







【系列】计算理论
文章目录
1. 为什么要关注有限自动机?
有限自动机 (Finite Automata,简称 FA) 是计算机科学与计算理论中最基础、最具代表性的模型之一。它用来模拟“有限记忆”的系统或过程,其重要性体现在以下方面:
-
正则语言识别
几乎所有的正则语言都可以用 DFA(确定型有限自动机)来识别。正则表达式在搜索、文本处理、编译器前端等众多领域广泛使用,而它们与有限自动机在理论上具有等价性。换言之,能够被正则表达式描述的语言,也能通过一个 DFA(或 NFA 转换为 DFA)来识别。 -
词法分析
在编译器或解释器的词法分析(Lexical Analysis)阶段,常常先将词法规则转换为正则表达式,再转成 NFA,然后应用子集构造法得到 DFA,通过该自动机对源代码进行切词(Tokenize)。这是一条经典路线:正则表达式 → NFA → DFA → 最小化 DFA → 词法分析器。 -
协议或系统状态机
许多协议、硬件电路或软件系统可以抽象为有限状态机(FSM),用于描述系统在不同输入或外部事件下的状态演变。它在网络协议栈、数字逻辑设计、嵌入式系统中都有广泛应用。例如,一个简单的通信协议可以抽象为若干状态及其转换来表示“等待连接、建立连接、传输数据、断开连接”等步骤。 -
理论与实践的桥梁
虽然 FA 的记忆能力有限,无法处理需要无限记忆或深层嵌套结构的语言,但它在理论上构建了计算模型的基石,帮助人们进一步理解从正则语言到上下文无关语言、再到递归可枚举语言的层级。对 FA 的掌握也为深入研究更复杂的模型(如上下文无关文法、图灵机)奠定扎实基础。
因此,无论是从编译器构建的角度,还是从协议设计、模型校验,亦或从理论研究的层面,有限自动机都有非常重要的地位。
2. 有限自动机的基本构造
通常,一个有限自动机 M 可以用五元组形式表示:
M = (Q, Σ, δ, q₀, F)
- Q:状态集(有限多个)。
- Σ:输入符号表(alphabet),也称字母表,例如 {0, 1}。
- δ:转移函数,规定在某个状态下读取某个符号后,系统会转移到哪个新状态。
- q₀:初始状态,系统在处理输入串之前所处的状态。
- F:接受状态集,也称终止状态集。当自动机在读取完整输入后停在其中一个状态时,代表接受。
实际运行流程如下:
- 将自动机初始化到状态 q₀。
- 逐个读取输入串中的字符,根据状态转移函数 δ 进行跳转。
- 如果读完所有字符后,落在某个属于 F 的状态上,则判定为“接受”;否则判定为“不接受”。
这个过程反映了自动机有限记忆的特性:在任何时刻,自动机只能“记住”它当前所处的状态,而并不能无限地存储先前输入的详细信息。
3. 经典示例
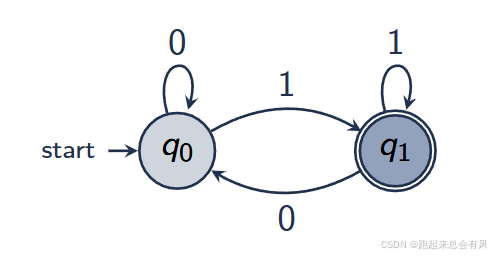
3.1 识别以 1 结尾的二进制串
- 语言:所有二进制串中,最后一个符号是 1。
- 两态设计示例:q0(“尚未读到以 1 结尾”或“目前结尾为 0”)、q1(“目前结尾为 1”)。
- 转移规则:
- 在 q0 下:
- 读到 0 -> 仍在 q0;
- 读到 1 -> 转到 q1。
- 在 q1 下:
- 读到 0 -> 回到 q0;
- 读到 1 -> 继续留在 q1。
- 在 q0 下:
- 接受态:q1。
直观含义是:如果最后读到的符号为 1,则接受该字符串;否则不接受。
4. DFA 与 NFA
DFA (Deterministic Finite Automata):在任意状态下,对于某个特定输入符号,只有一个确定的下一个状态。
NFA (Nondeterministic Finite Automata):在任意状态下,对于某个输入符号,允许有多个可能的下一个状态,或者可能存在 ε-转移(读空串进行状态转移)。
虽然在描述系统时 NFA 似乎更灵活,但它与 DFA 在识别语言的能力上是等价的:任何一个 NFA 都可以用子集构造法(Subset Construction)转换为一个相应的 DFA。
4.1 NFA 的特点
- NFA 在同一个状态和同一个输入符号上,可以有多条转移路径供选择。
- 甚至可能在不消耗输入字符的情况下(ε-转移)发生状态跳转。
4.2 从 NFA 到 DFA 的转换
子集构造法的要点是:用某个状态子集来表示 NFA 在读入一定量的输入后可能处于的所有状态的集合。
- 初始子集是 NFA 的初始状态 q₀ 及与之通过 ε-转移可达的所有状态。
- 在每一步扩展子集时,也要将 ε-闭包(epsilon closure)的概念纳入考虑。
由此可见,尽管 NFA 在形式上看起来更简洁或更灵活,但只要我们愿意付出一些状态冗余的代价(即使用子集构造法),就可以将其变为一个确定型自动机。
5. 自动机的模拟与实现
实现一个有限自动机,通常需要存储下列要素:
- 状态集:可用整数或枚举来标识每个状态。
