = nn.Sequential(
nn.Linear(state_dim + latent_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU()
)
self.mean = nn.Linear(hidden_dim, action_dim)
self.log_std = nn.Linear(hidden_dim, action_dim)
self.max_action = max_action
def forward(self, state, z):
# 拼接状态和潜在表示
state_z = torch.cat([state, z], dim=1)
h = self.policy(state_z)
mean = self.mean(h)
log_std = self.log_std(h)
log_std = torch.clamp(log_std, -20, 2) # 限制标准差范围
std = log_std.exp()
dist = Normal(mean, std)
# 使用重参数化技巧采样动作
action = dist.rsample()
# 应用tanh squashing将动作限制在[-1, 1]范围内
squashed_action = torch.tanh(action) * self.max_action
# 计算对数概率(考虑tanh squashing)
log_prob = dist.log_prob(action).sum(dim=-1, keepdim=True)
log_prob -= (2 * (np.log(2) - action - F.softplus(-2 * action))).sum(dim=1, keepdim=True)
return squashed_action, log_prob, mean
def get_action(self, state, z):
if isinstance(state, tuple):
state = state[0]
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
z = torch.FloatTensor(z.reshape(1, -1)).to(device)
with torch.no_grad():
action, _, _ = self.forward(state, z)
return action.cpu().data.numpy().flatten()
# Critic网络 - 评估动作价值
class Critic(nn.Module):
def __init__(self, state_dim, action_dim, latent_dim, hidden_dim):
super(Critic, self).__init__()
# Q1架构
self.Q1 = nn.Sequential(
nn.Linear(state_dim + action_dim + latent_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
# Q2架构
self.Q2 = nn.Sequential(
nn.Linear(state_dim + action_dim + latent_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, state, action, z):
# 拼接状态、动作和潜在表示
state_action_z = torch.cat([state, action, z], dim=1)
q1 = self.Q1(state_action_z)
q2 = self.Q2(state_action_z)
return q1, q2
def Q1(self, state, action, z):
state_action_z = torch.cat([state, action, z], dim=1)
return self.Q1(state_action_z)
# PEARL主体算法
class PEARL:
def __init__(self, state_dim, action_dim, max_action, latent_dim=16, hidden_dim=256,
lr=3e-4, gamma=0.99, tau=0.005, beta=1.0, context_batch_size=64,
context_length=10):
self.state_dim = state_dim
self.action_dim = action_dim
self.max_action = max_action
self.latent_dim = latent_dim
self.gamma = gamma
self.tau = tau #目标网络的软更新系数。
self.beta = beta # KL散度系数
self.context_batch_size = context_batch_size
self.context_length = context_length
# 初始化网络
self.encoder = Encoder(state_dim, action_dim, latent_dim, hidden_dim).to(device)
self.policy = Policy(state_dim, action_dim, latent_dim, hidden_dim, max_action).to(device)
self.critic = Critic(state_dim, action_dim, latent_dim, hidden_dim).to(device)
self.critic_target = Critic(state_dim, action_dim, latent_dim, hidden_dim).to(device)
# 复制目标网络参数
self.critic_target.load_state_dict(self.critic.state_dict())
# 优化器
self.encoder_optimizer = optim.Adam(self.encoder.parameters(), lr=lr)
self.policy_optimizer = optim.Adam(self.policy.parameters(), lr=lr)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=lr)
# 上下文缓冲区(用于存储任务相关的转换)
self.context = []
def reset_context(self):
self.context = []
def add_to_context(self, state, action, reward, next_state, done):
self.context.append((state, action, reward, next_state, done))
def get_latent(self): #从当前任务收集的上下文数据中获取潜在表示
if len(self.context) == 0:
# 如果没有上下文,返回零向量
return torch.zeros(1, self.latent_dim).to(device)
