







声明:为了方便自己查阅,搬过来各个博主的博文,具体参考原博文。
引言
1. 定义
- 图像分类:应用于图像级分类,在全连接层后接softmax得到分类概率,常用CNN;
- 图像分割:应用于像素级分类,softmax应用于特征通道方向,上采样后对每个像素进行像素级的分类,常用FCN等;
- 目标检测(object detection):给定一幅图像,只需要找到一类目标所在的矩形框;
- 目标识别(object recognition):将需要识别的目标,和数据库中的某个样例对应起来,完成识别功能。

图片来源于一文读懂图像分类、目标定位、语义分割与实例分割的区别
2. 图像分割
- 语义分割(semantic segmentation):对图像中的每个像素都划分出对应的类别,即对一幅图像实现像素级别的分类,但语义分割不区分属于相同类别的不同实例,如图(c)中cube是同一个颜色;
- 实例分割(instance segmentation):对图像中的每个像素都划分出对应的类别,即实现像素级别的分类,类的具体对象,即为实例,那么实例分割不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例,如图(c)中不同颜色的cube。
注:
当图像中有多只猫时,语义分割会将两只猫整体的所有像素预测为“猫”这个类别。
实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫。
2. 图像分割与分类代码
- 分类时,需要再进行分类前将数据采用flatten进行整合,在采用线性层将数据压缩为响应的类别数目,得到概率值,进行损失函数计算。
- 例如,图像输入net,先根据处理获取feature,再将feature进行展开/打平;在采用线性层对数据进行压缩得到概率值;(最后一步可以直接采用输出通道为classnumber的输入特征大小卷积核进行压缩处理)
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
# torch.flatten(x)等于torch.flatten(x,0),默认将张量拉成一维的向量,也就是说从第一维开始平坦化,也就是开始整合。
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
- 分割网络,则采用卷积或对网络进行上采样,将数据恢复到原始图像尺度,得到相应的概率值,并计算损失函数。
- 语义分割在这里可以简单地理解为将最后的线性层替换为卷积层(卷积核大小应远小于输入特征大小,不要与上文的压缩特征混淆)
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Con2D(last_channel, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = self.classifier(x)
#如果特征与标签尺寸不一致,寻要对特征进行上采样处理
return x
一、数据集
1. 数据集
本文数据集为Lits2017肝脏和病灶的分割。标签为(0 1 2)。此数据集为增强CT,所以需要进行窗口的处理。具体参考【医学图像预处理过程】
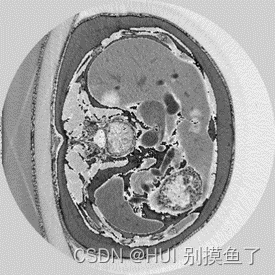
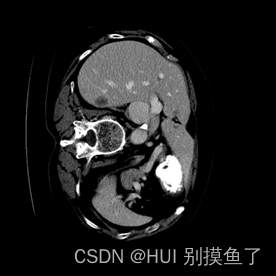

注: 上面的标签图是自己赋值进行可视化的,实际是[0 1 2 ],根据自己数据集的情况查看mask值:
class = np.unique(mask)
# 输出:[0, 1, 2]
分析: 分割出肝脏(灰色)、肿瘤(白色),再加上黑色背景,相当于是一个三分类问题。
其他数据集的例子:
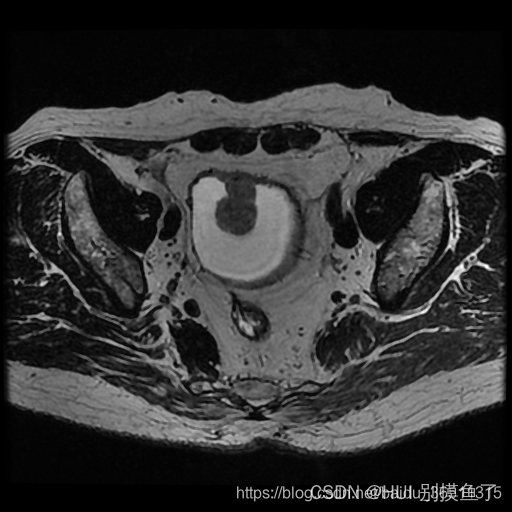

注:
-
灰度值:灰色128为膀胱内外壁,白色255为肿瘤。标签为 [0 128 255 ]。
-
任务:是要同时分割出膀胱内外壁和肿瘤部分,加上背景,最后构成一个三分类问题。
2. 数据预处理
2.1 预处理one-hot
2.1.1 标签one-hot目的
对标签进行one-hot是为了后续计算损失或评价指标做准备。在 loss 的计算时,Pytorch 有些 loss 函数需要网络的 ouput (B, 3, 512, 512) 与 label (B, 512, 512) 的 shape 相同,由于输出特征图的层数channel对应类别数 num_classes(=3) ,而标签图每个点的值是像素点所属类别,因此可以按类别数将标签图像转化为多层,每一层对应一类,即对 label 进行 one-hot encoding。
2.1.2 标签one-hot处理