- 输入符号表 (Σ):例如字符、二进制位、或更通用的 token。
- 转移函数 (δ):对每个状态和符号,对应下一个状态的映射,可存储成二维数组(若使用整数索引)、或字典嵌套字典的方式。
- 初始状态:通常只需要一个变量存储 q₀。
- 接受状态集:可以在一个布尔数组或集合中标记某些状态是否为“接受态”。
5.1 DFA 仿真
对一个 DFA 而言,模拟过程十分 straightforward:
- current_state = q₀
- 对输入串中的每个字符 x:
- current_state = δ(current_state, x)
- 判断 current_state 是否在 F 中。如果是,则返回“接受”,否则返回“不接受”。
5.2 NFA 仿真
NFA 的仿真相对复杂些,需要维护一组可能状态:
- current_states = ε-closure(q₀) // 起始时包括 q₀ 以及与之ε相连可到达的所有状态
- 对输入串中的每个字符 x:
- new_states = ∅
- 对于 current_states 中每个状态 s:
- 根据 x 找到从 s 出发的可达状态集合 T
- 对 T 中的每个状态 t,将其ε-closure内所有状态加入 new_states
- current_states = new_states
- 最后,看 current_states 中是否有至少一个状态属于 F;若有,则“接受”,否则“不接受”。
5.3 代码层面
无论是 DFA 还是 NFA,都可以将转移关系 δ 存储在一个数据结构(如数组或字典)里,写出一个通用的 simulate(automaton, input_string) 函数,对输入串逐字符进行遍历与状态跳转。
- 如果自动机是 DFA,则只是一个单一的 current_state 的更新。
- 如果自动机是 NFA,则需要维护一个状态集合,以及在每次输入字符后计算新的状态集合。
6. 动手实践与更深入探讨
若要从概念过渡到实践,这里给出几个方向可进一步学习或实验:
-
从正则表达式到自动机
- 给定一个简单的正则表达式,例如
(a|b)*a,先使用标准算法构造 NFA(Thompson 构造法),再用子集构造法转换为相应的 DFA,并尝试进行最小化。 - 对于每一步骤,手动或编写程序输出中间结果,以加深对理论与实践转化过程的理解。
- 给定一个简单的正则表达式,例如
-
状态最小化 (DFA Minimization)
- 给定一个 DFA,有时会存在冗余状态。可以使用等价状态合并算法来减少状态数量。
- 这个过程既可以手工操作(对状态进行分区、细分直到稳定),也可以用程序实现。
-
自动机的可视化
- 借助图形化的手段(例如 Graphviz)将自动机的状态和转移关系绘制成状态迁移图,会让整体结构更直观便于调试。
- 特别是在学习或者教学场景,画出状态图常能迅速发现某些设计上的错误。
-
与编译器前端的结合
- 在编译器课程或项目中,可以直接把上述思路应用到词法分析器的生成中。很多自动化工具(如 lex/flex)内部就是通过正则到 NFA,再到 DFA,再到最小化 DFA 的流程,为我们自动生成状态机。
-
更高级模型的演进
- 从 FA 出发,可以进一步理解上下文无关文法 (CFG)、下推自动机 (PDA) 以及图灵机 ™。这些更强大的模型允许带“堆栈”或“无限带”存储能力,因此能识别更复杂的语言,例如带嵌套结构的括号匹配。
-
行业应用示例
- 网络协议:TCP/IP 协议栈中的连接建立、状态变迁(CLOSED, LISTEN, SYN_SENT, SYN_RCVD, ESTABLISHED, FIN_WAIT等)都能看作是一个有限状态机,每一次报文到来都导致状态转移。
- 硬件设计:组合逻辑与时序逻辑电路常用有限状态机描述;FPGA、ASIC 等芯片设计中也常将 FSM 作为基本组件。
- 控制系统:在嵌入式或自动控制领域,系统对外部输入的响应常通过可视化状态机来描述。
通过多层次、多场景的结合,不但能让你更好地掌握有限自动机的内涵与适用范围,也会增强在实际项目中运用这套理论工具的信心与能力。
结语
有限自动机是一种既简单又功能强大的数学模型。对于初学者而言,从定义到示例再到程序实现,能迅速感受到理论与实践的有机结合。无论是要将其用于编译器的词法分析、网络协议的状态跟踪,还是教学与自学中进一步攀登计算理论的高峰,FA 都是令人受益无穷的入门起点。请多动手尝试构造各种状态机,或尝试实现它们的模拟程序,这些过程会助力你深刻理解 FA 原理,并为更复杂的自动机理论学习打下坚实基础。



















 7709
7709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











