







文章目录
前言
本章我们将介绍关于自然语言文字是如何输入到模型中的,自注意力机制(self-attention)的相关知识,以及RNN,LSTM,Bert等模型。
文字类输入
我们常用的输入数据类型有,数字,图片,文字等,前面两种我们在之前的文章中已经有所介绍并且真实使用过了,而本章我们则要说明文字类的输入数据,模型是如何处理的。
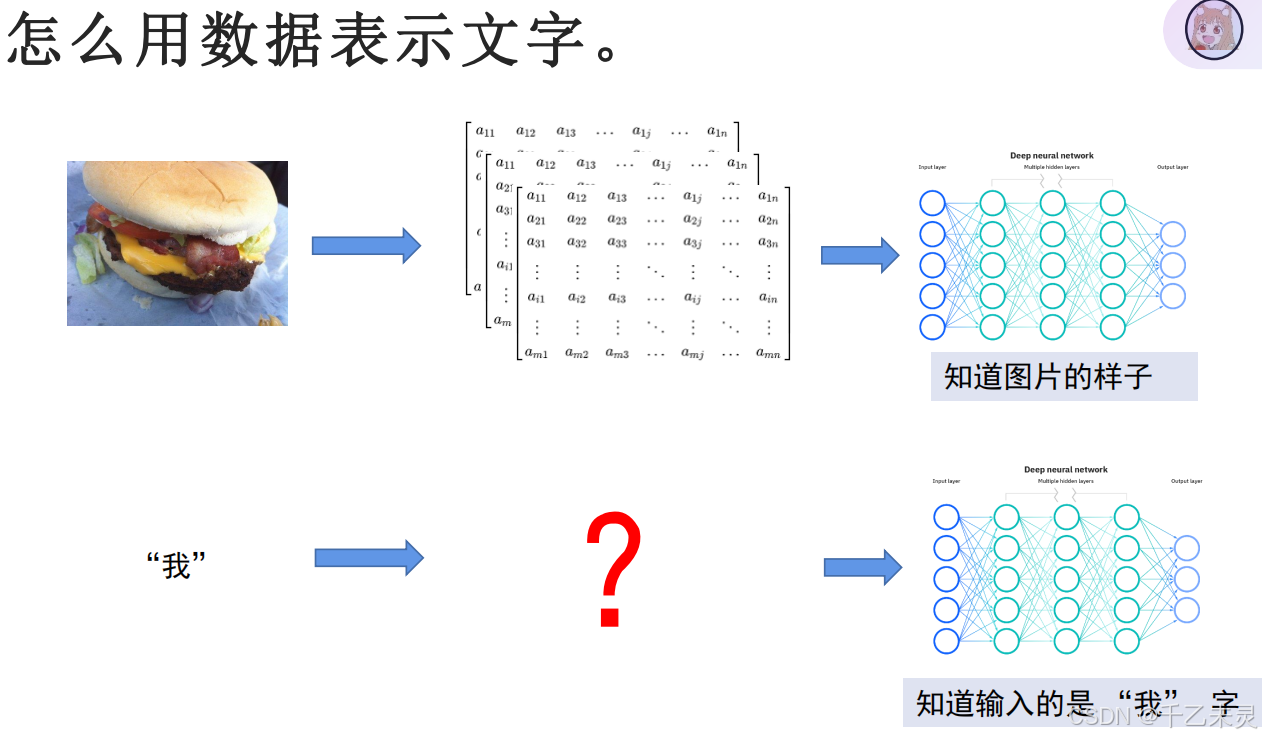
与图片理念差不多,我们处理输入的思路都是,将输入的内容转化为张量,但与图片本质就是矩阵不同,文字并不是这种数据模式。那我们该如何解决这些问题呢?使用独热编码(One-hot Encoding),将每一个文字进行映射,以这种方式把编码转化为向量。
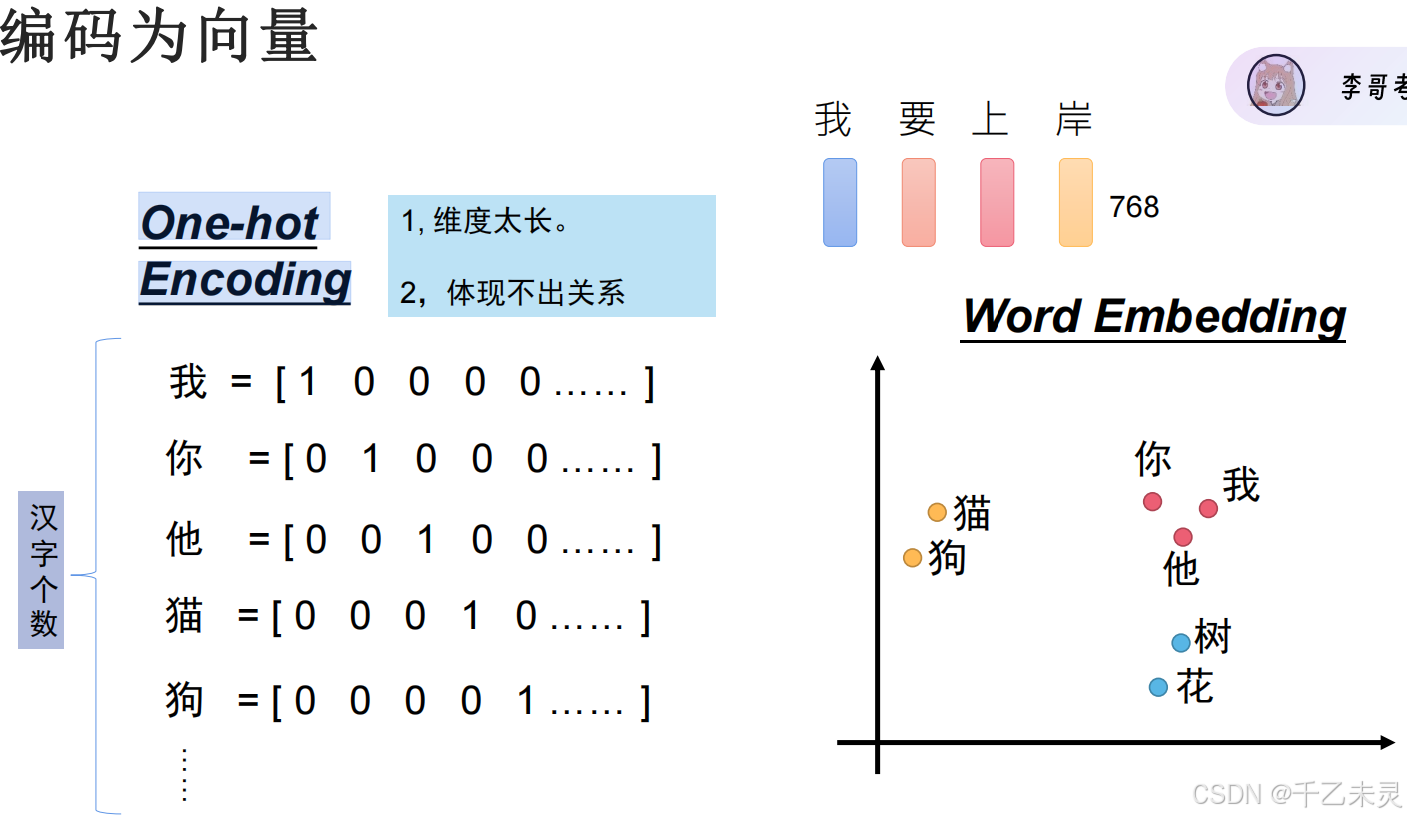
但用这种方式依旧会引发一些问题,比如,无论是汉字或者英文单词,它们的文字总量都是较大的达到几万个,在处理文本数据时,就可能导致计算效率低下,内存占用过高和模型参数爆炸等问题。想要解决这个问题也很简单,还是要用到我们的老朋友全连接,通过建立一层嵌入层(Embedding layer)将高维稀疏的one-hot向量映射成低维稠密的连续向量。
除此之外,还有一种叫做子词分词(Subword Tokenization),这种方法的思路是将词拆分为更小的子词单元(如前缀/后缀等),减少词汇规模。如,原始词:“low”, “lower”, “newest”,子词单元为子词:“low”, “er”, “est”, “new” → 词汇表大小从4词降为4子词。但这个方法并不是本章重点,故不会再进一步展开讨论。

注意,包括符号也有对应编码。

文字类输出
输出类型
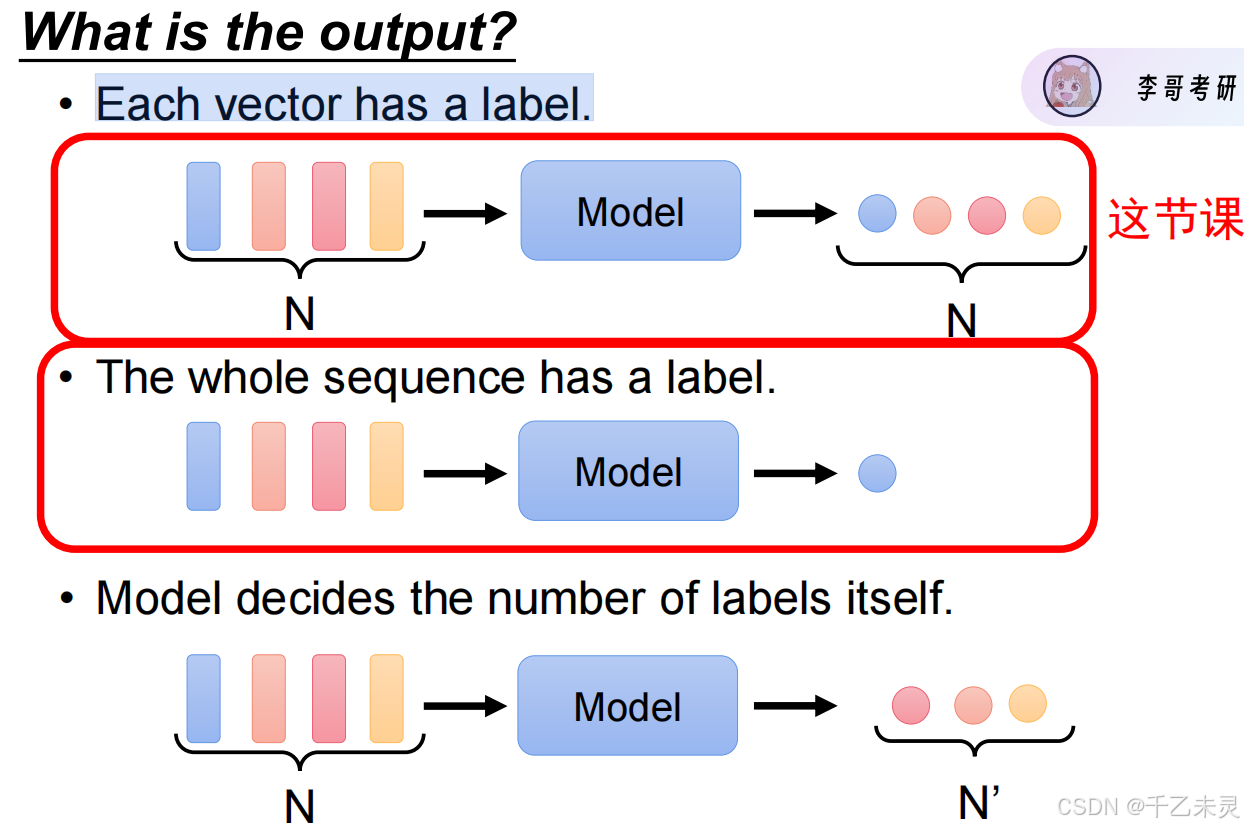
语言类输出主要分为三类,一个向量对应一个标签;对整句设置一个标签;还有一种是模型自行决定标签的数量。本章,我们主要讲解前两种。