转化为one hot的形式来表示一个物体的类别。


(1) 转化为one-hot ;
例如:3类,分别用(0,0,1) (0,1,0) (1,0,0)来表示,然后计算交叉熵损失函数。

- one-hot代码:参考【图像分割】图像分割中数据预处理 One-hot 编码的两种实现方式,此处贴一个例子。
# helpers.py
import os
import csv
import numpy as np
# mask_to_onehot用来将标签进行one-hot
def mask_to_onehot(mask, palette):
"""
Converts a segmentation mask (H, W, C) to (H, W, K) where the last dim is a one
hot encoding vector, C is usually 1 or 3, and K is the number of class.
"""
semantic_map = []
for colour in palette:
equality = np.equal(mask, colour) # 判断相同,返回一个m*N的false or true数组
# 0为列,axis=1表示按“行”操作。表示在水平方向上计算元素的逻辑与(AND)
class_map = np.all(equality, axis=-1)
semantic_map.append(class_map)
# np.stack([arrays1,array2,array3],axis=0),0代表整体堆叠,1代表按行堆叠,2代表列
semantic_map = np.stack(semantic_map, axis=-1).astype(np.float32)
return semantic_map
# onehot_to_mask用来恢复one-hot,在可视化的时候使用。
def onehot_to_mask(mask, palette):
"""
Converts a mask (H, W, K) to (H, W, C)
"""
# 将标签索引值 0 1 2,转换为原标签值 0 128 255
x = np.argmax(mask, axis=-1)
colour_codes = np.array(palette)
x = np.uint8(colour_codes[x.astype(np.uint8)])
return x
该方法在使用的时候需要先定义好颜色表palette(根据自己的数据集来定义就行了)。
假设:gt是灰度图,需要分割两个目标(正常器官和肿瘤)(加上背景就是3分类任务),背景的灰度值为0,正常器官的灰度值为1,肿瘤的灰度值为2, 。
# 此处根据自己的标签颜色来设置,Lits2017的数据集标签为0 1 2
palette = [[0], [1], [2]] # 里面值的顺序不是固定的,可以按自己的要求来
# palette = [[0], [128], [255]]
# 注意:灰度图的话要确保 gt的 shape = [H, W, 1],该函数实在最后的通道维上进行映射
# 如果加载后的gt的 shape = [H, W],则需要进行通道的扩维
gt_onehot = mask_to_onehot(gt, palette) # one-hot 后 gt的shape=[H, W, 3]
说明:
- 在分割任务中:
- 原始gt(ground truth): shape = [H, W, 3](彩色或rgb图)或 [H, W](灰度图)
- 原始数据: shape = ( batch_size, 1, h, w )
- 网络输出: shape 为 ( batch_size, num_classes, h, w )
- one-hot对原始gt进行编码,将其编码为[H, W, 3],最后再对维度进行transpose为[3,H,W]。具体为:编码成 特征图层数(类别数)num_classes =3 个, 大小为 ( batch_size, h, w)的全为 1 的 tmplate 张量,将 tmplate中属于该类别的改为 1,其余为 0, 并 reshape 成 (batch_size, 1, h, w), 最后在第二维(num_classes)对所有的tmplate张量 np.concatenate(多个数组沿一个指定的轴方向拼接,生成一个新的数组)
(2) 各类别的预测值
- 动物分类任务,有三种可预测类别:猫、狗、猪。
- 预测值是通过sigmoid/softmax的方式得到对于每个预测结果的概率值,概率值的和为1。
| 预测概率 | 真实one-hot | 是否正确 |
|---|---|---|
| 0.3 0.3 0.4 | 0 0 1(猪) | 正确 |
