







一、引言:为什么需要模型蒸馏?
在深度学习领域,大型模型(如 BERT、GPT 系列)凭借强大的参数规模实现了惊人的性能,但也带来了部署难题:高算力需求、长推理时间、内存占用大。
模型蒸馏(Model Distillation)正是为解决这些问题而生,它通过 “知识迁移” 让小模型学习大模型的精华,在保持性能的同时大幅提升效率。本文将深入解析模型蒸馏的原理、流程与实战应用。
二、模型蒸馏核心原理:知识迁移的艺术
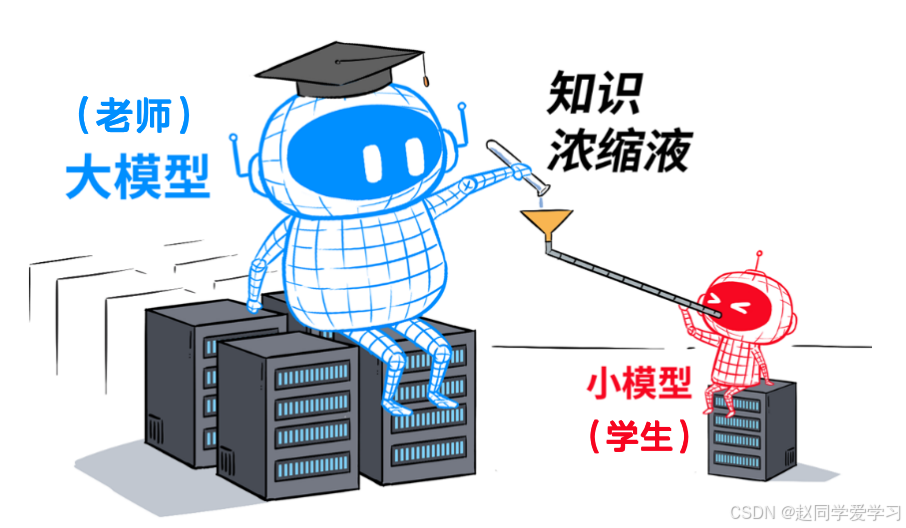 模型蒸馏的核心思想是 “教师 - 学生” 架构:
模型蒸馏的核心思想是 “教师 - 学生” 架构:
- 教师模型(Teacher Model):性能强大但复杂的大模型,作为知识源。
- 学生模型(Student Model):轻量级小模型,学习教师模型的知识。
2.1. 知识传递的关键 —— 软标签(Soft Label)
传统训练使用硬标签(如分类任务中的 0/1 标签),而蒸馏引入软标签:教师模型输出的概率分布(如 Softmax 结果)。
通过温度参数(Temperature)调整概率分布的平滑度,让学生模型学习到更丰富的类别关联信息。
公式示例:
软标签计算: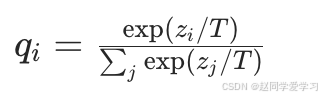
其中 ![]() 是教师模型输出的 logits,T 为温度参数。
是教师模型输出的 logits,T 为温度参数。
2.2. 损失函数设计
蒸馏损失通常由两部分组成:
- 蒸馏损失:衡量学生模型与教师模型软标签的差异(如 KL 散度)。
- 监督损失:学生模型对硬标签的传统损失(如交叉熵)。
最终损失:![]()
三、模型蒸馏实施流程
1. 教师模型准备:训练或加载一个高性能的预训练模型。
2. 学生模型构建:设计轻量级网络结构(如 MobileNet 替代 ResNet)。
3. 蒸馏训练:
- 输入数据到教师模型,获取软标签。
- 学生模型同时学习软标签和硬标签,优化损失函数。
4. 推理部署:蒸馏后的学生模型单独使用,兼顾速度与精度。
四、模型蒸馏应用场景
- 移动端部署:手机 APP 集成 AI 功能,如轻量化图像分类模型。
- 边缘计算:在硬件资源有限的设备(如摄像头、传感器)上运行推理。
- 知识压缩:将复杂模型的知识浓缩到小模型,降低训练成本。
- 增量学习:利用旧模型蒸馏新知识,避免重复训练大模型。
五、实战:用 PyTorch 实现简单模型蒸馏
以图像分类为例,演示教师模型(ResNet18)向学生模型(MobileNetV2)蒸馏:
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import transforms, datasets
# 定义教师与学生模型
teacher = models.resnet18(pretrained=True).eval()
student = models.mobilenet_v2(pretrained=False)
# 损失函数与优化器
criterion_kl = nn.KLDivLoss(reduction="batchmean")
criterion_ce = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(student.parameters(), lr=0.001)
# 模拟数据加载
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True)
# 蒸馏训练循环
T = 2.0 # 温度参数
alpha = 0.7 # 损失权重
for epoch in range(10):
for images, labels in dataloader:
# 教师模型推理(不更新梯度)
with torch.no_grad():
teacher_logits = teacher(images)
teacher_soft = torch.softmax(teacher_logits / T, dim=1)
# 学生模型推理
student_logits = student(images)
student_soft = torch.softmax(student_logits / T, dim=1)
# 计算损失
loss_kl = criterion_kl(torch.log(student_soft), teacher_soft)
loss_ce = criterion_ce(student_logits, labels)
loss = alpha * loss_kl * (T ** 2) + (1 - alpha) * loss_ce
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
print("蒸馏训练完成!")
六、总结:模型蒸馏的价值与未来
模型蒸馏让 AI 模型在 “性能” 与 “效率” 之间找到平衡,是推动 AI 落地的关键技术。
随着边缘计算、物联网的发展,模型蒸馏的应用场景将更加广泛。
关注我,后续将分享更多AI知识,一起探索轻量化 AI 的无限可能!


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