假如有个词性识别任务,可以根据各个字的输入来判断每个字的词性。
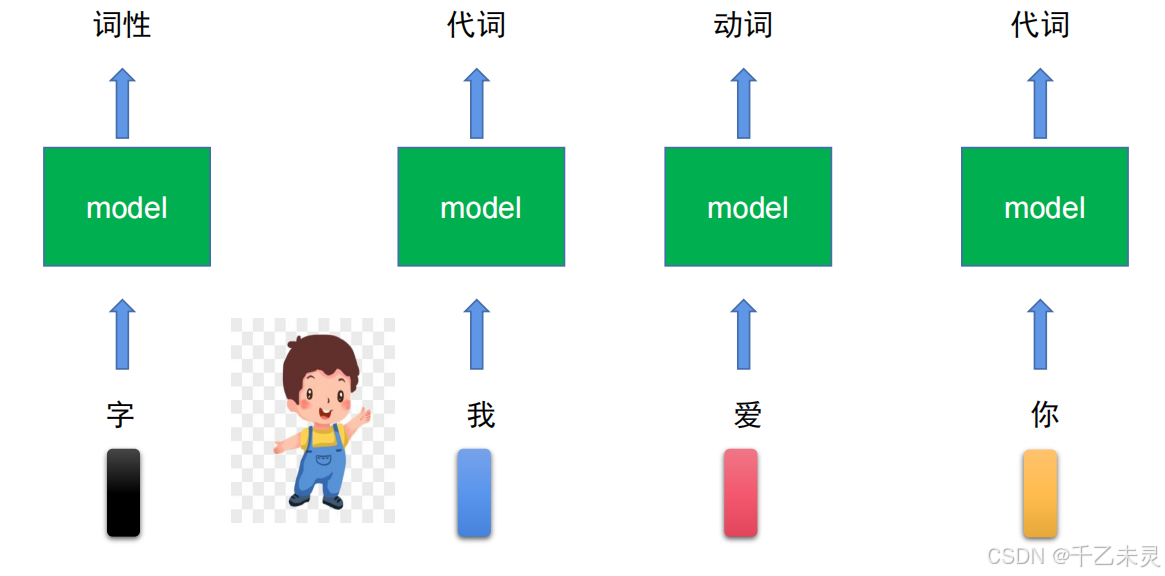
乍一看似乎没有问题,但如果碰到一词多义的问题呢?下图中,一个爱字两个意思,can这句经典英文绕口令含义层次更多。这么看来,简单的对每个单词进行“贴牌”定义,似乎过于僵硬无法灵活面对各种使用场景,那么我们就得开始考虑前后文关系。
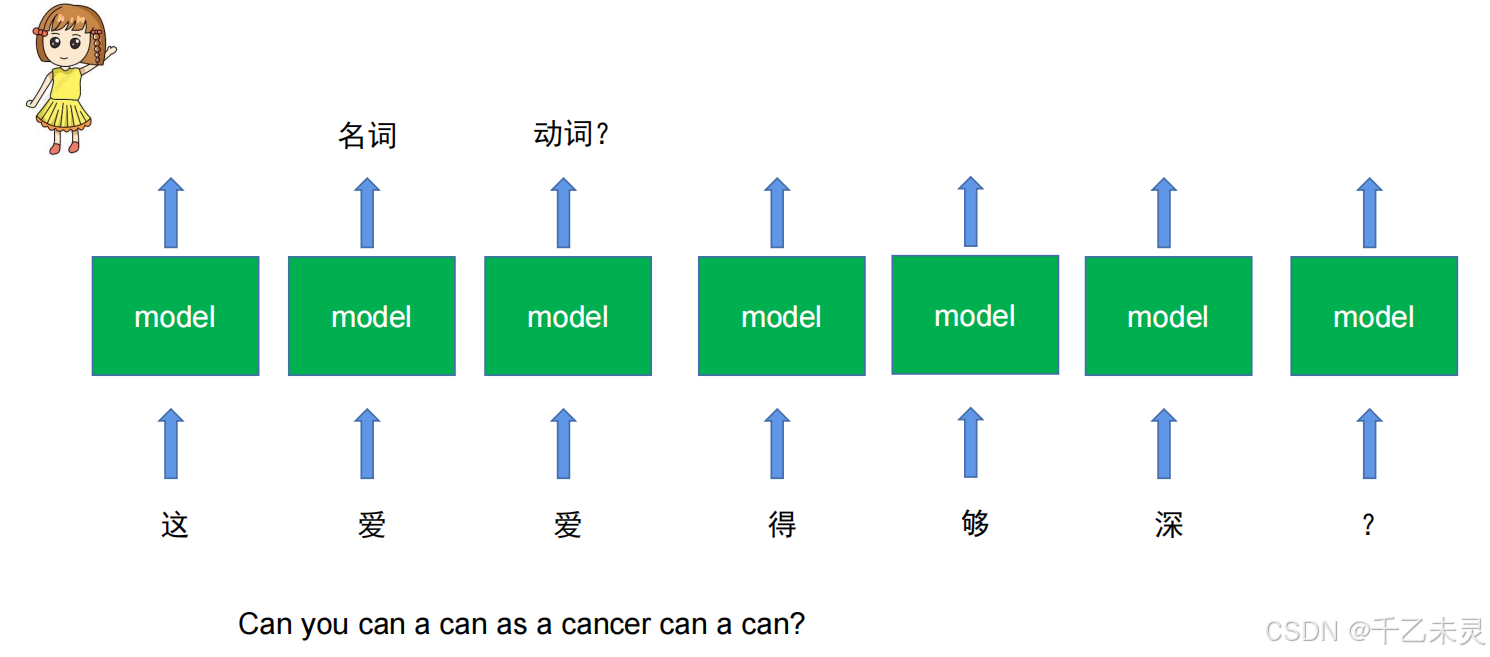
上下文模型
在循环神经网络(Recurrent Neural Network, RNN)模型中,通过使用一个记忆单元将上文内容传递给下文,方便下文结合判断。可以理解为,想象你在阅读一本书,每读一个单词时,大脑会记住前文的内容(隐藏状态),帮助理解当前单词的含义。RNN通过类似机制建模序列上下文。
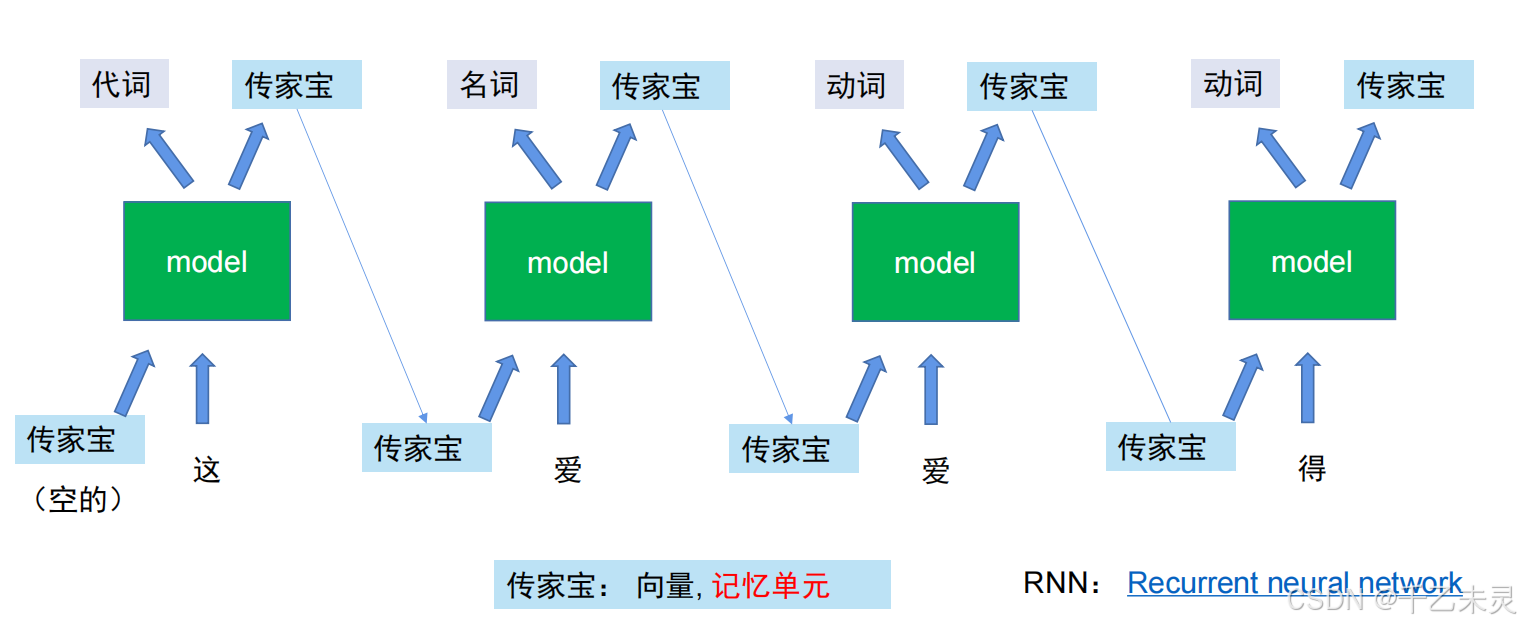
但是,除去在中长序列中表现不佳,可能会导致梯度消失或爆炸外,RNN也无法保证每次传递到记忆单元中的内容都是有用数据或正确数据,于是专门解决这些问题的LSTM出现了。
长短期记忆网络(Long Short-Term Memory, LSTM)是一种特殊的循环神经网络(RNN),专门设计用于解决传统RNN在处理长序列时面临的梯度消失/爆炸问题。通过引入门控机制和记忆细胞,LSTM能够有效捕捉长距离依赖关系,成为自然语言处理、时间序列预测等任务的重要工具。
LSTM的核心是通过门控单元控制信息流动,包括选择性遗忘,选择性记忆,选择性输出。可以理解为想象你正在阅读一本小说,LSTM就像一个智能笔记系统:
遗忘门:擦除与当前情节无关的旧笔记(例如忘记前几章的角色细节)。
输入门:记录当前章节的关键信息(例如新出现的反派角色)。
输出门:根据当前情节需要,选择笔记中的相关内容辅助理解(例如回忆前文伏笔)。
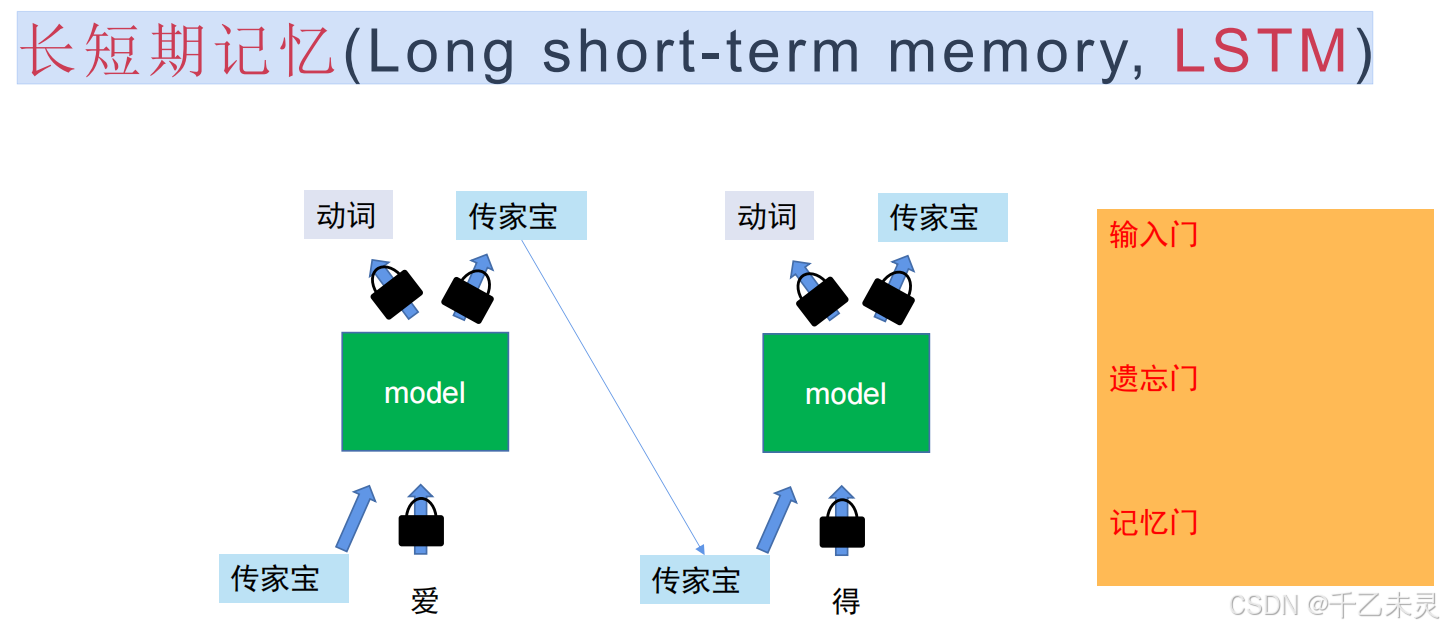
