






 本文介绍了Python数据处理库Pandas如何读取和保存CSV、JSON和Excel文件。Pandas提供了简单易用的接口,如read_csv、read_excel和read_json用于读取,以及to_csv、to_excel和to_json用于保存数据。文章详细阐述了各种方法的参数用法,如filepath_or_buffer、sep、usecols等,并提到了数据清洗和分析在数据挖掘、数据分析中的应用。
本文介绍了Python数据处理库Pandas如何读取和保存CSV、JSON和Excel文件。Pandas提供了简单易用的接口,如read_csv、read_excel和read_json用于读取,以及to_csv、to_excel和to_json用于保存数据。文章详细阐述了各种方法的参数用法,如filepath_or_buffer、sep、usecols等,并提到了数据清洗和分析在数据挖掘、数据分析中的应用。
pandas来自于panel data,后面就用熊猫代替pandas了!
numpy和熊猫相比较,还是有很多不足的地方。熊猫强大的原因如下:
-
一个强大的分析和操作大型结构化数据集所需的工具集
-
基础是NumPy,提供了高性能矩阵的运算
-
提供了大量能够快速便捷地处理数据的函数和方法
-
应用于数据挖掘,数据分析
-
提供数据清洗功能
一、读取文件
熊猫读取每一种不同的文件有不同的方法比如:
读csv文件:pandas.read_csv( )
读excel文件:pandas.read_excel( )
读json 文件:pandas.read_json ( )
其实这么看起来也很好记忆的!
1.csv
pandas.read_csv( filepath_or_buffer, sep =',' , usecols=[] )
filepath_or_buffer:文件路径
sep =',' :分隔符,一般用逗号
usecols=[]:选择读取的列,必须用列表形式
file.to_csv( filepath_or_buffer, sep =',' , columns=[] )
columns=['open', 'high', 'close'], # 指定保存数据的列数
index=False # 可以让索引列不被保存的,要不然会多出第一列
2.Json
pandas.read_json ( )
file.to_json ( )
保存json有点难度,其中参数
force_ascii=False # 默认在保存json数据的时候, 是 ascii 编码, force_ascii=False不使用ascii编码
orient='table' # 指定保存数据的类型
可以保存的数据类型有,split、table、index

原json数据
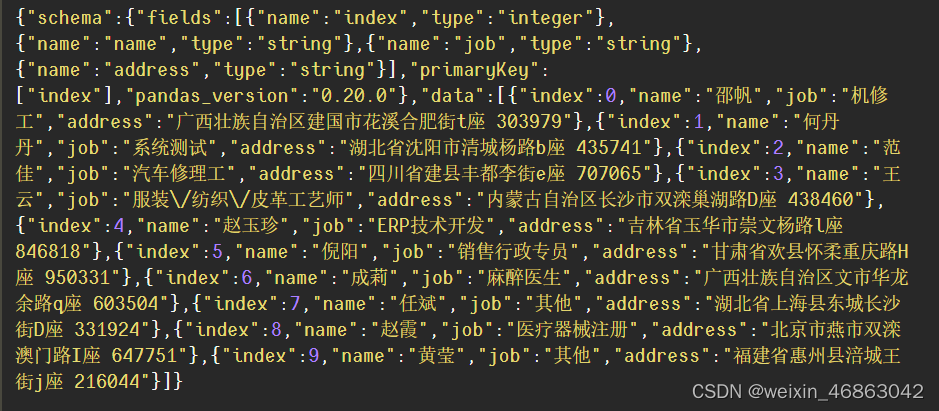
orient='table'

orient='split'

orient='index'
3.excel
df_excel = pd.read_excel('./data/xxx.xlsx', sheet_name='表1', skiprows=[0, 1], nrows=10)
打开excel文件一定要考虑到打开到具体的XX表中,skiprows可以跳过指定的行,nrows可以查看有多少行。
file.to_excel()
保存excel文件的时候就可以不用指明表名字了!(excel玩的好,这个用处也不是很大了!)

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









