






一句话总结:3DEnhancer采用多视图扩散模型来增强多视图图像,从而改进3D模型。我们的贡献包括一个强大的数据增强管道,以及集成多视图行注意和近视图核聚合模块以促进视图一致性的视图一致块。
0. 论文信息
标题:3DEnhancer: Consistent Multi-View Diffusion for 3D Enhancement
作者:Yihang Luo, Shangchen Zhou, Yushi Lan, Xingang Pan, Chen Change Loy
机构:S-Lab, Nanyang Technological University
原文链接:https://arxiv.org/abs/2412.18565
代码链接:https://yihangluo.com/projects/3DEnhancer
1. 导读
尽管在神经绘制方面取得了进步,但是由于高质量3D数据集的缺乏和多视图扩散模型的固有限制,视图合成和3D模型生成被限制在低分辨率和次优的多视图一致性。在这项研究中,我们提出了一种新的3D增强管道,称为3DEnhancer,它采用多视图潜在扩散模型来增强粗略的3D输入,同时保持多视图的一致性。我们的方法包括一个姿势感知编码器和一个基于扩散的降噪器,以改善低质量的多视图图像,以及数据增强和一个具有核聚合的多视图注意力模块,以保持各视图之间一致的高质量3D输出。与现有的基于视频的方法不同,我们的模型支持无缝的多视图增强,提高了不同视角的一致性。广泛的评估表明,3DEnhancer明显优于现有的方法,提高了多视图增强和每个实例的3D优化任务。
2. 效果展示
我们提出的3DEnhancer展示了在增强由各种模型生成的多视图图像方面的卓越能力。如图(a)所示,它可以显著提高纹理细节,纠正纹理错误,并增强各视图的一致性。除了增强功能外,如图(b)所示,3DEnhancer还支持纹理级编辑,包括区域补画,并通过噪声水平控制调整纹理增强强度。

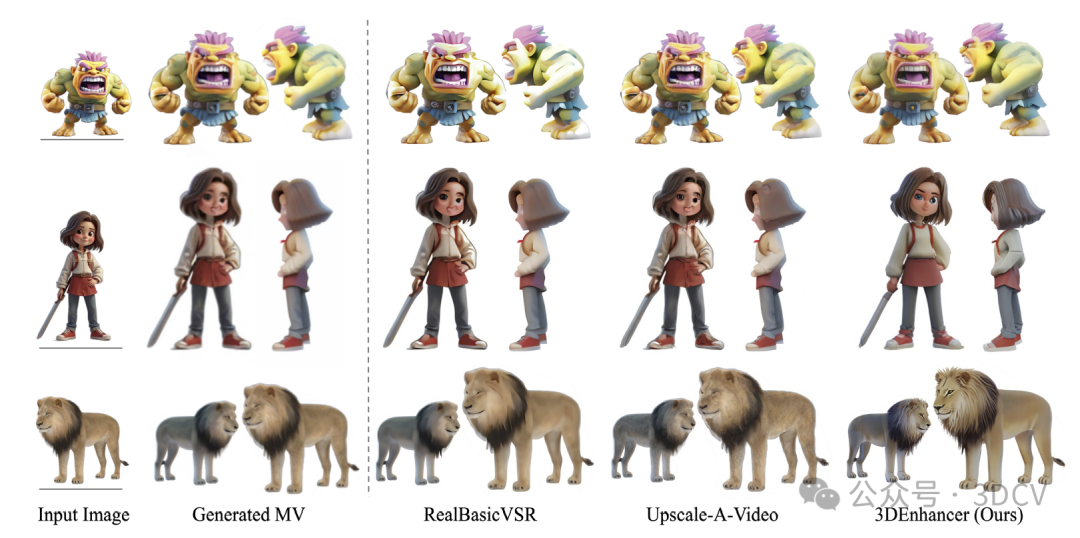
可以看出,只有3DENHANCER可以校正流动和缺失的纹理,并保持视图的一致性。

在野外数据集上使用RealBasicVSR和Upscale-A-Video增强多视图合成的定性比较。视觉检查,3DENHANCER产生清晰一致的纹理和完整的语义,例如中间一排女孩的眼睛。
3. 引言