虽然LSTM看起来功能已经十分强大了,但是在现在这个追求效率的年代,你的效率太慢了也是一个无法弥补问题。只能串行不能并行的模式会给使用者日常生活中,增加很多很多的时间成本,于是可以并行处理的自注意力机制以及transformer架构便应运而生。
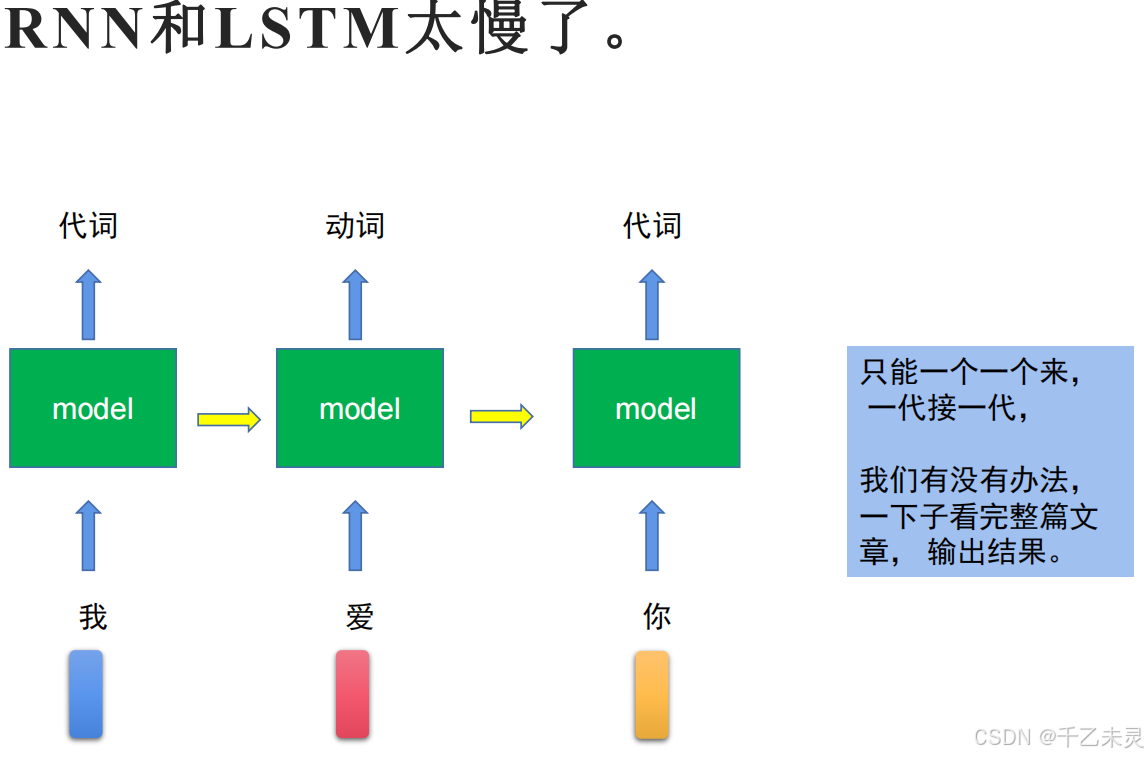
自注意力机制(Self-Attention)
什么是自注意力机制
为了解决无法并行的问题,我们就要引入自注意力机制了。自注意力(Self-Attention)是一种用于序列建模的核心机制,尤其在Transformer模型中被广泛应用。它通过动态计算序列中不同位置之间的相关性,捕捉长距离依赖关系,从而提升模型对上下文的理解能力。
自注意力的核心是让序列中的每个元素(如句子中的单词)与其他所有元素进行交互,根据其重要性分配权重,从而更新自身的表示。例如,在句子“猫吃鱼”中,“吃”这个动词会关注“猫”和“鱼”,而自注意力机制能自动学习这种关联。
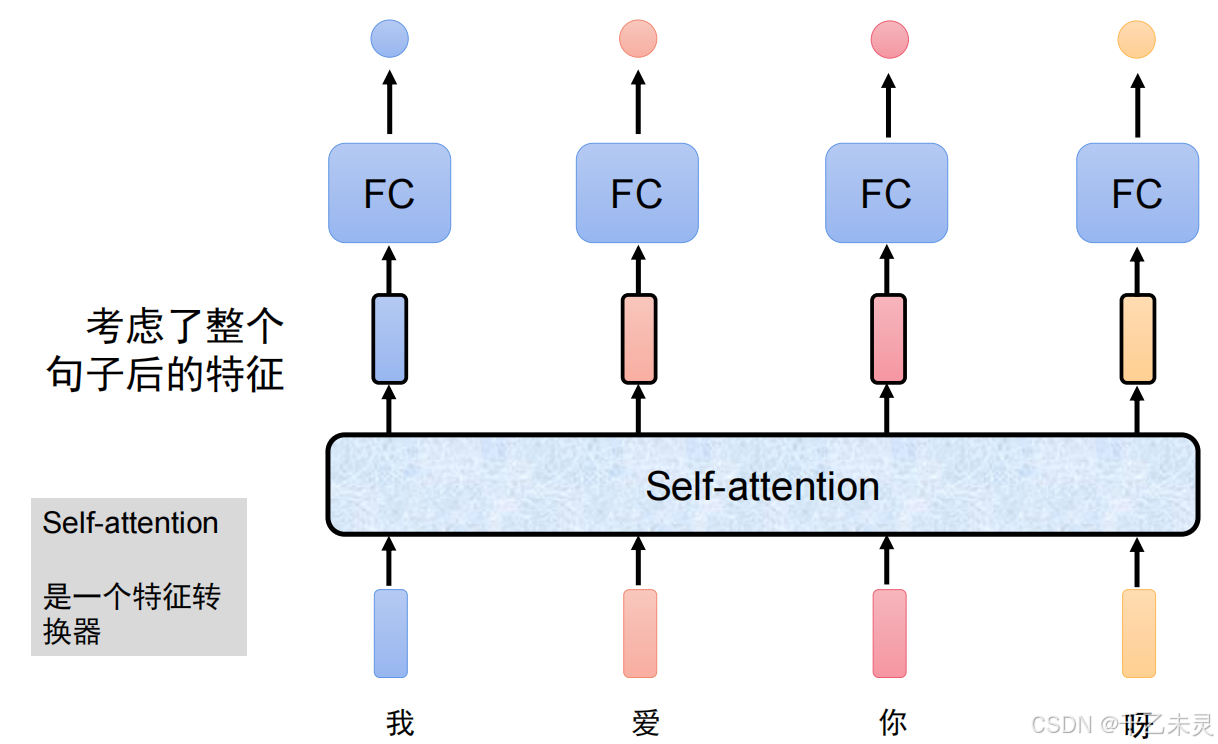
你可以把自注意力机制理解为一个特征转换器(一般不改变数据维度),数据经过特征转换器之后会生成一个特征,该特征不仅会考虑到自己,同时还会考虑到其他所有数据,最后特征进入分类头,得到输出。在剖析原理之前,我们要先搞清楚一个概念,什么是注意力?顾名思义,“我应该多么关注某件事?”,转换成我们常用的说法,就是对每个数据的权重分配。
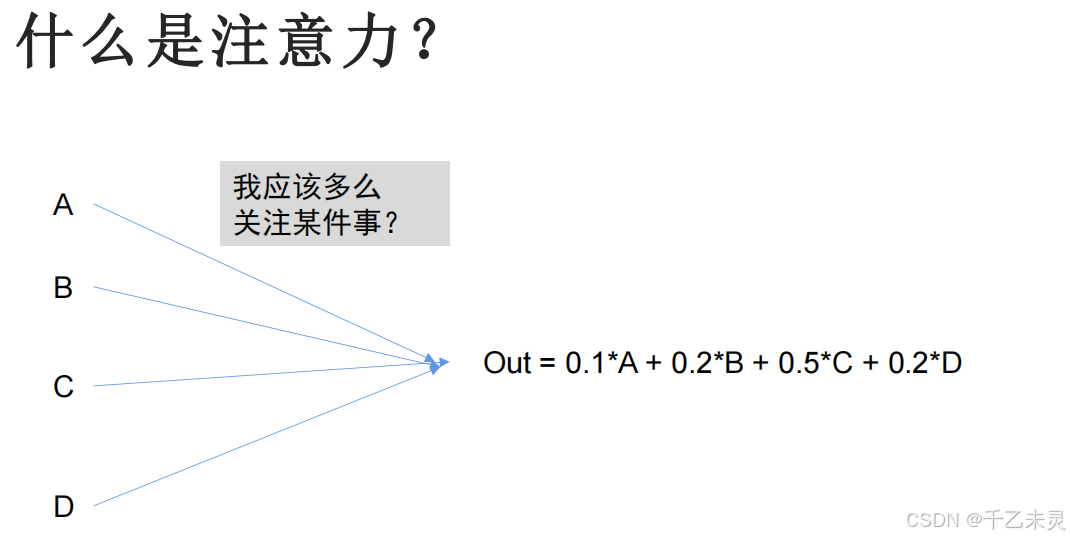
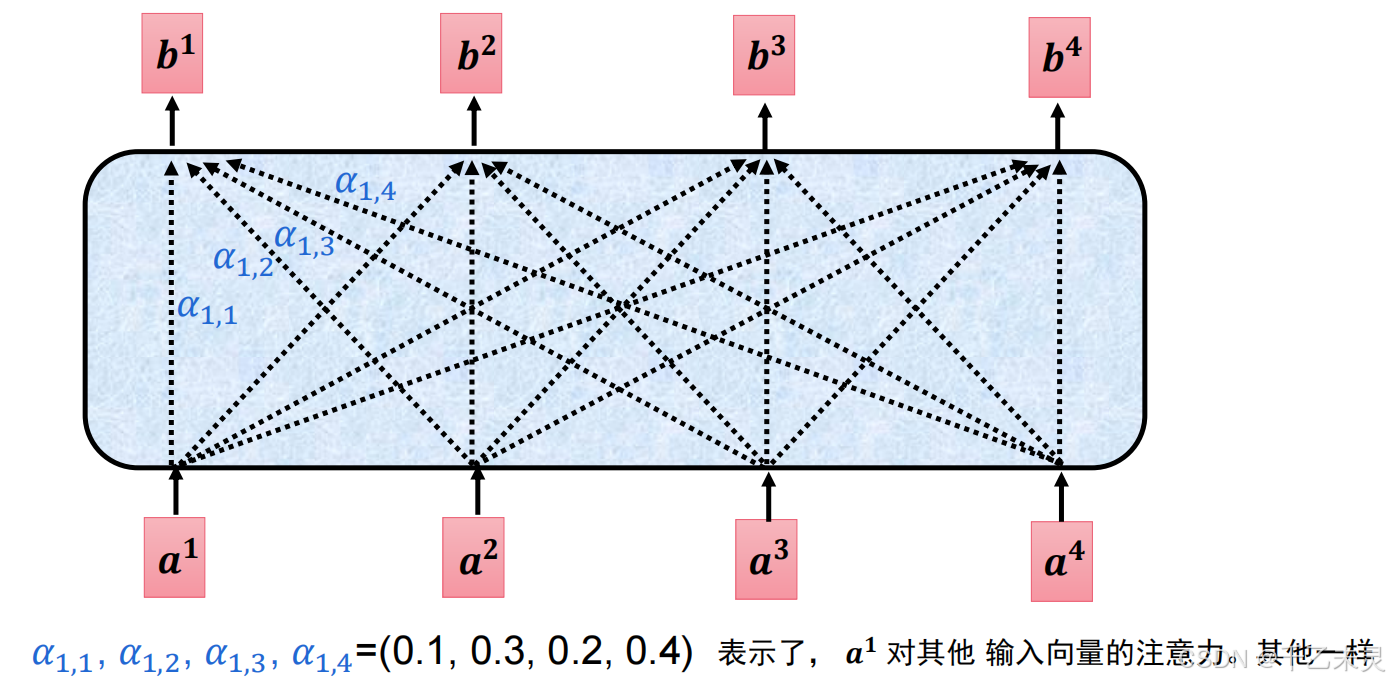
理解了注意力的感念之后,下一步就是探究注意力的计算方法。一开始有一种想法,要求某两个字直接进行点乘,得出结果通过概率化后,就是双方的注意力了。那么问题就来了,这种算法得出的值过于静态化,永远是个定值。
所以,为了更加灵活应用,我们添加了两个“工具”。
Q与K
查询Q(query):当前元素的“提问”向量,用于与其他元素比较。
键K(key):其他元素的“索引”向量,用于匹配查询。