| 0.3 0.4 0.3 | 0 1 0(狗) | 正确 |
| 0.1 0.2 0.7 | 1 0 0(猫) | 错误 |
(3) 损失计算
- 交叉熵函数:
L = 1 N ∑ i L i = − 1 N ∑ i ∑ c = 1 M y i c log p i c . L = \frac {1} {N} \sum \limits _{i} L_i = -\frac {1} {N} \sum \limits _{i}\sum \limits _{c=1} ^{M} y_{ic}\log{p_{ic}}. L=N1i∑Li=−N1i∑c=1∑Myiclogpic. - M M M——类别的数量,比如三类, M = 3 M=3 M=3;
- y i c y_{ic} yic——符号函数(0或1),如果样本 i i i的真实类别 c c c取1,否则取0;
-
p
i
c
p_{ic}
pic——观测样本
i
i
i属于类别
c
c
c的预测概率。
模型:
s a m p l e 1 _ l o s s = − ( 0 ∗ l o g 0.3 + 0 ∗ l o g 0.3 + 1 ∗ l o g 0.4 ) = 0.91 s a m p l e 2 _ l o s s = − ( 0 ∗ l o g 0.3 + 1 ∗ l o g 0.4 + 0 ∗ l o g 0.3 ) = 0.91 s a m p l e 3 _ l o s s = − ( 1 ∗ l o g 0.1 + 0 ∗ l o g 0.2 + 0 ∗ l o g 0.7 ) = 2.30 sample1\_loss=-(0*log0.3+0*log0.3+1*log0.4)=0.91 \\ sample2\_loss=-(0*log0.3+1*log0.4+0*log0.3)=0.91\\ sample3\_loss=-(1*log0.1+0*log0.2+0*log0.7)=2.30 sample1_loss=−(0∗log0.3+0∗log0.3+1∗log0.4)=0.91sample2_loss=−(0∗log0.3+1∗log0.4+0∗log0.3)=0.91sample3_loss=−(1∗log0.1+0∗log0.2+0∗log0.7)=2.30
对所有样本的loss求平均: L = 0.91 + 0.91 + 2.30 3 = 1.37 L=\frac {0.91+0.91+2.30} {3} =1.37 L=30.91+0.91+2.30=1.37
2.1.3 one-shot 计算欧式距离
2.1.4 one-shot 语义分割算法
当测试集中出现新类(不包括在训练集中),同时在测试集中仅仅给定该新类的一张图片和对应语义分割结果 (Support Set),如何对其他测试图片 (Query Image) 进行语义分割?
参考one-shot 语义分割算法
2.2 其他操作
考虑服务器或电脑的性能,在对数据预处理的时候进行了缩放(scale) 和中心裁剪(center crop) 。原始数据大小为512,首先将数据缩放到256,再裁剪到128的大小。
2.2.1 缩放
2.2.2 中心裁剪
3. 训练集和验证集划分
这部分可以提前划分好,也可以在代码里划分。
4. 数据加载和处理
5. 数据变换
二、模型
-
可以跑通的代码:
-
其他代码:
-
U-Net实现医学图像分割(pytorch),肺分割,绘制曲线精确率、召回率、f1得分
-
手把手教你用UNet做医学图像分割系统,皮肤病分割,2分类
-
UniverSeg:通用医学图像分割,有说这个网络不行,我在其他医学数据集上结果跑出的结果基本没对。
-
医学图像分割之TransUNet, 在我的数据集CT图像上进行训练,发现TransUNet的性能并没有很好,是不如UNet的。
三、损失
1. 交叉熵损失函数
1.1 交叉熵损失函数
MSE为什么不能用在分类问题上,为什么softmax+CE,BCELoss+Sigmoid,证明参考: CE Loss 与 BCE Loss 学习和应用
1.1.1 二分类
- BCE+Sigmoid,输出层常用Sigmoid激活函数(对输出的每一个维度用Sigmoid),需要做one-hot。
- 在Pytorch中,函数nn.BCELoss()。
L = 1 N ∑ i L i = − 1 N ∑ i y n log p n + ( 1 − y n ) log ( 1 − p n ) . L = \frac {1} {N} \sum \limits _{i} L_i = -\frac {1} {N} \sum \limits _{i}\ y_{n}\log{p_{n}}+\ (1-y_{n})\log{(1-p_{n})}. L=N1i∑Li=−N1i∑ ynlogpn+ (1−yn)log(1−pn).
