






UsersandtheirdataModernaccessandauditpatternsonAWS
关键字: [reInforce, Amazon Lake Formation, Trusted Identity Propagation, Data Access Control, Amazon Lake Formation, Amazon Identity Center, Amazon Web Services S3 Access]
本文字数: 2500, 阅读完需: 12 分钟
导读
在这场演讲中,演讲者探讨了如何为访问亚马逊云科技上的数据的用户启用细粒度访问控制和审计。具体而言,演讲者阐释了亚马逊云科技服务如Lake Formation和S3 Access Grants如何允许直接基于用户身份和组定义权限,而亚马逊云科技 Identity Center则能够在亚马逊云科技服务之间传播用户身份。演讲重点关注亚马逊云科技如何实现细粒度数据访问控制、与用户身份一致的审计,以及跨多个分析服务(如EMR、Athena和Redshift)的统一权限管理。
演讲精华
以下是小编为您整理的本次演讲的精华,共2200字,阅读时间大约是11分钟。
在当代瞬息万变的商业环境中,数据被视为最终的差异化因素,亚马逊云科技的客户一直在努力在云端构建健全的数据基础。这一战略举措源于这样一种认识:企业的真正价值不仅仅在于数据本身,更在于通过高级分析、机器学习以及新兴的生成式人工智能领域来发掘数据的潜力。正如演讲者娓娓道来,“企业的大部分价值实际上在于其数据以及其可以利用这些数据做什么,从分析到机器学习,最近还有生成式人工智能的进展。”
然而,企业面临的挑战是确保组织内适当的人员能够跨越不同的应用程序和服务访问适当的数据。这一挑战并非新鲜事物,但随着能够从数据中释放前所未有价值的尖端技术的出现,其重要性被进一步放大。
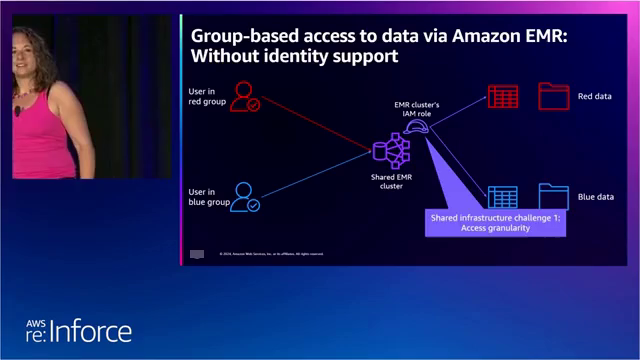
传统上,企业一直依赖亚马逊云科技身份和访问管理(IAM)服务来实施基于角色的访问控制机制。然而,正如演讲者通过各种场景娓娓道来的那样,这种方法在促进细粒度的基于用户的访问控制方面存在固有的局限性。其中一个场景涉及一家拥有三个不同项目(分别用红色、黄色和蓝色数据表示)和五个用户(每个用户用不同的颜色表示)的企业。
演讲者解释道:“这里有五个用户,颜色各不相同。所以存在很大的多样性。而且每个用户的工作都不一样。每个用户都在不同的项目上工作,他们属于不同的群组,有不同的属性,对吗?他们所在的地理位置也不尽相同。有各种各样的原因导致您可能希望或不希望这些用户访问特定的数据。
为了进一步阐明基于用户的访问控制的复杂性,演讲者引入了常见于用户目录中的”组”这一概念。他表示:“用户是组的成员。演讲者为一家大公司工作。如果演讲者查看自己所属的组,数量非常多。实际上,如果公司足够大,每个人都是独特组合组的成员。没有人与其他人拥有完全相同的组合和组成员身份。”
然后,演讲者使用基于颜色的类比来演示用户、组和数据访问之间的错综复杂的关系。他解释道:“这里有一个绿色用户。绿色用户同时是蓝色组和黄色组的成员,因为蓝色加黄色等于绿色,对吗?我们将稍微使用这个比喻。那么这个绿色用户,对于他们应该能够访问什么有什么合理期望呢?这个绿色用户可能可以访问蓝色项目的表格,对吧?因为他们在蓝色组。他们也可以访问黄色项目的某些内容,因为他们在黄色组。但是,他们做不到的是,他们无法访问任何红色数据,对吧?因为绿色用户不在红色组中。”