Q和K负责计算输入序列中不同位置之间的关联程度。通过Q和其他元素K的点乘,得出其他元素的注意力分数(Attention Scores),这些分数经过softmax归一化后,表示每个位置对其他位置的关注权重。
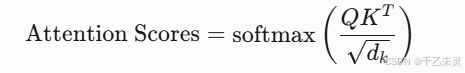
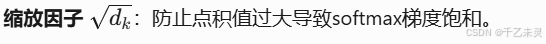
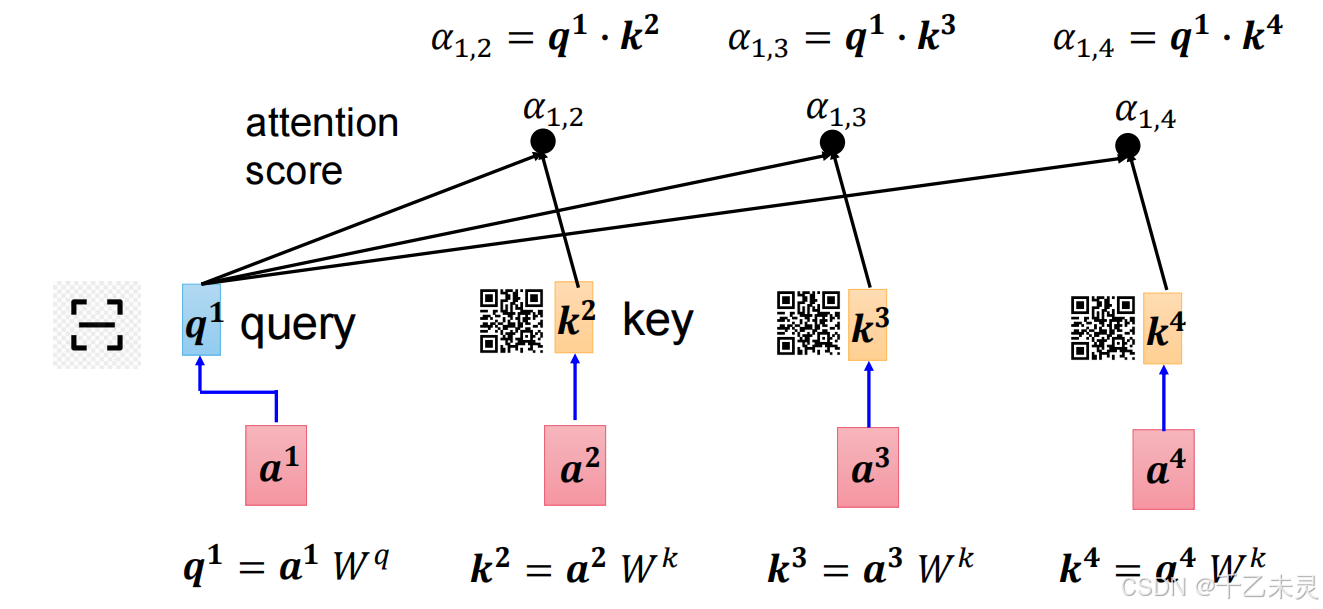
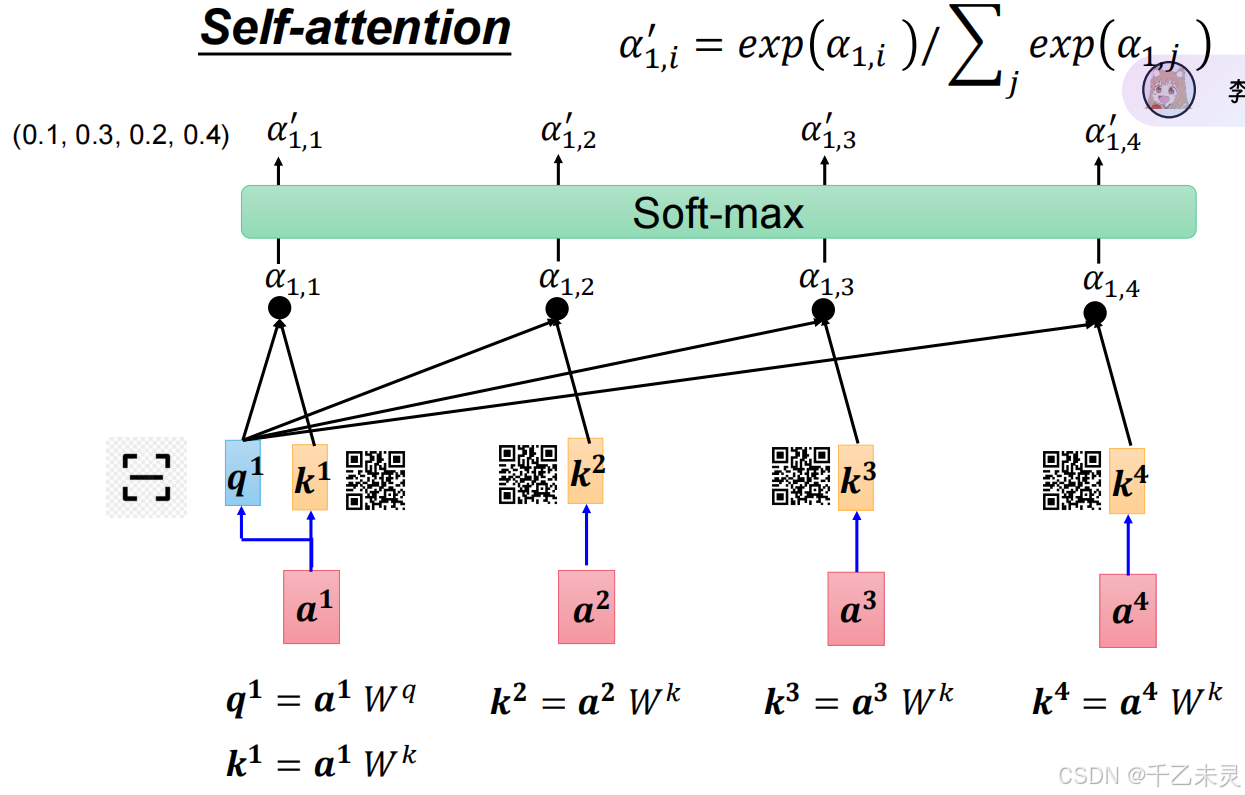
按照惯例,我们又要提出问题了。只用Q,K就足够了吗?当然不够,利用Q,K的计算,我们可以获取元素之间的匹配相关性,但无法了解各个元素的实际存储内容。用个极端例子:
假设我们有一个句子:“猫吃鱼”,“吃”对“猫”的权重为0.3,对“鱼”的权重为0.7。
输出的“吃” = 0.3ד猫”的原始向量 + 0.7ד鱼”的原始向量。
这里包含两个问题
- 原始输入可能包含大量无关特征(例如词性标签、字母大小写),这些特征就会成为噪声,对真实结果产生偏差。
- 模型无法学习到“吃”需要关注“鱼”的语义(如“食物”),而不是“鱼”的词性或位置编码。
- 输出退化为原始输入的加权平均,无法学习到任务相关的特征变换。
为了解决这个问题,我们就需要引入第三个变量V。
Q、K、V
**值(Value)**:其他元素的“内容”向量,用于加权聚合。
我们先看一下最终的计算公式:
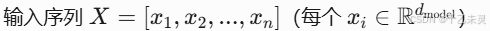
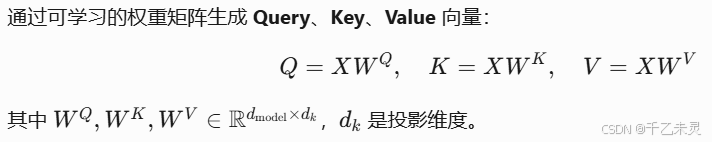

公式有些摸不到头脑是吧?我们来用类比举例解释一下,可以将 Q、K、V 理解为一种 “搜索-检索”过程:
-
Q:提出一个问题(例如:“哪些词与当前词相关?”)
-
K:提供索引标签(例如:“我有关于主语的标签”)
-
V:存储实际内容(例如:“我的内容是动词‘吃’的具体语义”)