# 准备上下文数据
states = []
actions = []
rewards = []
for s, a, r, ns, d in self.context:
# 确保每个状态是一个数值数组
if isinstance(s, tuple):
s = s[0]
states.append(np.array(s, dtype=np.float32).flatten()) # 将状态展平为一维数组
actions.append(np.array(a, dtype=np.float32))
rewards.append(np.array(r, dtype=np.float32))
# 转换为 NumPy 数组
states = np.array(states)
actions = np.array(actions)
rewards = np.array(rewards)
# 转换为张量
states = torch.FloatTensor(states).to(device)
actions = torch.FloatTensor(actions).to(device)
rewards = torch.FloatTensor(rewards).unsqueeze(1).to(device)
# 拼接状态、动作和奖励
context = torch.cat([states, actions, rewards], dim=1).unsqueeze(0) # [1, seq_len, state_dim+action_dim+1]
# 编码上下文获取潜在表示
mean, log_std = self.encoder(context)
z = self.encoder.sample(mean, log_std)
return z
def select_action(self, state):
z = self.get_latent()
return self.policy.get_action(state, z)
def train(self, replay_buffer, context_buffer, iterations):
for it in range(iterations):
# 从主回放缓冲区采样
state_batch, action_batch, reward_batch, next_state_batch, done_batch = replay_buffer.sample(
self.context_batch_size)
# 从上下文缓冲区采样任务上下文
context_batch = random.sample(context_buffer, self.context_batch_size)
# 处理上下文数据
context_states = []
context_actions = []
context_rewards = []
for context in context_batch:
# 从每个任务的上下文中随机选择一些转换
transitions = random.sample(context, min(len(context), self.context_length))
cs = torch.FloatTensor([s for s, a, r, ns, d in transitions]).to(device)
ca = torch.FloatTensor([a for s, a, r, ns, d in transitions]).to(device)
cr = torch.FloatTensor([r for s, a, r, ns, d in transitions]).unsqueeze(1).to(device)
context_states.append(cs)
context_actions.append(ca)
context_rewards.append(cr)
# 对每个任务并行处理
for i in range(self.context_batch_size):
# 准备当前任务的上下文
cs = context_states[i].unsqueeze(0) # [1, seq_len, state_dim]
ca = context_actions[i].unsqueeze(0) # [1, seq_len, action_dim]
cr = context_rewards[i].unsqueeze(0) # [1, seq_len, 1]
# 拼接上下文
context = torch.cat([cs, ca, cr], dim=2) # [1, seq_len, state_dim+action_dim+1]
# 编码上下文获取潜在表示
mean, log_std = self.encoder(context)
z = self.encoder.sample(mean, log_std) #表示当前任务的潜在特征
# 扩展潜在表示以匹配批量大小
z_expanded = z.repeat(self.context_batch_size, 1)
# 计算目标Q值
with torch.no_grad():
next_action, _, _ = self.policy(next_state_batch, z_expanded)
target_Q1, target_Q2 = self.critic_target(next_state_batch, next_action, z_expanded)
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward_batch + (1 - done_batch) * self.gamma * target_Q
# 获取当前Q估计
current_Q1, current_Q2 = self.critic(state_batch, action_batch, z_expanded)
# 计算critic损失
critic_loss = F.mse_loss(current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
# 优化critic
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 计算policy损失
new_action, log_prob, _ = self.policy(state_batch, z_expanded)
Q1, Q2 = self.critic(state_batch, new_action, z_expanded)
Q = torch.min(Q1, Q2)
# 计算策略损失和KL散度
policy_loss = -Q.mean() + (self.beta * log_prob).mean()
# 优化policy
self.policy_optimizer.zero_grad()
policy_loss.backward()
self.policy_optimizer.step()
# 计算encoder损失(变分下界)
# 先验是标准正态分布
prior_mean = torch.zeros_like(mean)
prior_log_std = torch.zeros_like(log_std)