这种错综复杂的用户身份、组成员关系和数据访问要求,凸显了传统基于角色的IAM方法的局限性,往往导致粗粒度的访问控制或需要多个集群或实例来满足不同级别的访问需求。
正是在这个时候,演讲者引入了一个颠覆性的概念:“可信身份传播”,这是亚马逊云科技生态系统中一个相对较新的功能,赋予服务理解和响应经过身份验证的用户身份的能力。这一创新解决方案的核心是亚马逊云科技IAM身份中心(前身为亚马逊云科技单点登录),一项旨在与企业目录(如Okta或Microsoft Entra ID(前身为Azure AD))无缝集成的服务,从而将用户身份引入亚马逊云科技环境。
为了阐释可信身份传播的强大功能和复杂性,演讲者深入探讨了EMR Studio的内部工作原理,这是一个由亚马逊云科技提供的托管Jupyter笔记本环境。他展示了一个笔记本的屏幕截图,突出了诸如浏览器地址栏中的URL(表明使用了可信身份传播)以及该笔记本连接到运行Spark的EMR on EC2集群等关键细节。
演讲者随后深入探讨了各种亚马逊云科技服务在可信身份传播过程中的复杂交互。他解释道:“为了实现刚才展示的功能,实际上涉及了多个亚马逊云科技服务的协作。有EMR Studio、执行实际工作的集群,还有Glue Data Catalog和Lake Formation协同工作来帮助定义元数据并获取访问权限。S3是存储数据的地方。IAM当然也在其中,稍后我们会谈到这一点。”
深入探讨技术细节,演讲者逐步讲解了用户身份和访问控制机制的流程。他解释说,当用户使用身份提供商(如Entra ID)登录EMR Studio时,他们的身份会通过参与数据访问过程的各种服务进行传播。
EMR集群由运行Spark的EC2实例组成,在执行实际的数据处理任务中扮演着关键角色。演讲者强调:“EMR集群是所有数据访问发生的地方,对吗?这些运行Spark的EC2实例将从S3读取大量数据,并需要遵守正确的权限。”
Glue Data Catalog是分析数据的元数据存储,与Lake Formation协同工作来定义和管理元数据访问。演讲者展示了Glue Data Catalog控制台,显示了他数据库中的表列表。
Lake Formation是一项旨在管理对数据湖的访问的服务,作为策略决策点,根据用户和组的授权强制执行访问控制。演讲者展示了Lake Formation授权表的简化版本,表示:“这里有两个授权。红色目录组获得对红色表的SELECT访问权限,因为这都是关于结构化数据和数据库等概念的。蓝色目录组获得对蓝色表的访问权限。
能够将授权放置于 Lake Formation 等服务中,为其带来了两个明显的优势。首先,可以注意到,所拥有的授权数量将与所拥有的数据单元数量(如表等)呈线性关系。这实际上具有非常好的扩展性,而非组合式的。大约拥有 n 个某种对象。
为进一步阐释可信身份传播的强大功能,演讲者演示了一个涉及红色用户查询”美国城市人口统计”表和蓝色用户查询”车辆”表的场景。他展示了 Lake Formation 中的授权如何精准控制访问权限,红色用户由于缺乏适当的授权而被拒绝访问”车辆”表,而蓝色用户则能成功查询”车辆”表。