如果只有Q和K,你只能知道哪些位置需要关注(例如:动词“吃”需要关注名词“鱼”),但无法获取具体的语义信息。
但加入了V之后,你能从相关位置提取具体的语义内容(例如:“鱼”被“吃”这个动作修饰),从而生成更准确的上下文表示。
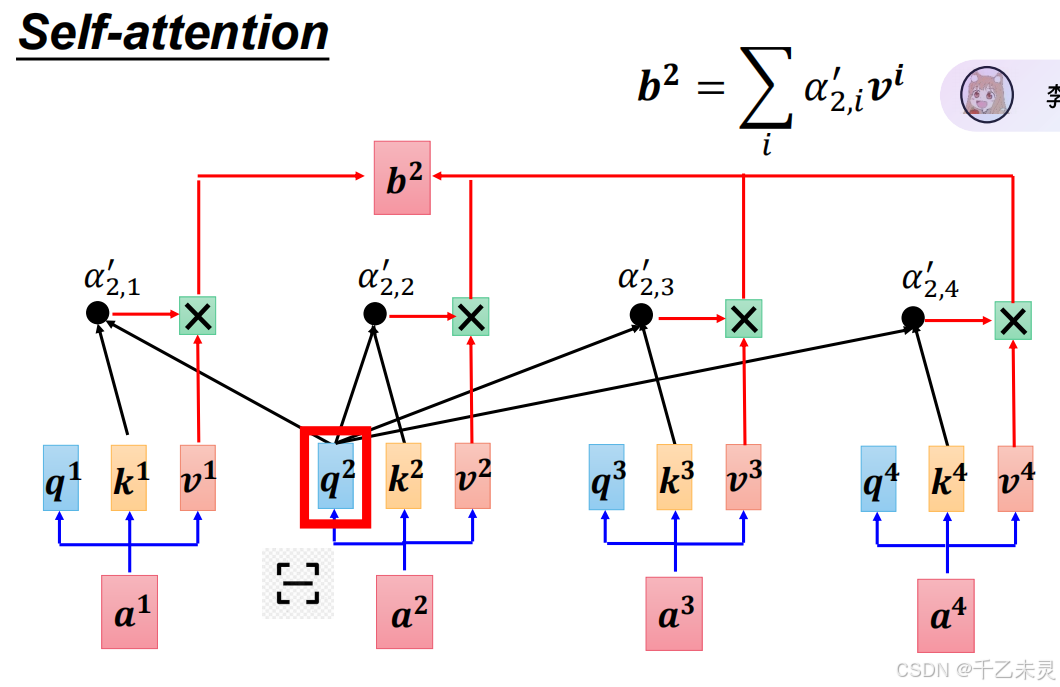
V的作用: -
Q/K 负责“关注哪里”,V 负责“提取什么”,二者分工明确,避免特征干扰。
-
独立的 w v w^{v} wv允许模型动态调整被聚合的信息,适应不同任务需求。
-
每个头可以学习不同的 V 投影,捕捉多样化的语义或语法关系(如主谓、修饰等)。
-
通过 w v w^{v} wv过滤无关特征,提升聚合质量。
self-attention计算过程
上文我们讲述了,通过Q、K、V的使用,我们完成了每个元素对其他元素的特征提取,弥补了RNN和LSTM速率方面的缺陷。
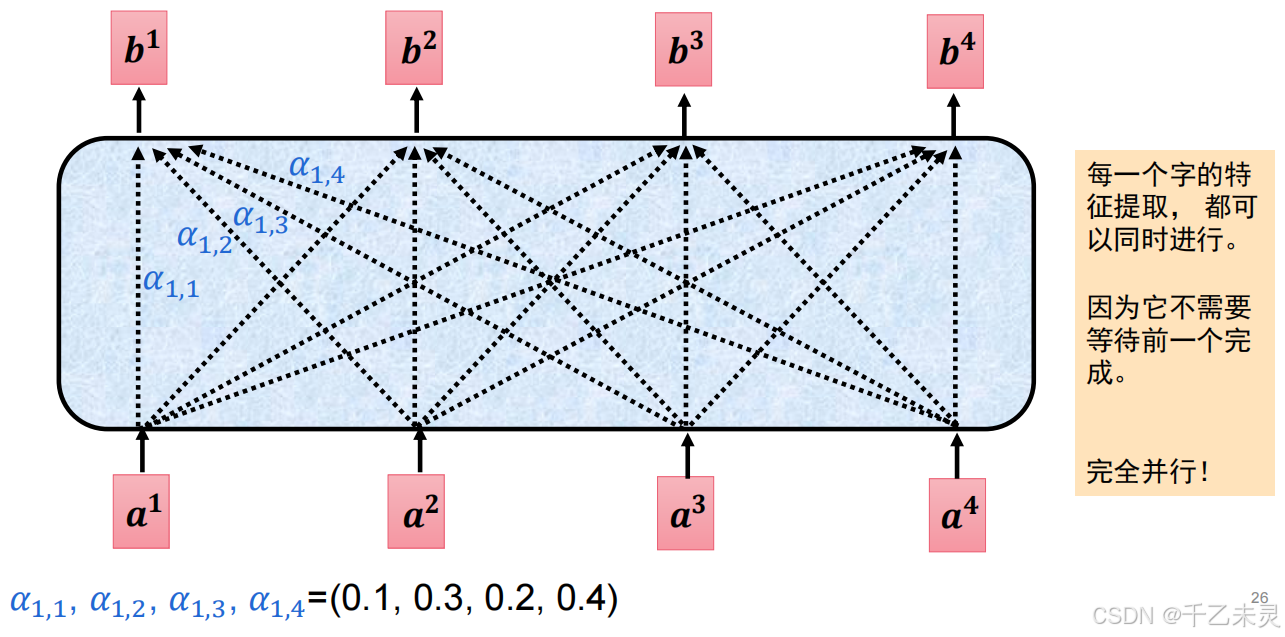
现在,我们来具体探究一下,数据输入self-attention中后的运算流程,注意过程中的参数变化。在计算前,我们要明确一个点,抛开缩放因子,运算过程中输入的变量说
w
q
w^{q}
wq
w
k
w^{k}
wk
w
v
w^{v}
wv三者。除此之外,并没有引入其他变量。
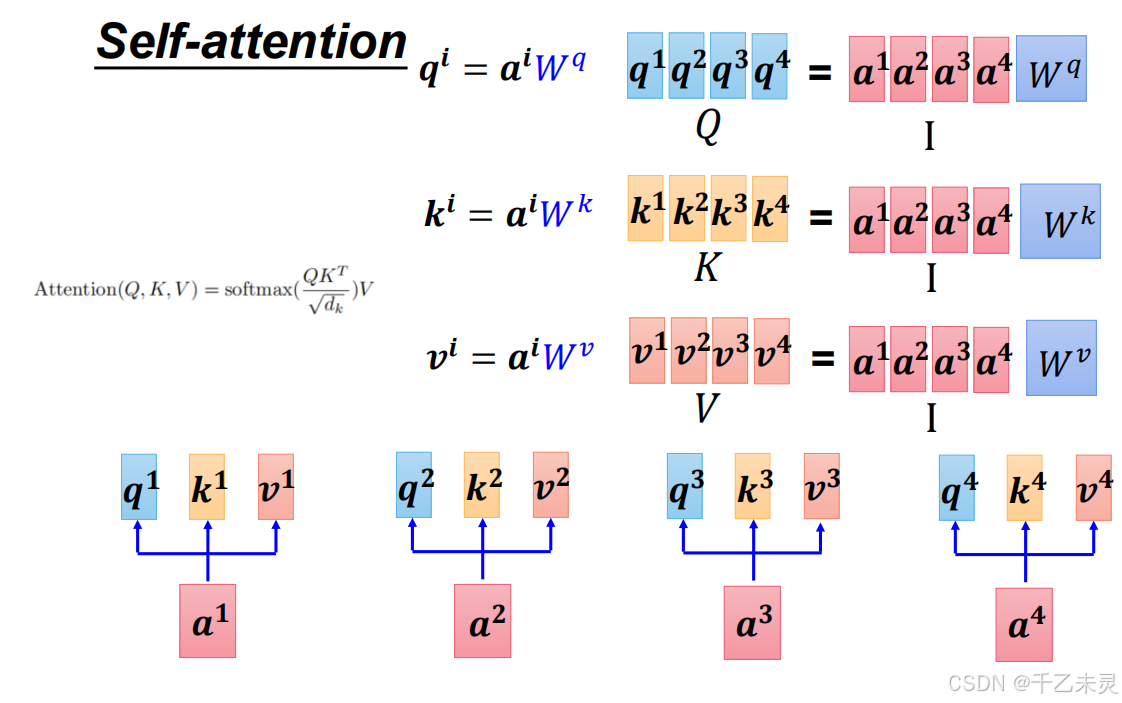
首先,由输入向量与
w
q
w^{q}
wq
w
k
w^{k}
wk
w
v
w^{v}
wv分布相乘,生成Q,K,V。
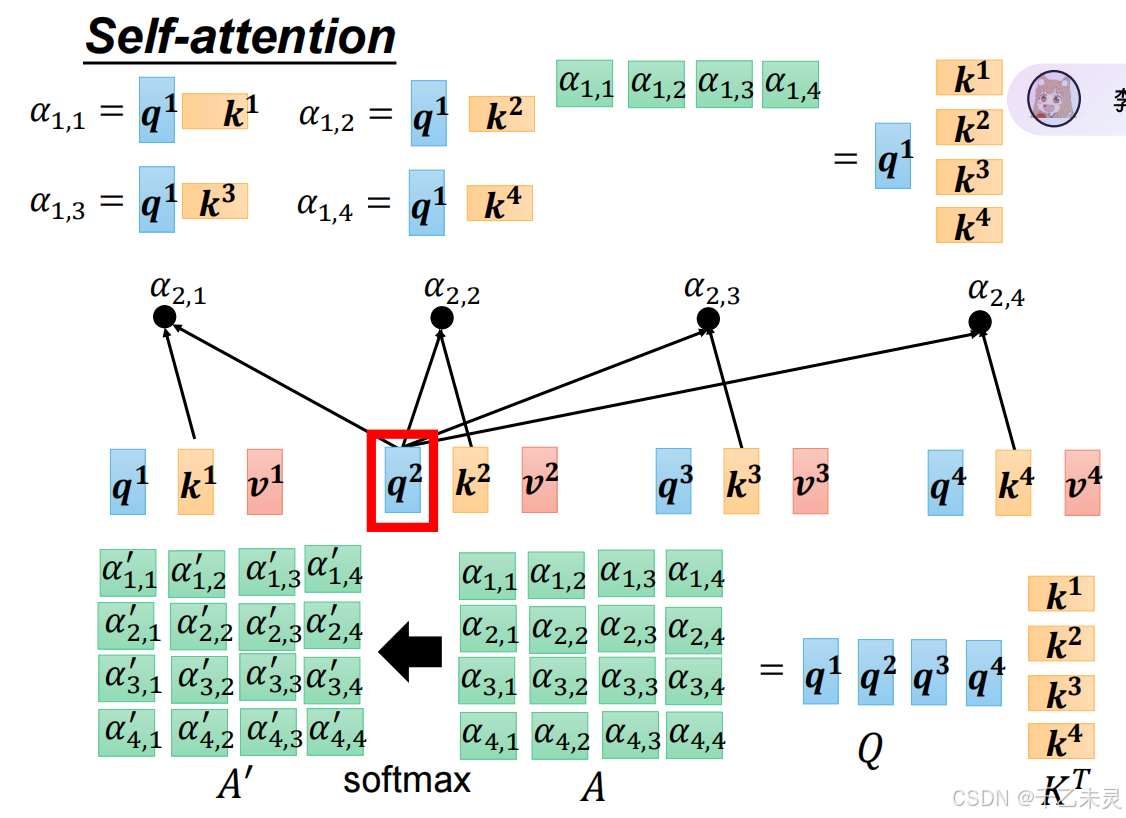
之后,由Q与K转置相乘,得到注意力分数,将注意力分数进行归一化处理。
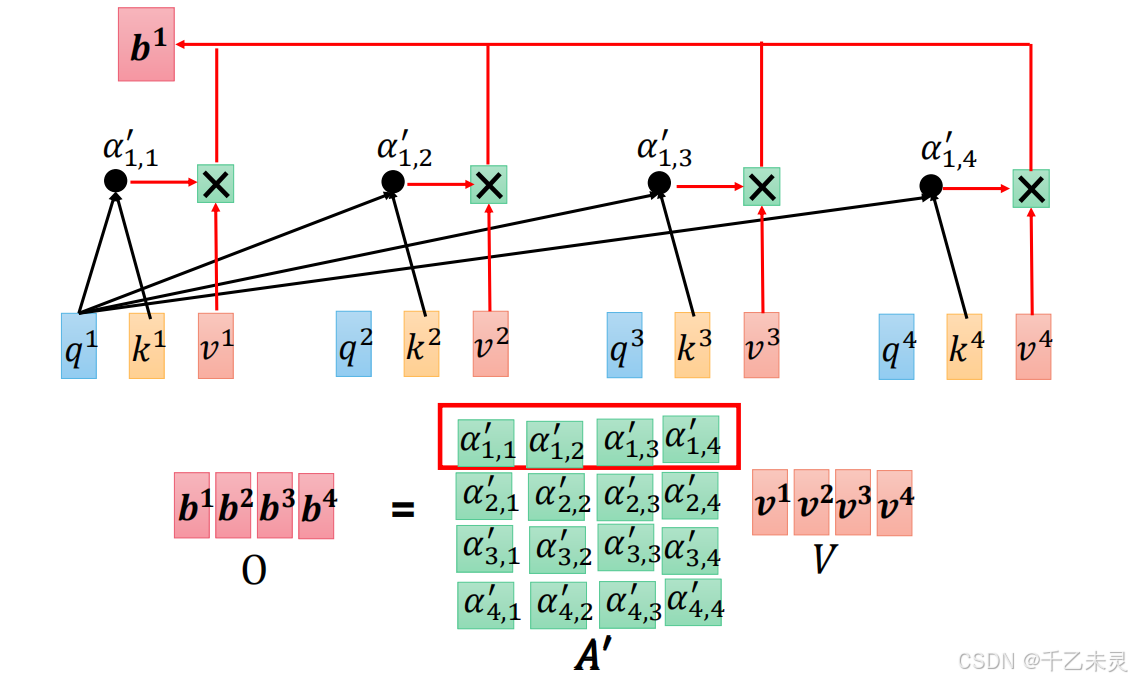
将归一化后的数据与V内容值相乘,得到最终的特征值。
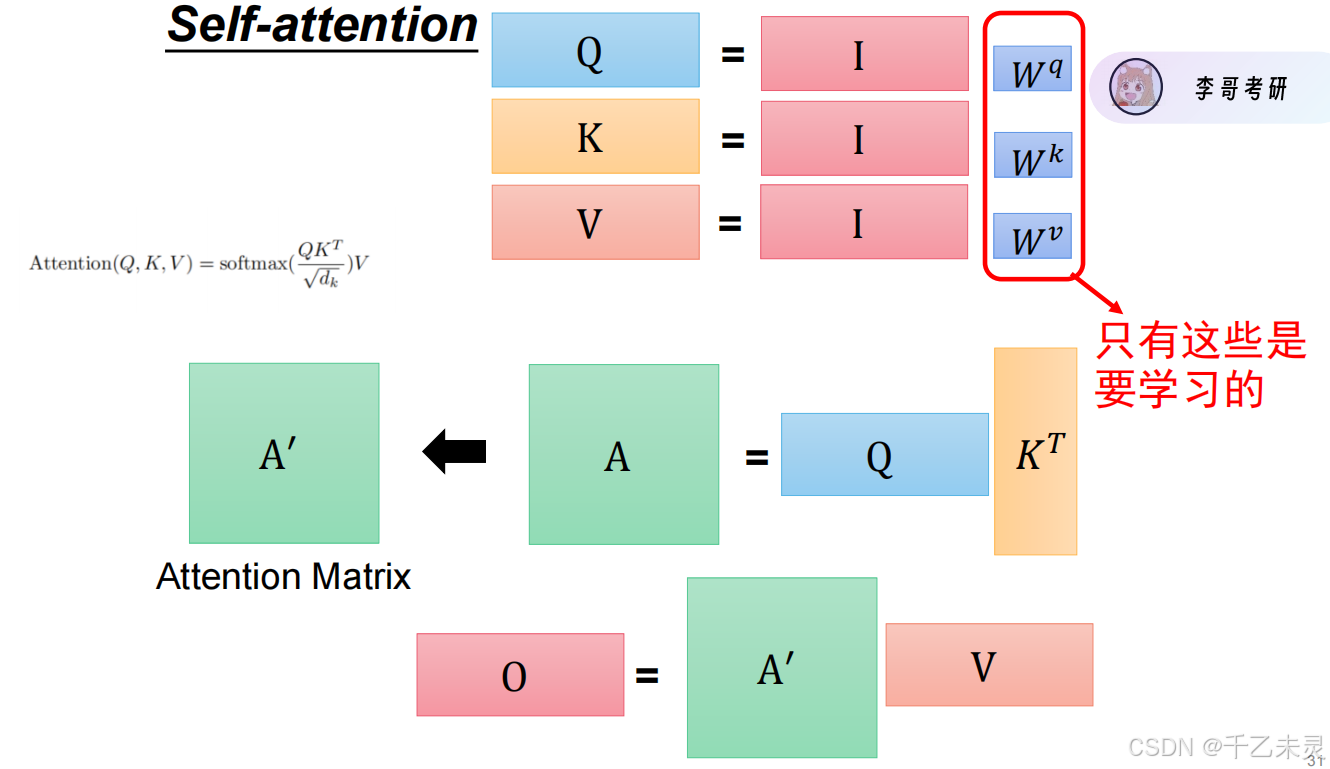
我们再回头过一遍维度.
