







目录
一、修改网络
在autodl-fs/u-Mamba-main/U-Mamba/nnunetv2/nets中建立自己的网络模型,也可以复制别人的模型,在其基础上修改为自己的模型。
二、修改训练器
将文件autodl-fs/u-Mamba-main/U-Mamba/nnunetv2/training/nnUNetTrainer/nnUNetTrainer.py 复制一份,重新命名为自己的训练器。
- 修改模型(例如:
UMambaBot); - 修改训练器名(
nnUNetTrainerUMambaBot,后面训练指令用);
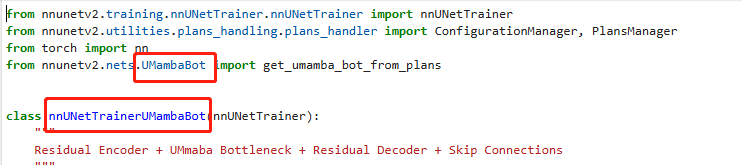
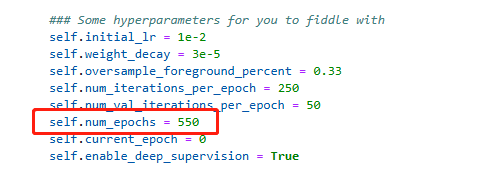
- 修改训练epoch。
在autodl-fs/u-Mamba-main/U-Mamba/nnunetv2/training/nnUNetTrainer/nnUNetTrainer.py中第147行。
三、训练步骤
这个博客写的比较简单,详细参考:nnUNet V2训练-AutoDL
1. 上传、解压baseline代码
- 安装
nnUNet v2:
pip install -e .
- 新建文件夹
data,并在其下新建三个文件夹:
nnUNet_raw
nnUNet_preprocessed
nnUNet_results
- 设置 nnUNet 读取文件的路径:
- 终端输入:
vim ~/.bashrc - 按
insert键,输入下面:
- 终端输入:
export nnUNet_raw="/root/autodl-fs/u-Mamba-main/data/nnUNet_raw"
export nnUNet_preprocessed="/root/autodl-fs/u-Mamba-main/data/nnUNet_preprocessed"
export nnUNet_results="/root/autodl-fs/u-Mamba-main/data/nnUNet_results"
- 按
esc,输入:,输入wq: - 验证是否设置成功:
- 终端输入:
source ~/.bashrc - 依次输入:
- 终端输入:
echo $nnUNet_results
echo $nnUNet_raw
echo $nnUNet_preprocessed
2. 上传数据、解压数据
- 解压数据:
unzip Dataset208_LiTS2017.zip -d /root/autodl-fs/u-Mamba-main/data/nnUNet_raw
- 清内存:
du -sh /root/miniconda3/pkgs/ && rm -rf /root/miniconda3/pkgs/*
- 复制文件:
cp -r Dataset701_AbdomenCT/* U-Mamba/data/nnUNet_raw/Dataset701_AbdomenCT/
- 从一个实例拷贝数据到另一个实例:
- 蒙古B区的数据
autodl-fs/u-Mamba-main,拷贝到内蒙A区autodl-fs/u-Mamba-main; - 蒙古B区开机,蒙古A区无卡开机;