生成模型和可微渲染的进步为神经渲染这一新的研究领域铺平了道路。除了推动视图合成的边界外,3D模型的生成和编辑也变得切实可行。这些方法是在大规模3D数据集(如Objaverse数据集)上进行训练的,能够实现快速且多样化的3D合成。
尽管取得了这些进展,3D生成仍面临多项挑战。一个关键限制是高质量3D数据集的稀缺性;与数十亿个高分辨率图像和视频数据集不同,当前的3D数据集规模要小得多。另一个限制是对多视图(MV)扩散模型的依赖。大多数最先进的3D生成模型遵循两阶段流程:首先,基于图像或文本生成多视图图像,然后从这些生成的多视图重建3D模型。因此,多视图扩散模型的低质量结果和视图不一致问题限制了最终3D输出的质量。此外,现有的新颖视图合成方法通常需要密集的高分辨率输入视图进行优化,当只有低分辨率稀疏捕获时,3D内容创建变得具有挑战性。
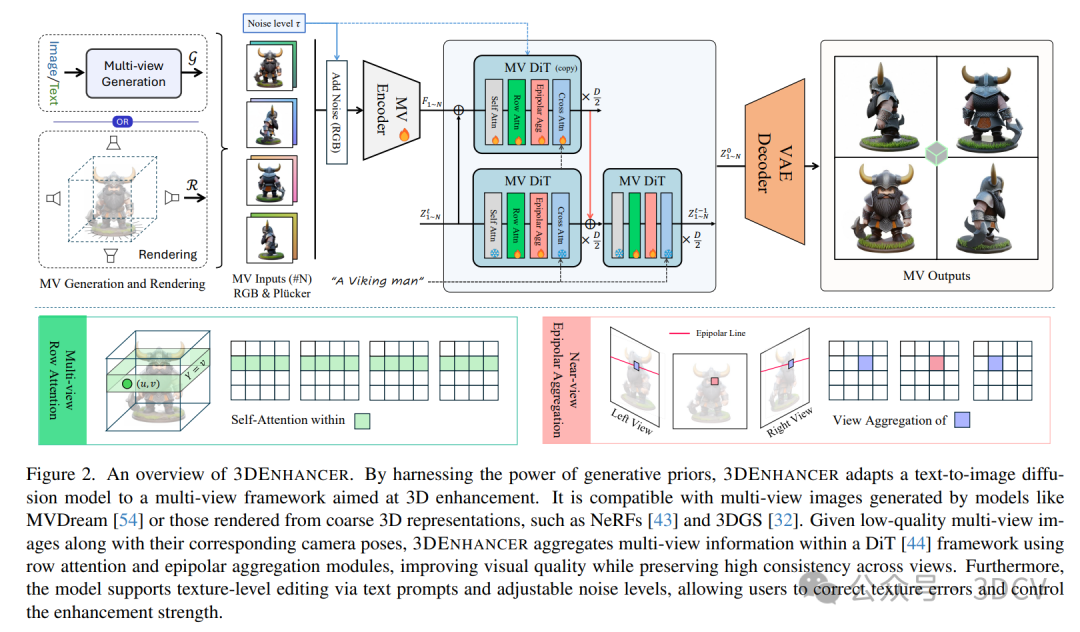
在本研究中,我们通过引入一种通用的3D增强框架3DENHANCER来解决这些挑战,该框架利用文本到图像的扩散模型作为二维生成先验来增强一般的粗糙3D输入。我们提出方法的核心是一个多视图潜在扩散模型(LDM),旨在增强粗糙3D输入,同时确保多视图一致性。具体来说,该框架包括一个姿态感知图像编码器,用于将低质量的多视图渲染编码到潜在空间,以及一个基于多视图的扩散去噪器,用于通过视图一致块精炼潜在特征。增强后的视图随后要么用作多视图重建的输入,要么直接作为优化粗糙3D输入的重建目标。
为了实现实际结果,我们对输入的多视图图像引入了多样化的退化增强,模拟了粗糙3D数据的分布。此外,我们结合了高效的多视图行注意力来确保多视图特征之间的一致性。为了进一步增强在显著视角变化下的连贯3D纹理和结构,我们还引入了近视图极线聚合模块,该模块使用极线约束特征匹配在近视图之间直接传播相应的令牌。这些精心设计的策略有效地促进了实现高质量、一致的多视图增强。
与本研究最相关的工作是使用视频扩散模型进行3D增强的方法。虽然视频超分辨率(VSR)模型也可以调整为用于3D增强,但它们作为通用3D增强器的适用性受到几个挑战的限制。首先,这些方法仅限于通过逐个实例优化来增强3D模型重建,而我们的方法可以通过将多视图增强集成到现有的两阶段3D生成框架(例如,从“MVDream→LGM”到“MVDream→3DENHANCER→LGM”)中来无缝增强3D输出。其次,视频模型在处理长期一致性方面常常遇到困难,并且无法纠正显著视角变化下3D对象中的生成伪影。此外,基于时间注意力的视频扩散模型[3]在处理长视频时受到内存和速度限制的制约。相比之下,我们的多视图增强器模型通过利用多视图原始注意力和近视图极线聚合,隐式和显式地跨各种视图建立纹理对应关系,从而实现了更优的视图一致性和更高的效率。