w
q
w^{q}
wq
w
k
w^{k}
wk
w
v
w^{v}
wv都是768768的全连接。
输入Input为128768,与
w
q
w^{q}
wq
w
k
w^{k}
wk
w
v
w^{v}
wv相乘后得到的Q,K,V都是128768
Q与K转置的乘积,结果为128128。
最后A与V的乘积,最终输出还是128*768

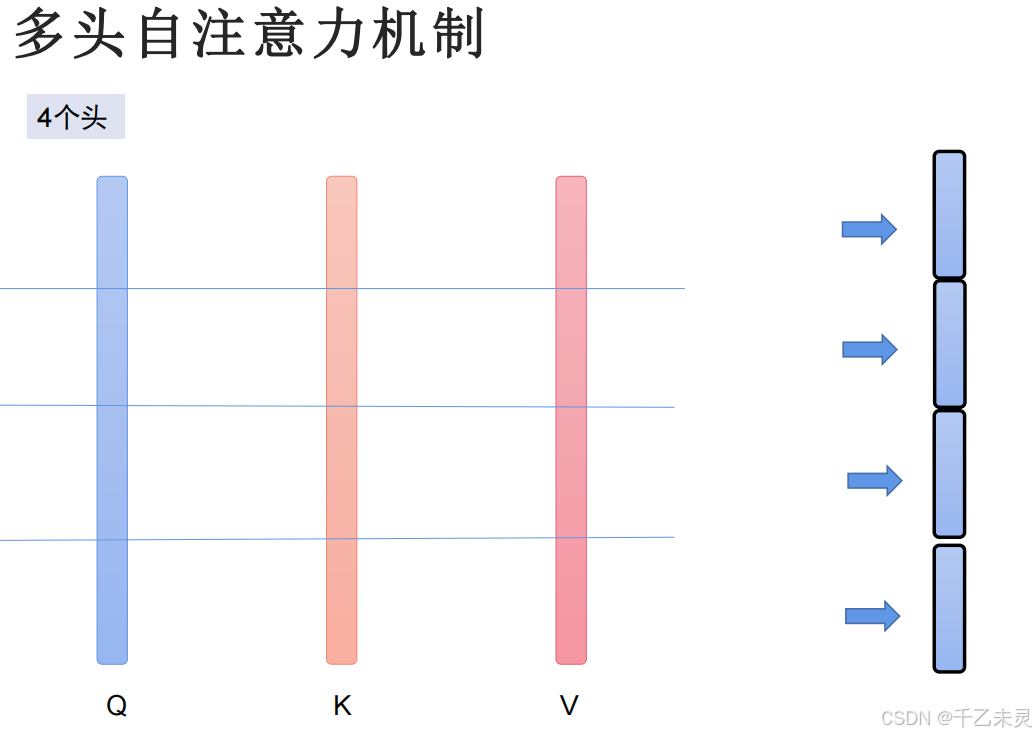
多头注意力机制
多头注意力机制(Multi-Head Attention)是Transformer模型的核心组件之一,通过并行学习多种注意力模式,增强模型对上下文的理解能力。
它的目标是,让模型同时关注输入序列的不同子空间信息(如语法、语义、位置关系等),避免单一注意力模式的局限性。就好比,多个人从不同角度分析同一段文本(例如,一人关注动词-宾语关系,另一人关注时间状语),最后综合所有观点得出更全面的结论。
多头注意力机制通过将输入映射到多个子空间,生成多组Q,K,V,每个子空间(头)独立计算注意力权重并聚合信息。最后合并所有头的输出,并通过线性变换整合结果。
注意力机制层数
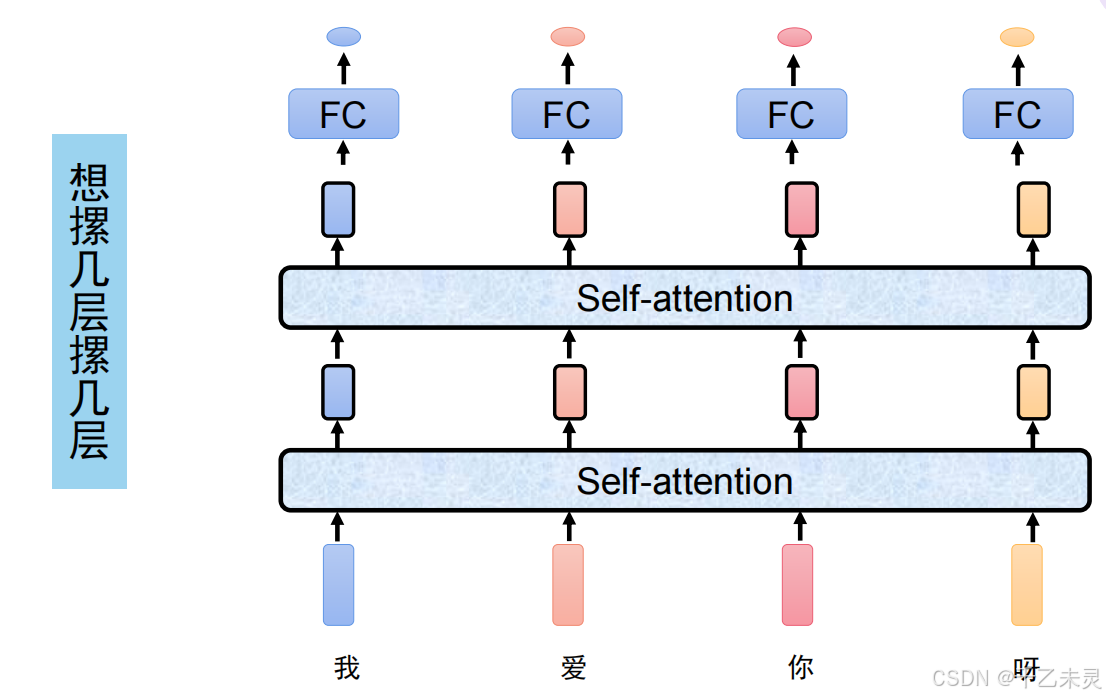
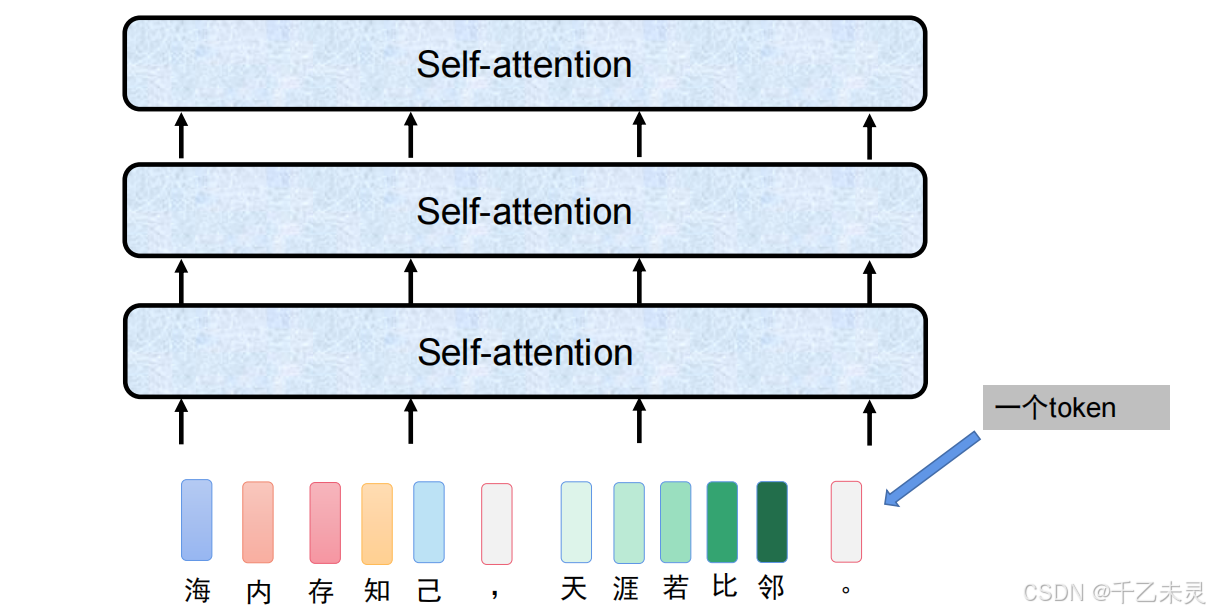
介绍了自注意力机制的工作流程后,我们可以知道,数据通过了自注意力机制之后,数据的维度并不会变换。那么,我们就可以像使用全连接的时候一样,真实使用的时候进行多层堆叠。
位置信息
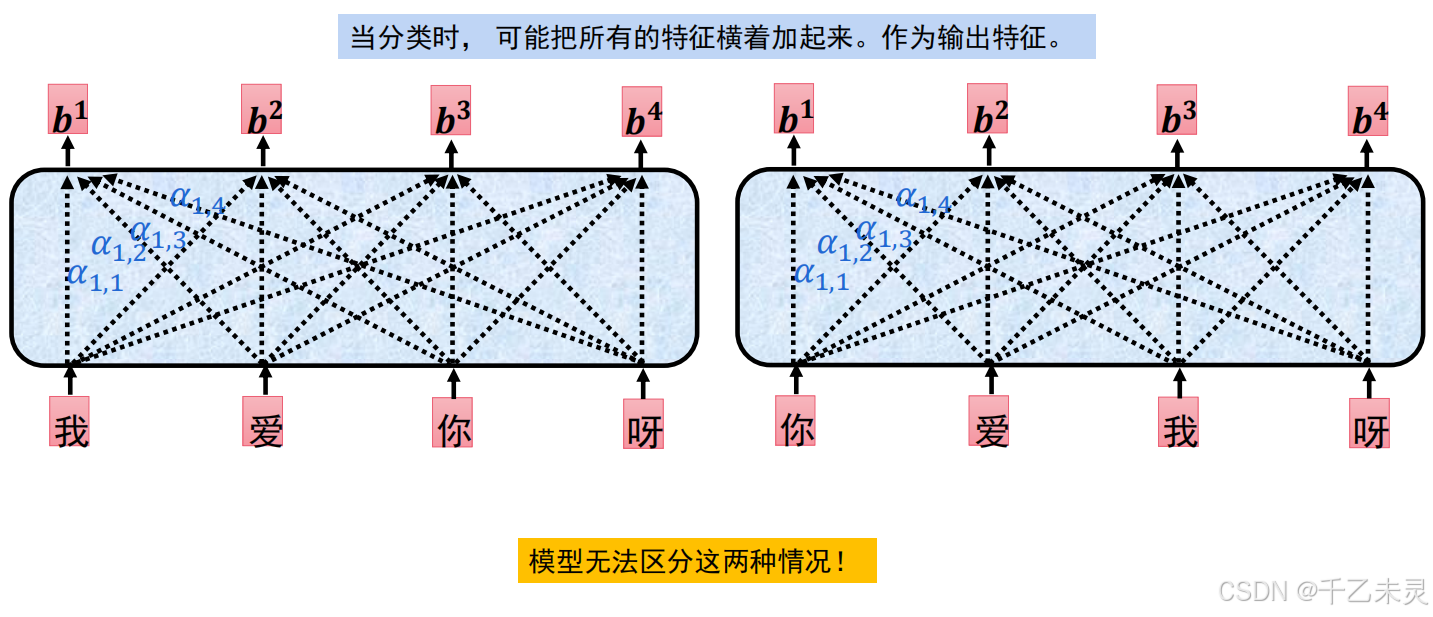
像RNN和LSTM是 串连模式,数据都是从前到后,一个接着一个输入的。但self-attention是并连输入的,所有数据都是同时输入进去,没有明确的位置信息根本无法区分前后。举个例子,“我爱你”和“你爱我”二者意思不同,可他们二者的注意力值却一样,故单独使用自注意力机制无法动态适配多种情况。为了解决这个问题,我们对每个元素添加了位置信息,将位置信息与原始数据进行直接相加,再传入到Self-attention中。
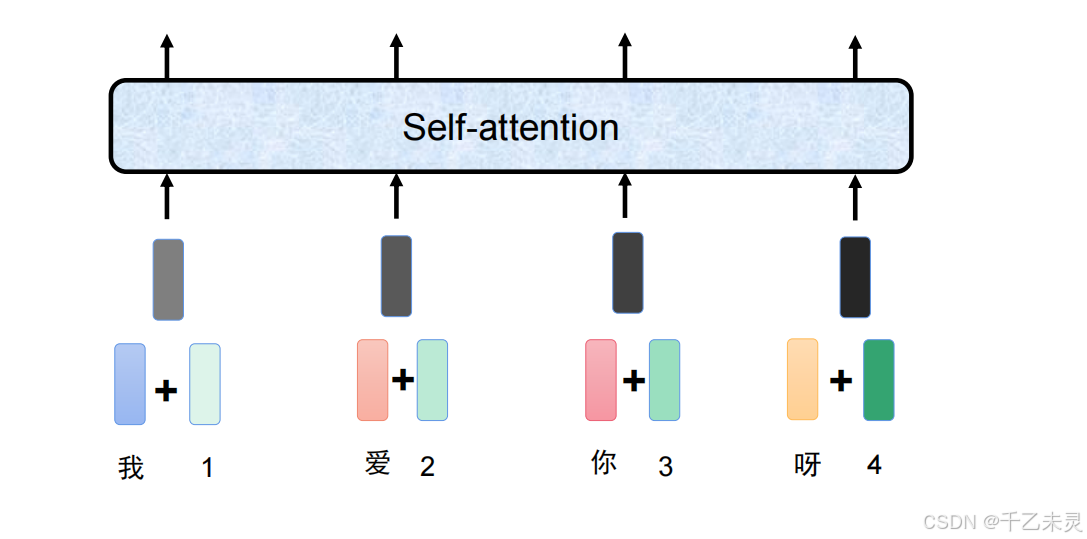
举个例子,transformer架构的输入数据是由词embedding和位置embedding二者进行相加组成生成输入。其中,词embedding是用one-hot编码用全连接生成的768维度的向量,位置embedding也是由位置长度用全连接生成的768维度的向量。
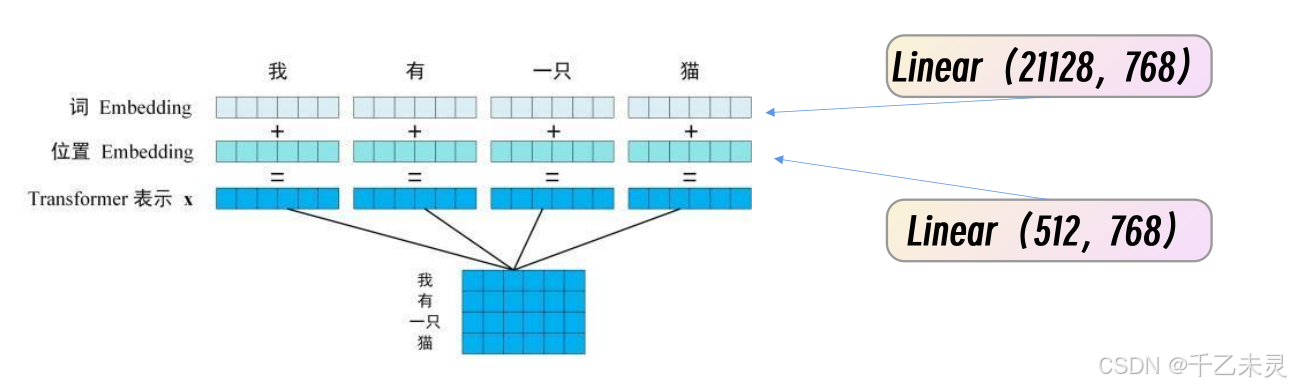
在实际应用中,我们把这个1*768的向量称作一个token。
Transformer