- 需要内蒙A的ssh和密码:如
ssh -p 16999 root@connect.neimeng.seetacloud.com; - 进入内蒙B区的终端,输入下面命令,然后输入内蒙A的密码:
- 蒙古B区的数据
cd /root/autodl-fs/u-Mamba-main/ && tar cf - * | ssh -p 16999 root@connect.neimeng.seetacloud.com "cd /root/autodl-fs/u-Mamba-main && tar xf -"

3. 数据预处理
nnUNetv2_plan_and_preprocess -d 208 --verify_dataset_integrity
4. 训练
- 训练:
nnUNetv2_train 208 3d_fullres all -tr nnUNetTrainerUMambaBot
- 删除npy文件:
rm *.npy
- 中断后继续训练:
nnUNetv2_train 208 3d_fullres all -tr nnUNetTrainerUMambaBot --c
- 如果设置的epoch是500,但是还想继续训练:
- 将
checkpoint_final.pth重命名为checkpoint_latest.pth; - 继续训练,终端输入:
nnUNetv2_train 208 3d_fullres all -tr nnUNetTrainerUMambaBot --c
- 将
- 如果设置的epoch是1000,发现500时就收敛了,暂停后进行推理:
- 将
checkpoint_latest.pth重命名为checkpoint_final.pth; cd到放评价指标代码的文件夹(如evaluation),终端输入:nnUNetv2_predict -i ./data/nnUNet_raw/Dataset208_LiTS2017/imagesTs -o ./evaluation/segs/Dataset208_UMambaBot -d 208 -c 3d_fullres -f all -tr nnUNetTrainerUMambaBot --disable_tta- 或者也不用修改上面的名字,只需要指定
checkpoint_latest.pth即可,如终端输入:
- 将
nnUNetv2_predict -i ./data/nnUNet_raw/Dataset701_AbdomenCT/imagesVal -o ./evaluation/segs/Dataset701_UMambaEnc -d 208 -c 3d_fullres -f all -chk checkpoint_latest.pth -tr nnUNetTrainerUMambaEnc --disable_tta
5. 推理
- 用
保存最后的模型推理:
nnUNetv2_predict -i ./data/nnUNet_raw/Dataset701_AbdomenCT/imagesVal -o ./evaluation/segs/Dataset701_UMambaEnc -d 208 -c 3d_fullres -f all -tr nnUNetTrainerUMambaEnc --disable_tta