4. 主要贡献
我们提出了一种新颖的3DENHANCER,用于使用多视图去噪扩散进行通用3D增强。我们的贡献包括一个稳健的数据增强管道,以及混合视图一致块,该块结合了多视图行注意力和近视图极线聚合模块,以促进视图一致性。与现有的增强方法相比,我们的多视图3D增强框架更加通用,并支持纹理细化。我们在多视图增强和逐个实例优化任务上进行了大量实验,以评估模型组件。我们提出的管道显著提高了粗糙3D对象的质量,并且始终优于现有替代方案。
5. 方法
当前3D生成中的一个常见管道包括一个图像到多视图阶段,随后是多视图到3D生成,将这些多视图图像转换为3D对象。然而,由于分辨率和视图一致性的限制,生成的3D输出通常缺乏高质量纹理和详细几何形状。所提出的多视图增强网络3DENHANCER旨在提高3D表示的质量。我们的动机是,如果我们能够获得高质量且视图一致的多视图图像,那么3D生成的质量就可以相应地提高。
如图2所示,我们的框架采用基于扩散变换器(DiT)的LDM作为主干。我们结合了姿态感知编码器和视图一致的DiT块来确保多视图一致性,从而使我们能够利用强大的多视图扩散模型来增强粗糙的多视图图像和3D模型。增强的多视图图像可以提高预训练的前馈3D重建模型(例如LGM)的性能,并通过迭代更新来优化粗糙的3D模型。
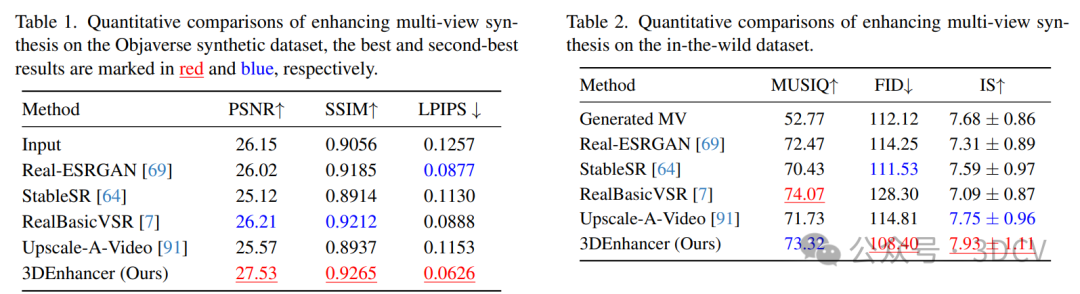
6. 实验结果
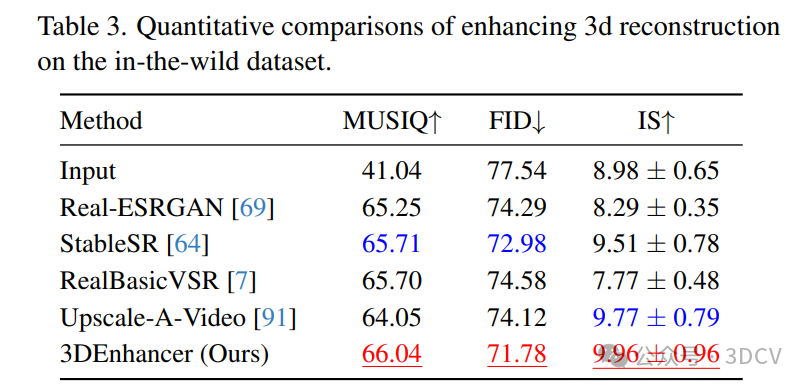
7. 总结 & 未来工作
总之,这项工作提出了一种新颖的3D增强框架,该框架利用视图一致的潜在扩散模型来提高给定粗糙多视图图像的质量。我们的方法引入了一个通用的管道,该管道结合了数据增强、多视图注意力和极线聚合模块,有效地强制执行视图一致性并跨多视图输入精炼纹理。广泛的实验和消融研究表明,我们的方法在实现高质量、一致的3D内容方面表现优异,显著优于现有替代方案。该框架为通用3D增强提供了一个灵活且强大的解决方案,在3D内容生成和编辑方面具有广泛的应用。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