现在,我们学习完自注意力机制的相关知识后,再来回过头看Transformer的架构流程,我们可以发现那些看起来复杂高深的架构层,好像也没有想的那么难以理解。
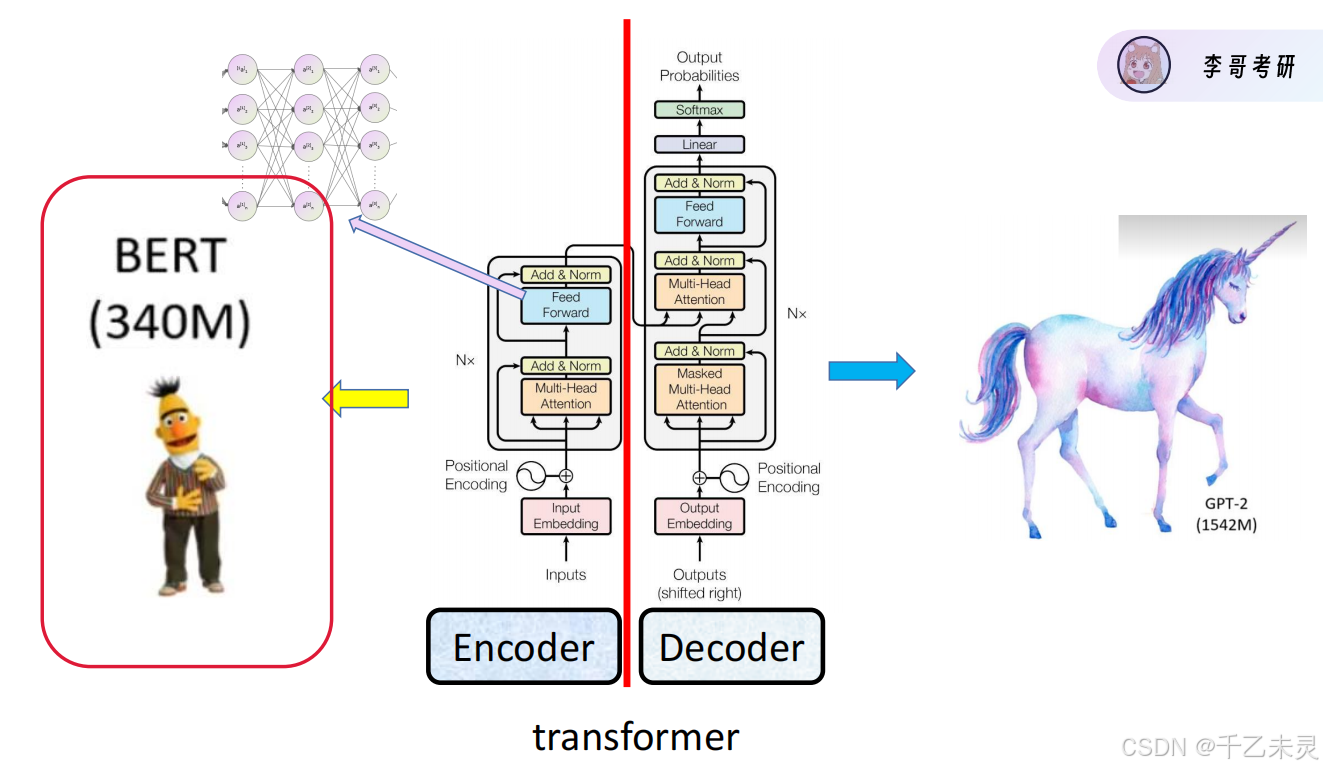
整个Transformer架构,我们可以分为编码器和解码器构成。下面我们来一点一点剖析一下他们的功能和构成。
编码器
功能:将输入序列(如源语言句子)映射为上下文感知的表示。
结构:
输入 + N层编码器
输入:就是我们前面说过的用输入嵌入+位置编码
编码器层:
- 多头自注意力(Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Network)
- 残差连接 + 层归一化(Add & LayerNorm)
其中,前馈神经网络就是两层全连接网络,中间用ReLU激活,作用就是对注意力输出进行非线性变换,增强模型表达能力。
残差连接与层归一化,残差连接就是我们之前文章提过的,将输入直接加入子层输出,缓解梯度消失。层归一化就是加速训练收敛,提升模型稳定性。
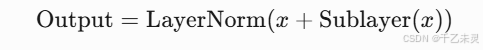
解码器
功能:基于编码器输出和已生成的部分结果,逐步生成目标序列(如翻译后的句子)。
结构:
输出嵌入 + 位置编码:与编码器类似,但处理目标序列。
N个解码器层:每层包含:
掩码多头自注意力(Masked Self-Attention,防止未来信息泄露)
编码器-解码器注意力(Cross-Attention,融合编码器信息)
前馈神经网络 + 残差连接 + 层归一化
Transformer的贡献是巨大的,它的编码器形成了分类任务中的Bert模型,它的解码器形成了生成任务中的GPT模型。
Bert
我们之前讲过的迁移学习,它就是通过在大的训练集中进行预训练,训练出一个好的特征提取器,在下游任务中对特征提取器进行微调之后为自己所用。Bert的作用,就是一个特征提取器。它先在大规模的无监督文本上进行预训练,之后我们在下游任务中,把它迁移过来进行特征提取。
无监督预训练
Bert的无监督预训练,使用的是自监督预训练的方式,通过对一些文字进行遮掩,让模型进行判断。
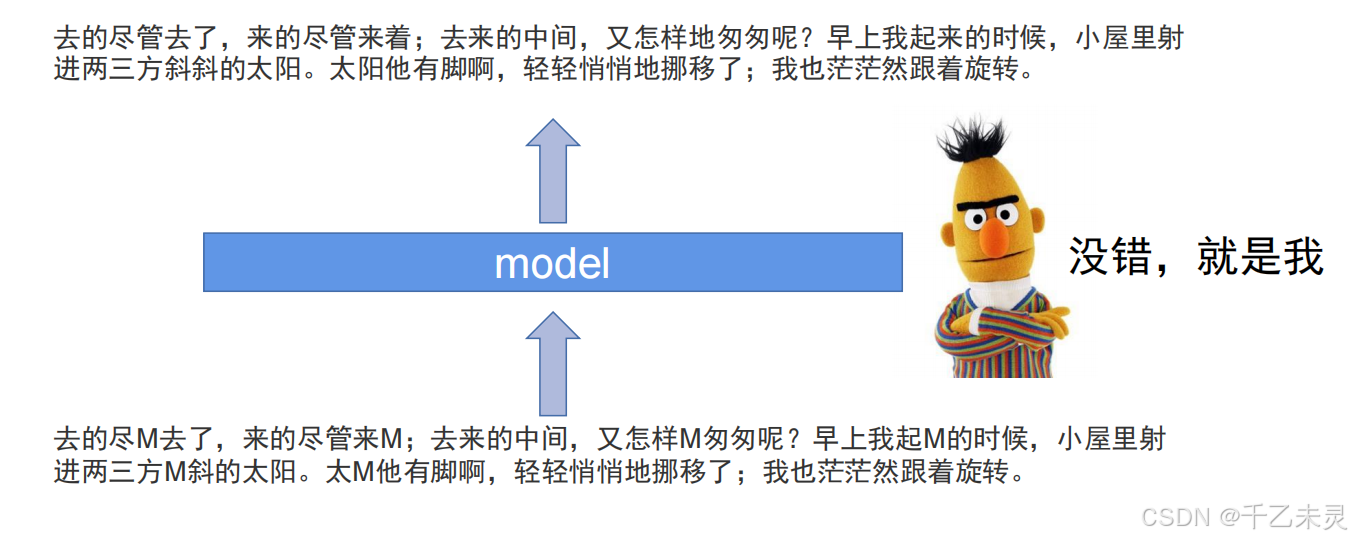
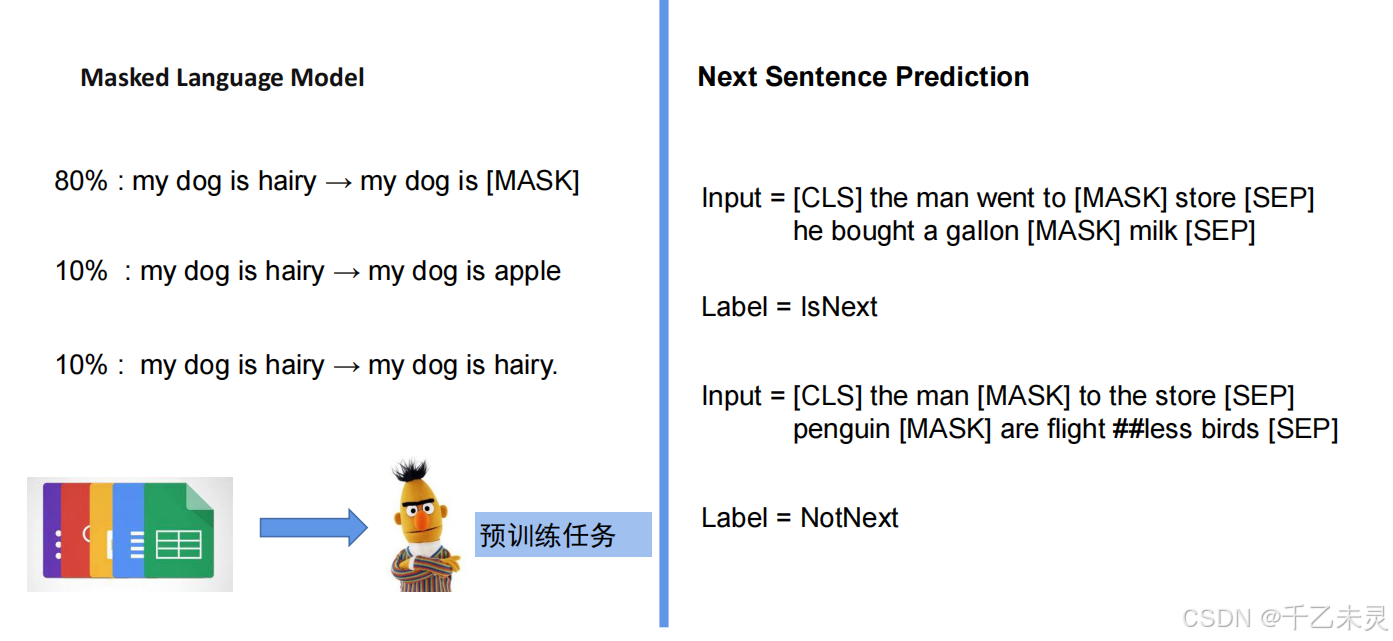
Bert在预训练中,有两个主要任务,一个是MLM就是遮掩部分文字进行训练。进行MLM训练时,大约会将原数据的15%进行遮掩,在这15%替换数据中,80%是被遮掩住的,10%随机找其他词进行替换,还有10%是完全不变。通过这种多样变换,提高模型的准确率。
第二种是下一句预测, 判断两个句子是否在原文中连续出现,帮助模型理解句子间的逻辑关系。给出两个句子(有词被mask),来判断这两句是为上下句。