- 用
保存最好的模型推理:
nnUNetv2_predict -i ./data/nnUNet_raw/Dataset701_AbdomenCT/imagesVal -o ./evaluation/segs/Dataset701_UMambaEnc -d 208 -c 3d_fullres -f all -chk checkpoint_best.pth -tr nnUNetTrainerUMambaEnc --disable_tta
6. 评价指标
python liver_DSC_Eval.py --gt_path ~/autodl-fs/u-Mamba-main/data/nnUNet_raw/Dataset208_LiTS2017/labelsTs --seg_path ./segs/Dataset208_UMambaBot --save_path ./Dataset208_UMambaBot.csv
- 评价指标平均值计算:
=ROUND(AVERAGE(B2:B39),4) *100&"±"&ROUND(STDEV(B2:Bx), 4) *100
=ROUND(AVERAGE(B2:B39),4) *100&
7. 安装nnUNet v2 出现问题-AutoDL
- 当你将一个服务器的环境和文件转移到另一个服务器时,在新的服务器会出现问题:
- 安装nnUNet v2 的文件读取是从autodl-fs/data/LightM-UNet-master/lightm-unet,而不是从autodl-fs/LightM-UNet-master/lightm-unet,可以看到多出来一个文件data
- 在进行数据预处理时,会出现找不到autodl-fs/LightM-UNet-master/data/nnUNet_raw中的nii文件
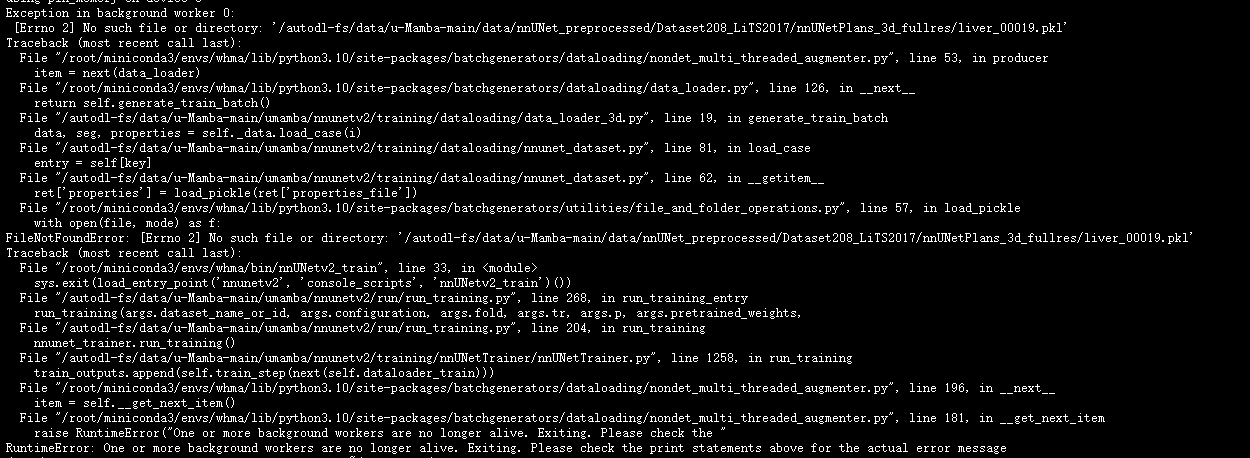
- 原因:
我们在从其他服务器导入环境和文件时,会自代入之前的文件存储 - 解决方法:
如果你原来安装的是LightM-UNet-master,那么我们可以先安装原有的nnUNet v2(安装的适合可能会出错),然后再回到文件夹LightM-UNet-master/lightm-unet重新安装nnUNet v2 - 安装nnUNet v2(出现错误,不用管,主要是为了让从头安装LightM-UNet,让nnUNet v2替换原服务器的安装环境)
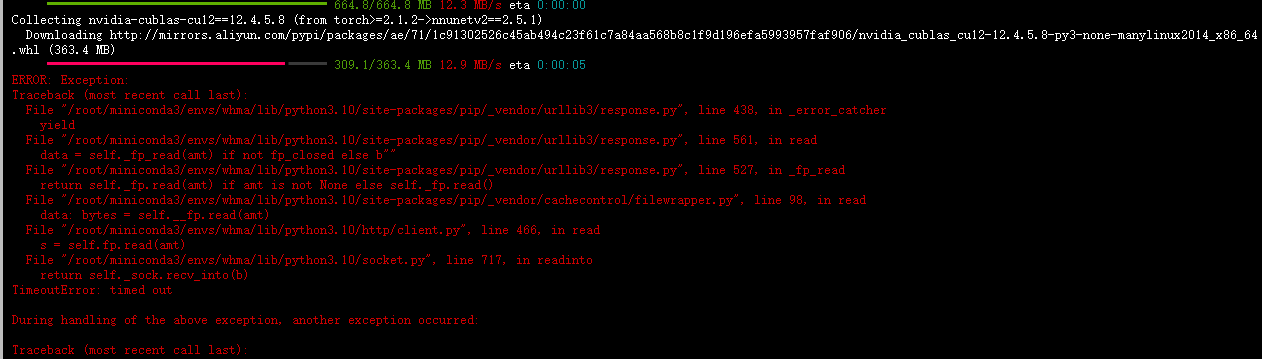
- 安装LightM-UNet
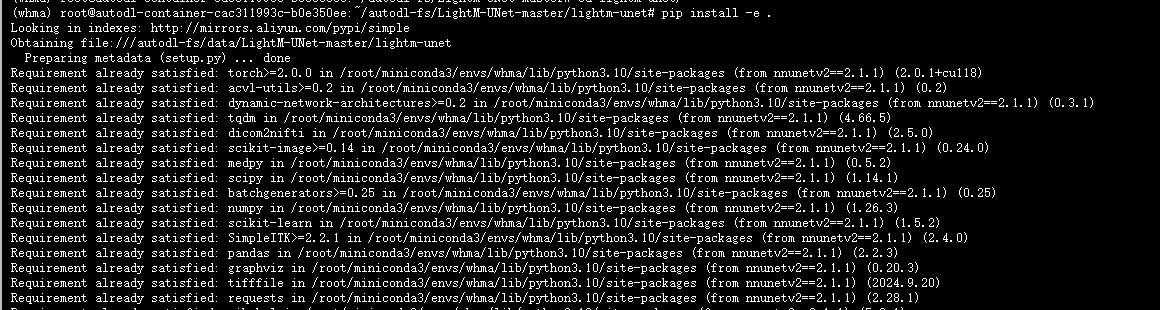
参考博客:
[1] UUNet训练自己写的网络
[2] nnUNet v2版本 如何训练自己设计的网络
[3] nnUnetV2:自定义网络


















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









