







 本文介绍了词嵌入技术,如何通过无监督学习将单词转换为向量表示,以及CBOW和Skipgram方法在捕捉单词上下文中的应用。重点讲解了使用预测模型预测文本中单词的概率,以及如何通过权值共享保持多词输入的向量一致性。
本文介绍了词嵌入技术,如何通过无监督学习将单词转换为向量表示,以及CBOW和Skipgram方法在捕捉单词上下文中的应用。重点讲解了使用预测模型预测文本中单词的概率,以及如何通过权值共享保持多词输入的向量一致性。
ppt来自于李宏毅老师的讲解视频:
单词向量表示:
1可以用独热码(占用空间太大,并且单词之间的关系没有体现)
2分类后词嵌入(减少空间,相同类型的向量更加接近)
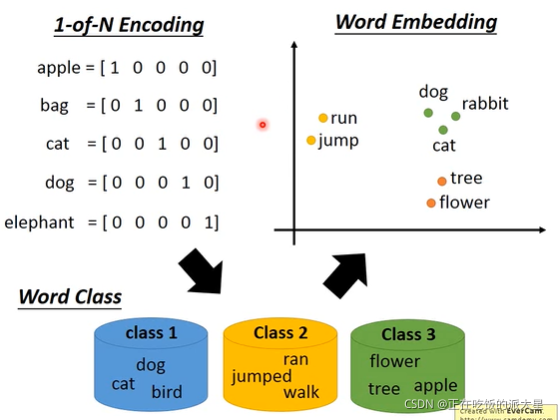
词嵌入
首先词嵌入是无监督学习,输入单词输出对应向量表示。
词嵌入中需要利用单词的上下文
1:count based
两个单词如果频繁的一起出现,向量会接近
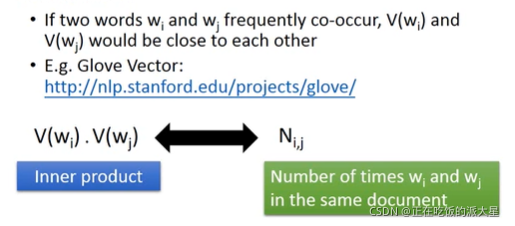
2:prediction based
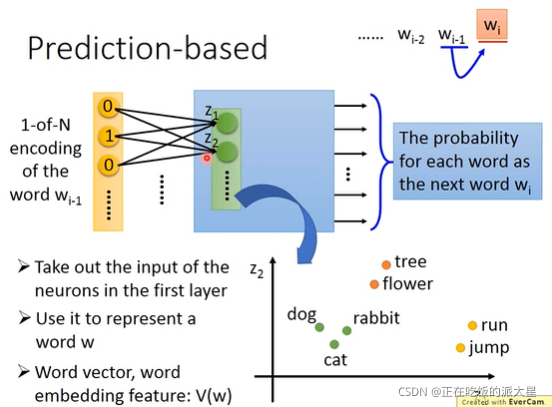
处理的是一个句子 其中wi代表的是一个单词
每次输入一个单词的独热码向量,输出的是概率向量,每一位代表对应单词的概率。
模型内部,第一层作为对应单词的词向量。
例如输入的是[0,0,1,0,0]经过第一层的权值相乘得到第一层为[0.2,0.5,0.4]
这个向量便是对应词向量。需要注意词向量一般比独热向量短。
这样训练后,第一层网络就可以作为嵌入层了。
同时,由于文本预测需要考虑较多的上下文,每次可以输入多个单词独热向量,但是要注意:不同的独热向量中相同单元和对应嵌入层单元之间的权值要相同。
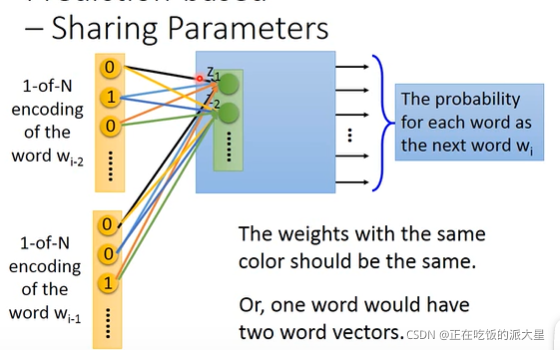
设W为输入层和嵌入层的权重矩阵,那么可以将多个单词的独热向量相加后输入,获得多个单词的词向量。
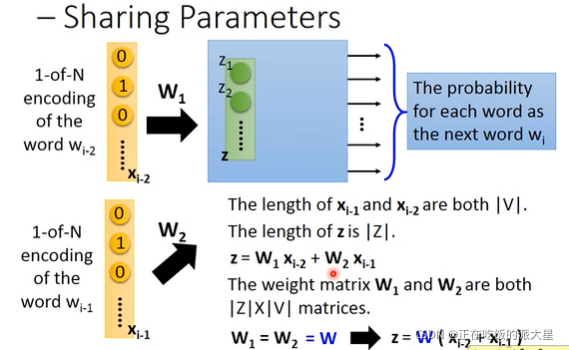
但是需要注意的是W1和W2相同,这就需要给W相同的初始值,并且梯度更新的时候需要额外操作来保证相同,即每次更新的值相同:
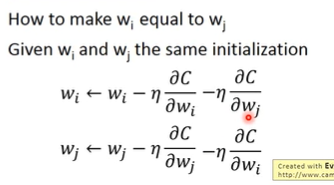
训练方法
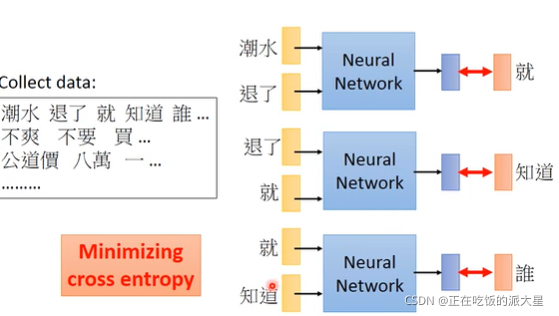
基础方法:
按照句子的顺序依次输入,获得独热输出,减小交叉熵。
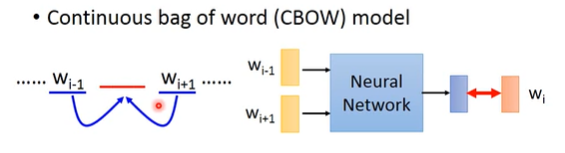
CBOW方法:
用前后两个词获取中间的词
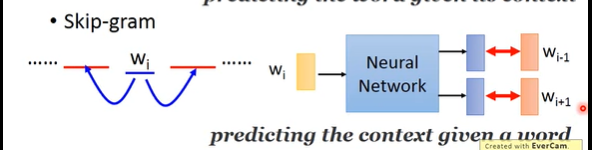
Skip gram:
用中间的词预测前后的词

















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