Bert结构
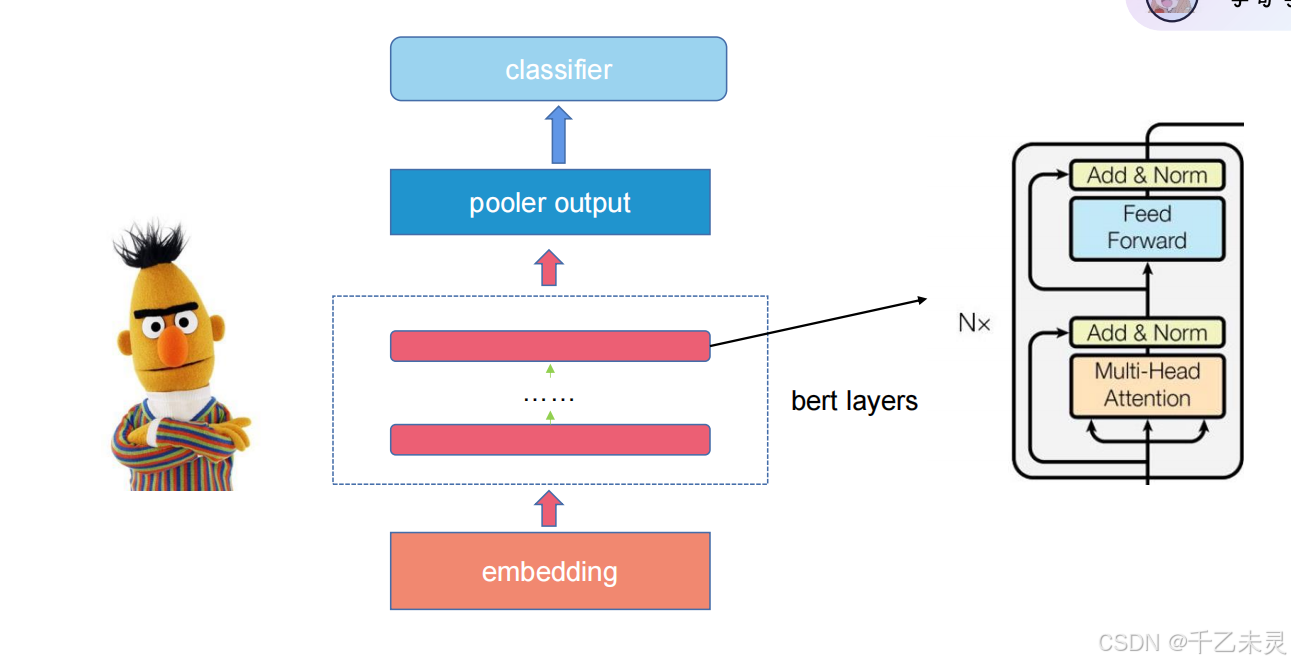
Bert主要分为3个部分,嵌入层,bert层(就是Transformer的编码器架构),池化层。
Bert输入embedding
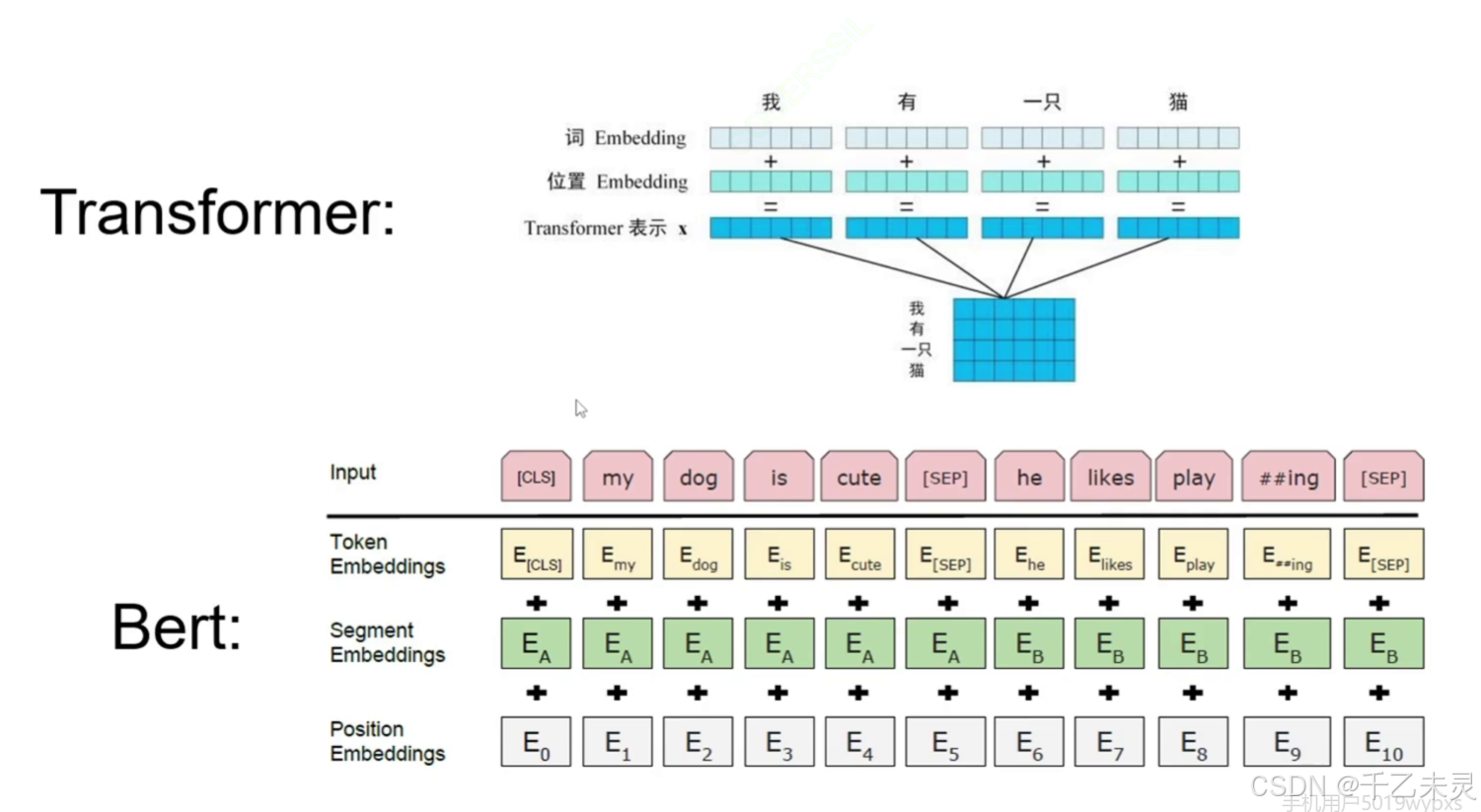
借着下图,我们看一下Bert的输入与Transformer的区别在哪里?很明显,Bert多了一个句子嵌入,那整个Segment Embedding是做什么的?这是一个句子编码,它表明的是,你当前的词在哪一个句子。
除此之外,我们看下图还可以发现,Bert里面多了一些奇怪的token,比如那个[CLS],[SEP]。[SEP]不难理解,看单词简写也大概能猜到是空格的意思,但这里并不是单指空格而是代表中断的意思,比如使用逗号或句号的中断。
那这个[CLS],这是classification的简写,它的作用是聚合整个输入序列的语义信息,你可以类比链表里的头结点,通过这个token去关测与其他数据的注意力值,我们做分类时有时直接将[CLS]去做分类即可。
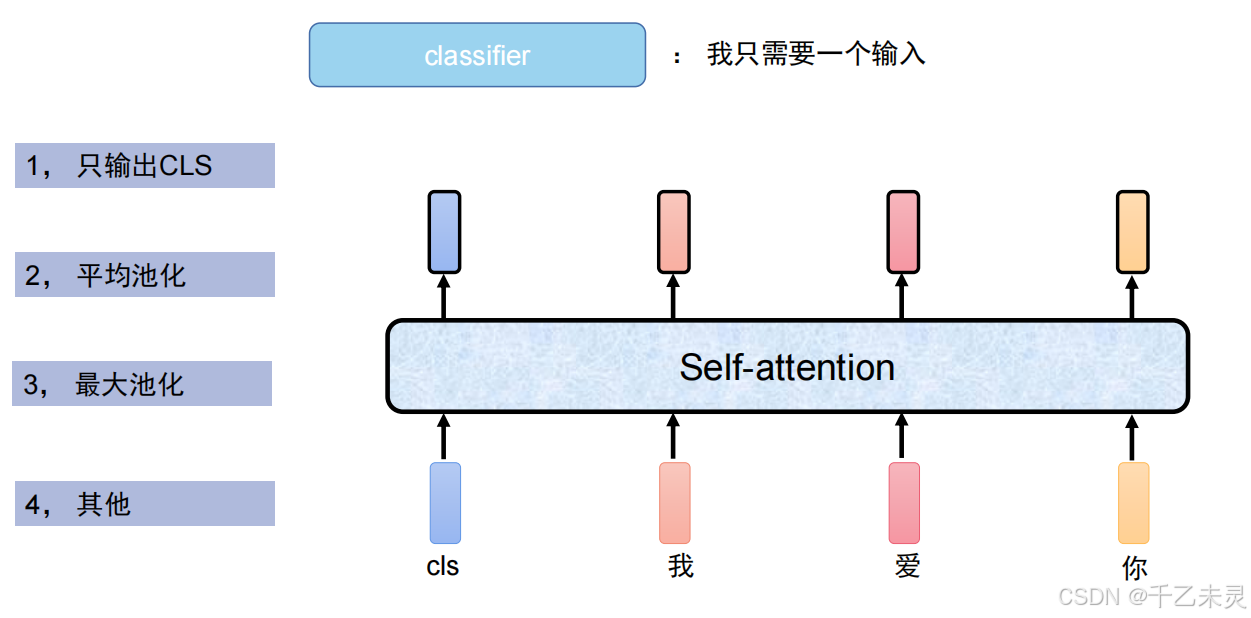
Bert输出pooler
像我们之前计算参数中,输出为128*768,但我们的分类头只需要一个768维的向量就可以了,所以,我们需要使用pooler层进行汇聚提炼。pooler的输出方式有很多种:
- 取 [CLS] 标记的最后一层输出向量,通过一个全连接层(Linear Layer)进行非线性变换。
- 跳过全连接层和 tanh 激活,直接使用 [CLS] 的原始输出向量。
- 平均池化(Mean Pooling):对序列中所有 Token 的输出向量取平均值。
- 最大池化(Max Pooling):对序列中所有 Token 的输出向量取最大值(按维度)。
- 首尾拼接([CLS] + [SEP]):将 [CLS] 和 [SEP] 的向量拼接后输入全连接层。
- 动态权重池化(Attention Pooling):通过注意力机制自动学习各 Token 的权重,加权求和得到全局向量。
总结
本章内容较多,我们来总结回顾一下。
- 我们了解了字的表示方法。
- 为了可以联系上下文,引入了RNN和LSTM。
- 为了获取更高的效率,我们开始了解自注意力机制(Self-Attention)。
- 明白自注意力机制的原理后,我们开始学习Transformer架构。
- 通过Transformer架构的编码器,我们弄懂了Bert的基本原理。

















 6007
6007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