1.1.2 多分类
- CE+softmax,使用多元交叉损失函数(CrossEntropyLoss),输出层常用softmax激活函数。
(推荐)在Pytorch中,函数nn.CrossEntropyLoss()(参考:torch.nn.CrossEntropyLoss用法),不需要做one-hot和softmax 。- nn.CrossEntropyLoss()是nn.logSoftmax()和nn.NLLLoss()的整合(将两者结合到一个类中)。nn.NLLLoss的输入target是类别值,并不是one-hot编码格式,这个要注意!! 所以,CrossEntropyLoss()的target输入也是类别值,不是one-hot编码格式;
- CrossEnrtopyLoss要求的target的值就是标签的索引值,即不需要网络输出(如原标签为[0, 128, 255])经过argmax()处理得到类别标签索引值0,1,2(参考:语义分割由网络输出到类别标签的处理过程)。
1.1.3 多标签分类
- 多标签分类任务可以简单地理解为多个二元分类任务叠加。如数据集3Dirds。所以二分类交叉熵(BCELoss)经过简单修改也可以适用于多标签分类任务。
- BCE+Sigmoid,需要做one-hot。
(推荐)在Pytorch中,函数nn.BCEWithLogitsLoss(),对输入值自动做sigmoid操作,但需要做one-hot。
1.2 Sigmoid和Softmax的本质
- 探究其统计学本质,Sigmoid的输出为伯努利分布,也就是我们常说的二项分布(
注:P ( y 1 ∣ X ) , P ( y 2 ∣ X ) , P ( y 3 ∣ X ) , . . . , P ( y n ∣ X ) P(y_1|X),P(y_2|X),P(y_3|X),...,P(y_n|X) P(y1∣X),P(y2∣X),P(y3∣X),...,P(yn∣X));而Softmax的输出表示为多项式分布(注:P ( y 1 , y 2 , y 3 , . . . , y n ∣ X ) P(y_1,y_2,y_3,...,y_n|X) P(y1,y2,y3,...,yn∣X))。所以Sigmoid通常用于二分类,Softmax用于多类别分类。
1.2.1 Sigmoid
- Sigmoid函数形式为: S i g ( x j ) = 1 1 + e − x , j = 1 , 2 , . . . , K . Sig(x_j) = \frac {1} {1+ e^{-x}} ,j=1,2,...,K. Sig(xj)=1+e−x1,j=1,2,...,K.
- 对于二分类问题,Sigmoid输出两个值,没有可加性,两个值各自是0到1的某个值,对于一个值 p p p来说, 1 − p 1-p 1−p是它对应的另一个概率。
- 假设预测某个动物是不是狗,那么输出(0,1)代表是狗,输出(1,0)代表不是狗。如果Sigmoid的输出可能是(0.4,0.8),他们相加不为1,即Sigmoid认为输出第一位为1的概率是0.4,第一位不为1的概率是 1 − p = 0.6 1-p=0.6 1−p=0.6,第二位为1的概率是0.8,第二位不为1的概率为0.2。
1.2.2 Softmax
- Softmax函数形式为: S o f t ( x j ) = e x j ∑ k = 1 K e x k , j = 1 , 2 , . . . , K . Soft(x_j) = \frac {e^{x_j}} {\sum \limits _{k=1} ^{K} e^{x_k}} ,j=1,2,...,K. Soft(xj)=k=1∑Kexkexj,j=1,2,...,K.
