







文章主旨
本文针对初学机器学习人员,利用文心一言等大预研模型,通过有效提问,实现利用大语言模型来辅助快速编写pytorch框架下python程序的目的。
问题描述
在攻打比赛过程中,发现训练集的损失函数不断收敛,但比赛分数并没有随之上涨。以下是训练集的损失函数变化:
Epoch70/1600,Loss:0.307704523417957
Epoch71/1600,Loss:0.249927623173859
Epoch72/1600,Loss:0.258905884184981
Epoch73/1600,Loss:0.295816174437162
Epoch74/1600,Loss:0.234433079421332
于是怀疑在训练过程中存在过拟合现象。
问题解决
在文心一言大模型中,用自然语言的描述形式向其提问:
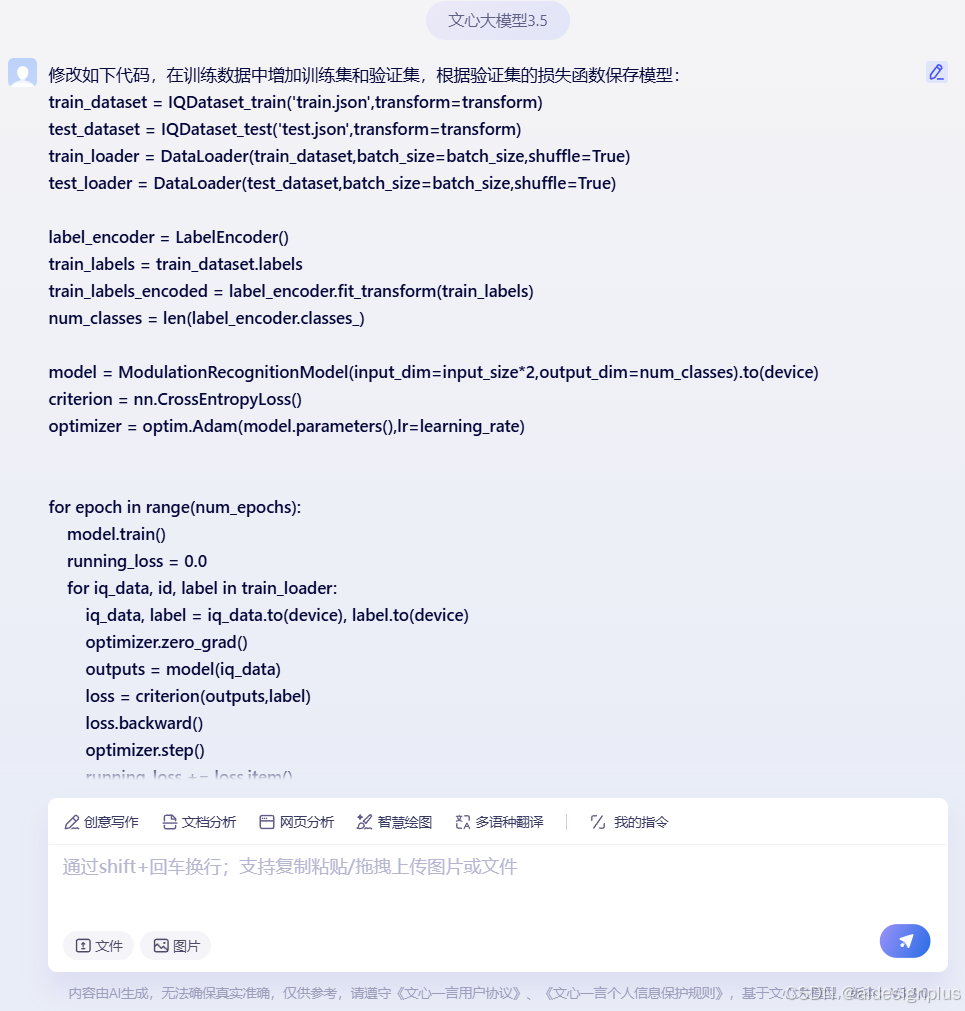
文心一言给出的官方有营养回答是:
import torch
from torch.utils.data import DataLoader, random_split
from sklearn.preprocessing import LabelEncoder
import torch.nn as nn
import torch.optim as optim
# 假设你已经定义了IQDataset_train, IQDataset_test, 和 ModulationRecognitionModel
# 以及其他必要的参数如input_size, batch_size, num_epochs, learning_rate, device
# 加载数据集
train_dataset = IQDataset_train('train.json', transform=transform)
test_dataset = IQDataset_test('test.json', transform=transform)
# 分割训练数据集为训练集和验证集
train_size = int(0.8 * len(train_dataset)) # 80% 用于训练,20% 用于验证
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 编码标签
label_encoder = LabelEncoder()
train_labels = train_dataset.labels
train_labels_encoded = label_encoder.fit_transform(train_labels)
num_classes = len(label_encoder.classes_)
# 初始化模型、损失函数和优化器
model = ModulationRecognitionModel(input_dim=input_size*2, output_dim=num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 保存模型的最佳状态
best_val_loss = float('inf')
best_model_wts = model.state_dict()
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for iq_data, id, label in train_loader:
iq_data, label = iq_data.to(device), label.to(device)
optimizer.zero_grad()
outputs = model(iq_data)
loss = criterion(outputs, label)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(train_loader):.15f}')
# 验证阶段
model.eval()
val_loss = 0.0
with torch.no_grad():
for iq_data, id, label in val_loader:
iq_data, label = iq_data.to(device), label.to(device)
outputs = model(iq_data)
loss = criterion(outputs, label)
val_loss += loss.item()
val_loss /= len(val_loader)
print(f'Validation Loss: {val_loss:.15f}')
# 检查是否保存模型
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model_wts = model.state_dict()
# 检查是否需要调整学习率
if epoch % 50 == 0 and epoch != 0:
for param_group in optimizer.param_groups:
param_group['lr'] /= 1.4
print(f'Learning rate reduced to {optimizer.param_groups[0]["lr"]:.6f} at epoch {epoch+1}')
# 加载最佳模型权重
model.load_state_dict(best_model_wts)
# 在这里可以添加保存模型的代码,例如:
# torch.save(model.state_dict(), 'best_model.pth')
有时在和大语言模型的对话中,发现有时自己没说清楚的东西,竟然他在代码中也考虑到了,可能自己在他的面前就是小学生吧。其他大语言模型可以尝试阿里巴巴的通义大模型、腾讯的混元大模型和科大讯飞的星火大模型,欢迎在留言区把各位的心得进行交流。
解决效果
大模型出手后是立竿见影、手起刀落、药到病除。
Epoch70/1000,Loss:0.485642382948417
Validation Loss:0.175171304959804
Epoch71/1000,Loss:0.444372663347740
Validation Loss:0.151291660964489
Epoch72/1000,Loss:0.440837071511865
Validation Loss:0.159813182428479
Epoch73/1000,Loss:0.447838771413630
Validation Loss:0.172257545404136
Epoch74/1000,Loss:0.482291213170750
Validation Loss:0.186672694748268
至于比赛的名次是否上升。根据小伙伴们评论区的留言热烈情况再和大家汇报。
后续还会增加大模型解决其他简易类代码修改问题,敬请留意。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











