







 文章提出了一个新任务ASQP,旨在联合检测句子中的情感元素。通过将ASQP转化为释义生成问题,可以端到端预测情感四元组,减少错误传播,同时利用预训练模型的语义信息。这种方法在ABSA任务上表现优越,并能促进任务间知识转移。
文章提出了一个新任务ASQP,旨在联合检测句子中的情感元素。通过将ASQP转化为释义生成问题,可以端到端预测情感四元组,减少错误传播,同时利用预训练模型的语义信息。这种方法在ABSA任务上表现优越,并能促进任务间知识转移。
Aspect sentiment quad prediction as paraphrase generation
摘要:
基于方面的情感分析(ABSA)通常涉及四个基本元素,包括方面类别、方面术语、意见术语和情感极性。在本文中引入了方面情感四元预测(ASQP)任务,旨在联合检测给定句子的所有情感元素,这可以揭示更完整的方面层情感结构。本文进一步提出了一种新的释义建模范式,将ASQP任务转换为释义生成过程。一方面,生成公式允许以端到端的方式求解ASQP,从而缓解管道解决方案中潜在的错误传播。另一方面,通过学习以自然语言的形式生成情感元素,可以充分利用情感元素的语义。
Introduction:
为了解决ASQP,一个简单的想法是将四元组预测问题解耦为几个子任务,并以pipeline方式求解它们。然而,这种多阶段方法将受到误差传播的严重影响,因为整体预测性能取决于每一步的准确性。此外,子任务通常表现为token或sequence分类问题,不能充分利用标签的丰富语义信息(即待预测情感元素的含义)。在本文中作者提出以seq2seq(S2S)的方式处理ASQP。一方面,情感四元组可以通过端到端的方式进行预测,减轻pipeline解决方案中潜在的错误传播。另一方面,通过学习生成自然语言形式的情感元素,可以充分利用丰富的标签语义信息。
ASQP任务主要面临两个挑战:
(i)如何将期望的情感信息线性化,以便于S2S学习?
(ii)如何利用预训练模型来处理任务,这是目前解决各种ABSA任务的常见做法。
为了应对这两个挑战,提出了一种新的释义建模范式,将ASQP任务转换为释义生成问题。具体来说,方法是将情感四元组线性化为一个自然语言句子,就好像我们在改写输入句子并突出其主要情感元素一样。
例如,可以把情感四元组(food quality,pasta, over-cooked, negative) 转换成句子“Food quality is bad because pasta is over-cooked”。这样一个目标序列可以与输入句“the pasta is overcooked!”可以用来学习生成模型的映射函数。然后对这种输入-目标对进行微调,无缝地利用大型预训练模型。情感元素的丰富标签语义以自然句的形式自然地与预训练模型的丰富知识融合,而不是直接将所需的情感四元组文本序列作为生成目标。
本文贡献:
1)本文研究了一个新的任务,即方面情感四元预测(ASQP),并引入了两个数据集,对每个样本进行情绪四元素标注,旨在分析更全面的方面级情感信息。
2)本文将ASQP作为释义生成问题来处理,该问题可以一次性预测情感四元组,并充分利用自然语言标签的语义信息。
3)大量实验表明,所提出的释义模型能够有效地处理ASQP和其他ABSA任务,在所有情况下都优于以前最先进的模型。
4)实验还表明,在统一的框架下,该方法促进了相关任务间的知识转移,在低资源环境下尤其有效。
Methodology:
-任务定义:
对于一个句子x,方面情感四组预测(ASQP)旨在预测所有方面级别的情感四组{(c, a, o, p)},它们分别对应于方面类别、方面项、意见项和情感极性。方面类别c属于类别集Vc;方面项a和意见项o通常是句子x中的文本跨度,而如果未明确提及目标,则方面项也可以为空。a∈Vx∪{∅} and o∈Vx。其中Vx表示包含x的所有可能连续空间的集合。情感极性p属于情感类{POS,NEU,NEG}之一,分别表示积极、中性和消极情绪。
-ASQP as Paraphrase Generation:
本文提出了一种释义建模范式,将ASQP任务转换为释义生成问题,并以序列到序列的方式解决它。如图1所示,给定一个句子x,目标是用编码器-解码器模型M生成一个目标序列y:x→y,其中y包含所有需要的情感元素。然后情感四元组Q = { ( c , a , o , p ) }从y中进行预测并提取。
一方面,通过将Q中的情感元素以y中的自然语言形式生成,可以充分利用Q中的情感元素的语义;另一方面,输入和目标都是自然语言句子,可以很自然地利用预训练生成模型中丰富的知识。
-PARAPHRASE Modeling:
为了促进S2S学习,给定句子标签对(x,Q),paraphrase(释义)模型的一个重要组成部分是将情感四元组Q线性化为自然语言序列y,以构建输入目标对(x,y)。理想情况下,我们的目的是在释义过程中忽略输入句子中不必要的细节,同时突出目标句子中的主要情感因素。基于这一动机,将情感四元组q=(c,a,o,p)线性化为一个自然句子,如下所示:

其中Pz(·)是z ∈ { c , a , o , p } 的投影函数,它将情感元素z从原始格式映射到自然语言形式。
通过采用合适的投影函数,一个结构化的情感quad q可以被转换成一个等价的自然语言句子。对于包含多个情感四元组的输入句子x,首先将每个四元组q线性化为如上所述的自然句子。然后将这些句子与一个特殊的符号[SSEP]连接起来,形成最终的目标序列y,包含给定句子的所有情感四元组。
-Target Construction for ASQP:
由于每个情感四元组中的方面类别c和意见项o已经是自然语言形式,因此它们的投影函数保持原始格式Pc© = c 和 Po(o) = o。对于情感极性,预测如下:
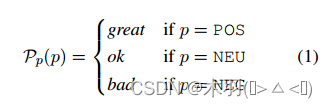
其主要思想是将情感标签从原始的类别格式转换为自然语言表达,并确保整个线性化目标序列的一致性,以便生成模型可以利用情感极性的语义。具体的映射既可以像等式1那样用常识预先定义,也可以用数据相关来定义(利用最常见的一致意见术语为每个情感极性作为情感表达)。
对于方面项,如果没有明确提及,将其映射到隐式代词,否则就可以使用原始的自然语言形式:
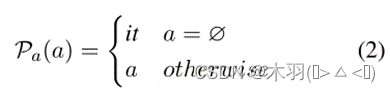
在定义了每个情感元素的具体投影函数后,可以将一个情感四单元转换成包含所有元素的自然语言形式的句子,进行S2S的学习。ASQP任务的两个目标构建示例如图2所示。

-Sequence-to-Sequence Learning:
给定句子x ,编码器首先将其转换成上下文编码的序列e。然后解码器在给定编码输入表示的情况下拟合出目标句子y:pθ(y|e)的条件概率分布,该输入表示由θ参数化。在第i个时间步,解码器输出y_i是基于编码后的输入e和之前的输出y < i:yi = fdec (e,y< i ),其中fdec(·)表示解码器计算。然后应用softmax以获得下一个token的概率分布:
其中W将预测yi映射为一个logit向量,然后可以用来计算整个词汇集的概率分布。
-Training:
通过预训练的编码器-解码器模型如T5,可以使用预训练的参数权重初始化θ,并进一步微调输入-目标对上的参数,以最大化对数似然pθ(y | e):

-Inference and Quad Recovery:
训练结束后,以自回归的方式生成目标序列y′,并在每个时间步中选择词汇集中概率最高的token作为下一个token。然后我们就可以从迭代中提取预测的情绪四元组Q′。具体来说,首先通过检测预定义的[SSEP]来分割可能的多个四元组。然后,对于每个线性化的情感四元序列,根据上节中介绍的建模策略提取情感元素,并将其与Q中的标准情感四元组进行比较。如果这种解码失败,例如,生成的序列违反了定义的格式,将预测视为空。在推理过程中,利用贪婪解码来生成输出序列。
-ABSA as Paraphrase Generation:
它可以很容易地扩展到处理其他ABSA任务:只需要更改每个情感元素的投影函数以适应每个任务的需要。本文以目标方面情感检测(TASD)(Wan等人,2020)和方面情感三元组提取(ASTE)(Peng等人,2020)任务为例:
①TASD任务预测(c,a,p)三元组,其中所有情感元素的条件与ASQP问题中的条件相同。
由于它不涉及意见项预测,只让Po(o)=Pp(p)使用人工构造的意见词作为意见表达式来描述释义中的情感。例如,它将(service general,waiter,NEG)三元组转换为目标句“service general is bad because waiter is bad”。
②对于旨在预测(a,o,p)三元组的ASTE任务,在所有情况下,都将方面类别映射为一个隐式代词,例如“it”(Po(o)=it)。此外,它忽略了隐式方面项,即a∈Vx。然后使用方面词的原始自然语言形式:Pa(a)=a。给出了一个三元组(Chinese food,nice,POS)的例子,可以相应地构造一个目标句“It is great because Chinese food is nice”。
-Cross-task Knowledge Transfer:
paraphrase方法可以在统一的框架中处理各种ABSA任务,这一特性使得知识在相关的ABSA任务之间很容易传递,在低资源设置(即有关任务的标记数据不足)下尤为有利。paraphrase可以首先从TASD和ASTE任务中学习,然后通过对有限的ASQP数据进行微调,迁移到ASQP任务中。由于释义范式提供了一致的训练目标,因此可以首先从TASD和ASTE任务的训练中学习丰富的任务特定知识,然后通过微调(有限的)ASQP数据自然地转移到ASQP任务。
实验结果:
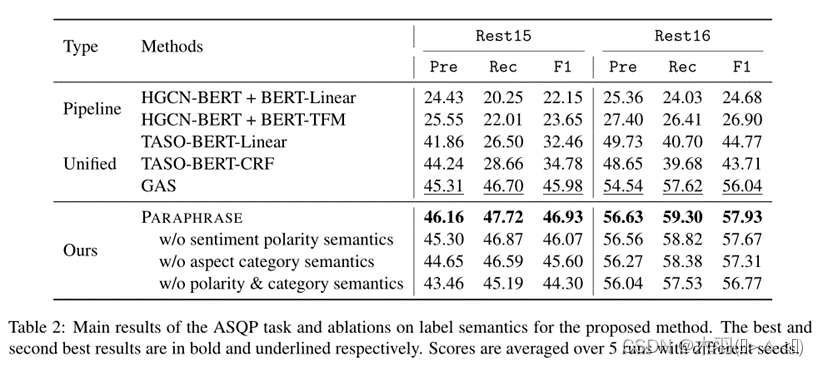

总结:
本文介绍了一种新的ABSA任务,即方面情感四元预测(ASQP),旨在提供更全面的方面级情感图。提出了一种新的释义建模范式,将原始四元预测作为释义生成问题进行处理。在两个数据集上的实验表明,与以前最先进的模型相比,它具有优越性。还证明了该方法提供了一个统一的框架,可以很容易地适应处理其他ABSA任务。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