然后,演讲者引入了”紫色用户”的概念,即同时属于红色和蓝色组的用户,因此可以访问”美国城市人口统计”和”车辆”两个表。他说:“另一方面,紫色用户查询任一这些表都可以。事实上,如果他想将它们连接,不确定连接这些表意味着什么。猜测可能在对城市人口对车辆价格的影响进行机器学习。实际上不确定这是否是一种情况。但可以清楚地看到,这个紫色用户能够在同一会话中查询这个表和那个表,因为有授权允许每个表的访问。”
在整个演示过程中,演讲者强调了无论使用何种应用程序或服务与数据交互,一致且可审计的访问控制的重要性。他说:“我们希望这些完全相同的授权得到遵守。我们希望审计工作与之前完全一样。我们不希望只是因为有人想使用 Athena,就不得不编写新的授权或重复授权。”
为解决这一需求,演讲者介绍了 Athena(亚马逊云科技的无服务器查询服务),并演示了它如何与可信身份传播框架无缝集成。他在 EMR Studio 中展示了 Athena SQL 查询编辑器,突出显示了配置为使用经过身份验证的用户身份的”身份感知”工作组。
演讲者阐释了Athena中访问控制的流程。它首先会访问Glue Data Catalog,了解”vehicles”表的内容和元数据,并检查用户是否有权限访问该元数据。随后,它会通过Lake Formation实际执行查询,因为在幕后,Athena的工作节点需要获得许多S3”get objects”的权限,才能获取相关数据。
关于对输出位置进行细粒度控制的需求,演讲者强调了Athena将不同用户的输出写入S3中不同文件夹的能力。他解释道:“Athena身份集成的一个很酷的功能是,它实际上有一个选项,可以让不同用户的输出写入不同的文件夹。这很重要,因为在这种设置下,你和我可以在Athena中查询不同的数据。但如果我们所有人的输出、结果都写入同一个位置,我们都可以看到彼此的结果,那不是有点违背了目的吗?”
接着,演讲者将重点转移到了亚马逊云科技的生成式AI产品,如Amazon Q Business和Q Developer,以及它们与Identity Center的集成。他强调了这种集成的重要性,说:“Q Business是一个非常有趣的用例,因为你可以将它放在数据前面,让你的用户快速从数据中获取价值。”
为了说明这种集成的实际应用,演讲者分享了他在亚马逊工作时的一个引人入胜的用例。他创建了一个概念验证,允许用户通过自然语言查询与公司内部文档进行交互,利用了Q Business的功能。
演讲者解释说:“我把那些数据放在一个S3桶中,在Q Business控制台上点击了几下,就可以了,我没有花太多精力去定制UI,当然你可以这样做,但基本上我现在有了一个东西,人们可以通过它与我们的内部文档进行交流,提出问题。
值得注意的是,该系统为每位经过身份验证的用户维护了独立的聊天历史记录,确保访问权限是针对个人身份量身定制的,并保护了数据的完整性。演讲者强调了这一特点,他表示:“您会注意到在这里的左侧栏中,我有一个聊天历史记录,每个用户都是如此。这不是亚马逊云科技控制台,只是指出这一点,每个用户将看到不同的聊天历史记录。换句话说,当您登录时,该系统能识别您的身份,您将看到您自己的聊天历史记录,而不是我的。”
演讲者还提到,可信身份传播不仅限于亚马逊云科技服务。他说:“正如我所说,您甚至可以在所有这些数据上构建S3访问授权和LAKE FORMATION。您可以构建第三方应用程序,比如想象一下,您有一个报告工具,用户登录后就可以访问数据。您可以让它与身份完全集成,并将这些身份引入亚马逊云科技,这样您应用程序中的正确用户就可以访问正确的数据,因为这里有一些技术细节。只需学习API,学习要添加到应用程序中的代码行。”