# 计算KL散度
kl_div = -0.5 * torch.sum(1 + 2 * log_std - mean.pow(2) - (2 * log_std).exp(), dim=1)
kl_div = kl_div.mean()
# 计算编码器损失
encoder_loss = kl_div
print("encode loss is", encoder_loss, "------", i)
# 优化encoder
self.encoder_optimizer.zero_grad()
encoder_loss.backward()
self.encoder_optimizer.step()
# 更新目标网络
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
# 训练函数
def train_pearl(env_name, max_episodes=200, max_timesteps=100, latent_dim=16, #max_timesteps训练过程中的最大回合数, latent_dim潜在表示的维度
hidden_dim=256, batch_size=64, context_batch_size=16, #hidden_dim训练时的批量大小, context_batch_size上下文批次的大小
context_length=10, beta=1.0, eval_freq=10): #context_length 每个任务上下文的长度,即从每个任务中采样的轨迹长度, beta KL 散度的系数
# 创建环境
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
# 初始化PEARL代理
agent = PEARL(state_dim, action_dim, max_action, latent_dim, hidden_dim, beta=beta,
context_batch_size=context_batch_size, context_length=context_length)
# 初始化回放缓冲区,用于训练 Critic 网络和策略网络
replay_buffer = ReplayBuffer(int(1e6))
# 初始化上下文缓冲区(存储多个任务的上下文),用于更新编码器的参数
context_buffer = []
# 记录结果
rewards_history = []
# 训练循环
for episode in range(max_episodes):
print("max_episodes-->", episode)
# 重置环境和代理的上下文
state = env.reset()
if isinstance(state, tuple):
state = state[0]
agent.reset_context()
episode_reward = 0
episode_context = [] #存储当前任务的上下文
for t in range(max_timesteps):
print("max_timesateps-->",t)
# 选择动作
action = agent.select_action(state)
# 执行动作
next_state, reward, done, _, _ = env.step(action)
# 保存转换到主回放缓冲区
replay_buffer.add(state, action, reward, next_state, done)
# 保存转换到当前任务的上下文
agent.add_to_context(state, action, reward, next_state, done)
episode_context.append((state, action, reward, next_state, done))
state = next_state
episode_reward += reward
if done:
break
# 将当前任务的上下文添加到上下文缓冲区
context_buffer.append(episode_context)
# 记录奖励
rewards_history.append(episode_reward)
# 训练代理
if len(replay_buffer) > batch_size and len(context_buffer) > context_batch_size:
agent.train(replay_buffer, context_buffer, iterations=1)
# 定期评估
if episode % eval_freq == 0:
avg_reward = evaluate_policy(agent, env_name, max_timesteps, eval_episodes=5)
print(f"Episode {episode}, Avg Reward: {avg_reward:.3f}")
# 绘制学习曲线
plt.figure(figsize=(10, 5))
plt.plot(rewards_history)
plt.title('PEARL Training Rewards')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.show()
return agent
# 评估策略
def evaluate_policy(agent, env_name, max_timesteps, eval_episodes=5):
env = gym.make(env_name)
avg_reward = 0.
for _ in range(eval_episodes):
state = env.reset()
agent.reset_context()
done = False
while not done:
action = agent.select_action(state)
state, reward, done, _, _ = env.step(action)
avg_reward += reward
avg_reward /= eval_episodes
return avg_reward
# 训练PEARL代理
if __name__ == "__main__":
env_name = "Pendulum-v1" # 可以替换为其他连续控制环境
agent = train_pearl(env_name, max_episodes=200, max_timesteps=100)
- 优点:
- 采样效率高:通过潜在表示学习任务特征,减少对大量数据的需求,尤其适用于数据稀缺场景。
- 离策略训练支持:可利用历史经验回放,提高数据利用率,加速训练过程。
- 快速适应新任务:通过潜在表示捕捉任务差异,使策略网络能快速调整行为以适应新环境。
- 缺点:
- 计算复杂度高:潜在表示的学习与推理增加了计算开销,对硬件资源要求较高。
- 潜在表示泛化性限制:在任务差异显著时,潜在表示可能无法有效泛化,影响适应能力。
- 应用场景:
- 机器人控制:如适应不同摩擦力或重力的行走任务。
- 自动驾驶:快速适应不同天气或路况的驾驶策略。

















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