- 对于二分类问题,Softmax输出两个值,这两个值相加为1。
- 假设预测某个动物是不是狗,那么输出(0,1)代表“是狗”,输出(1,0)代表“不是狗”。如果Softmax的输出可能是(0.3,0.7),代表算法认为“是狗”的概率为0.7,“不是狗”的概率为0.3,相加为1。
2. MSE 损失函数
- 以二分类为例,我们需要预测结果是一个介于[0,1] 的值,以此来表示预测类别为0或为1。因此,分类问题会在 w x + b wx+b wx+b后接一个sigmoid激活函数,将输出压缩到[0,1]之间。
- 如果用MSE loss来训练分类问题,不论预测接近真实值或是接近错误值,梯度都会趋近于0。这也就解释了为何我们需要CE或BCE损失来处理分类问题。
3. DICE 损失函数
- sigmoid配合diceloss,经过one-hot之后,在通道层面实际上是二分类。因为在我one-hot的时候,第一类是背景,就不用计算dice了,从前景开始计算。
四、训练
五、模型验证validate.py
5.1 标签像素值读取
import numpy as np
import cv2
# cv2.IMREAD_GRAYSCALE(0):始终将图像转换为单通道灰度图像;cv2.IMREAD_COLOR(1):始终将图像转换为 3 通道BGR彩色图像,默认方式
original_mask = cv2.imread('/root/autodl-fs/HRA_datasets/train_nii_png/fixed_png/lesion/tr/label/33_0019.png', cv2.IMREAD_GRAYSCALE)
print('original_mask', np.unique(original_mask)) # original_mask [ 0 255]
5.2 标签转换
import numpy as np
import cv2
label = cv2.imread('/root/autodl-fs/HRA_datasets/train_nii_png/fixed_png/lesion/tr/label/33_0019.png', 0)
dst_img_path = './prediction33_0019.png'
print('img_mask', np.unique(label))
label[label == 1] = 128 # 128 85
label[label == 2] = 255 # 255 170
# label[label == 85] = 128
# label[label == 170] = 255
# label[label > 0] = 1 # 病灶置为肝脏
cv2.imwrite(dst_img_path, label)
print("finished !")
5.3 图像读取、格式转换
1. 读取图
# opencv-python
import cv2
# PIL
from PIL import Image
# opencv-python
img = cv2.imread('' ---.jpg'')
img = cv2.imread('' ---.jpg'', flages=cv2.IMREAD_GRAYSCALE) # flags是可选读入模式,如灰度图等,默认为None
# PIL
img = Image.open("---.jpg")
img = Image.open("---.jpg", mode=‘r’ ) # mode只能且默认是‘r’,
img = Image.open("lena.jpg")
img = img.load()
print(img[0,0])
# result:(255, 201, 166)
2. 相互转换
#1.Image对象->cv2(np.adarray)
img = Image.open(path)
img_array = np.array(img)
#2.cv2(np.adarray)->Image对象
# cv2.IMREAD_GRAYSCALE(0):始终将图像转换为单通道灰度图像;cv2.IMREAD_COLOR(1):始终将图像转换为 3 通道BGR彩色图像,默认方式
img = cv2.imread(path)
img_Image = Image.fromarray(np.uint8(img))
3. 保存
# 以npy格式将数组形式保存到二进制文件中,无压缩,占空间大,后续加载数据较快
np.save()
# 从npy,npz等格式加载arrays
np.load()
# npy是以数组形式保存图片数据,用np.load(),训练时,可能需要进行转换。
# 以png,gif等格式存储,占空间小,数据经过压缩,后续加载较慢
cv2.imwrite()
六、模型评价指标
参考文献
[1] Efficient way to one hot encode whole image for semantic segmentation
[2] 深度学习语义分割标签图像独热编码 (one hot encoding)
[3] 【图像分割】医学图像分割多目标分割(多分类)实践
[4] 分类与分割的区别
[5] 深度学习中的图像分类,为什么使用onehot?
[6] np.transpose()函数详解
[7] 【Pytorch】 Dice系数与Dice Loss损失函数实现
[8] pytorch语义分割中CrossEntropy、FocalLoss和DiceLoss三类损失函数的理解与分析
[9] Python中reshape(view)函数参数-1的意思?
[10] 损失函数 | BCE Loss(Binary CrossEntropy Loss)
[11] 多标签和多分类,别再分不清了
[12] 关于pytorch语义分割二分类问题的两种做法
[13] Pytorch中的CrossEntropyLoss()函数案例解读和结合one-hot编码计算Loss


















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