总之,演讲者全面的演讲强调了亚马逊云科技在帮助企业构建健全的数据基础方面发挥着关键作用,其中包括细粒度的基于用户的访问控制机制。通过利用可信身份传播的强大功能,结合LAKE FORMATION和S3访问授权等服务,组织可以充分发挥数据的潜力,同时保持严格的治理和可审计性标准。
演讲者通过可信身份传播的复杂细节,结合真实世界的示例、用例和技术细节,见证了亚马逊云科技致力于赋予企业权力,以应对现代数据管理的复杂性。随着世界继续拥抱生成式人工智能和其他尖端技术的变革潜力,精确控制对数据的访问将变得越来越重要,亚马逊云科技将提供必要的工具和服务来满足这一不断发展的挑战。
下面是一些演讲现场的精彩瞬间:
每一家现代企业都是数据驱动型企业,数据是它们的差异化优势。

随着云计算和人工智能技术的不断发展,企业数据的价值正变得越来越重要。

在此时刻,演讲者表示将深入探讨亚马逊云科技的工作原理,以帮助与会者更好地评估亚马逊云科技服务的安全性、配置和最佳实践。
在演讲中,演讲者提及Amazon CloudTrail服务,它可以记录对S3存储桶的访问事件,但无法直接显示是哪个用户访问了数据,需要通过交叉参考事件来推断。
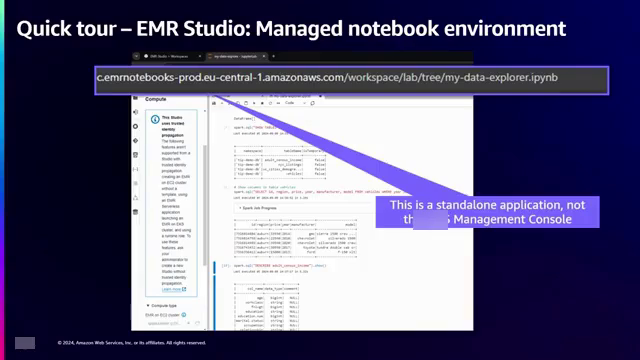
这是一个笔记本电脑的截图,展示了一个使用Entra ID进行身份验证的专用应用程序,该应用程序利用了可信身份传播,并在EMR on EC2集群上运行Spark。

在设置亚马逊EMR工作室的身份验证时,需要提供一个IAM角色,该角色的作用是将工作推送到下游。
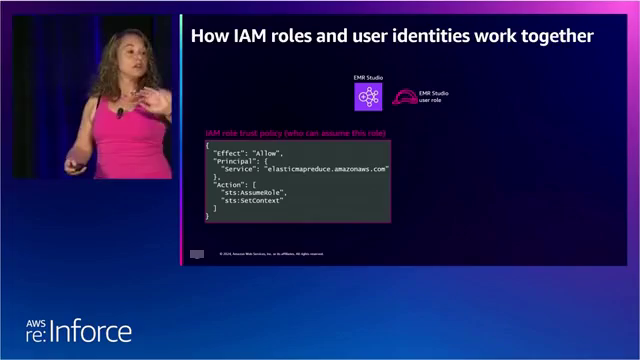
亚马逊EMR工作室角色的信任策略允许EMR服务代入该角色,并在会话中包含最终用户的身份上下文。

总结
- 亚马逊云科技 Identity Center 允许将来自 Okta 或 Azure AD 等公司目录的用户身份集成到亚马逊云科技服务中,使用户能够直接以自身身份访问数据,而无需通过 IAM 角色。
- 诸如亚马逊云科技 Lake Formation 和 S3 Access Grants 等服务充当策略决策点,允许您基于目录中的用户和组定义细粒度的数据访问授权。这些授权在分析服务(如 EMR、Athena、Redshift 和 QuickSight)中得到一致执行。
- 演讲者详细演示了可信身份传播在幕后的工作原理,涉及 IAM 角色、Lake Formation 授权和 S3 访问授权,以控制数据访问,同时仍然遵守亚马逊云科技数据边界和 IAM 权限。
- 诸如 Amazon Q Business 和 Q Developer 等生成式 AI 服务也与 Identity Center 集成,使用户能够根据自身身份和权限通过这些 AI 助手访问数据。
总的来说,演讲强调了在亚马逊云科技上建立强大的数据基础的重要性,现在包括实现基于用户的细粒度访问控制的能力,以充分释放数据价值的同时保持健全的治理和安全性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









