







摘要:
由于标记细粒度四元组注释的挑战,这些方法受到数据稀缺的限制。即使是数据增强技术也没有多大帮助,因为很难保持增强样本的质量。此外,所提出的生成模型模板在提取语义和结构信息方面存在不足,无法充分利用语言模型的知识。在本文中为了提高ASQP的性能,提出了一种新的方法,称为DAST (Data Augmentation and Self-Training)。具体来说,DAST首先从原始训练数据中生成大量未标记的数据。然后提出了一种迭代自训练机制,充分利用未标记数据对ASQP模型进行训练。在每次迭代中使用一个基本的ASQP模型和一个判别器来获得带有伪标签的高质量样本,并用增强的数据进一步增强两个模型。最后通过一种新的树状模板来改进ASQP基础模型,该模板改进了不同情感元素之间关系的表示,并利用多任务学习来检测错误预测的双重检查机制。
DAST:面对数据稀缺的挑战,利用迭代自训练框架获得大量高质量的数据。具体来说,首先使用生成器模型生成未标记的数据。然后利用迭代自训练机制对ASQP基模型进行连续训练,并对未标记的数据进行标记。还引入了一个鉴别器来过滤自训练过程中引入的噪声。在每次迭代中,基本模型和鉴别器对当前标记的数据集进行训练。然后利用这两个模型得到最可靠的伪标记数据,扩展了标记数据集,并在下一次迭代中支持更好的基础模型和鉴别器。另一方面,为了更好地捕获ASQP任务的特定于任务的结构信息,采用了一种新的树状模板,该模板显式地表示情感四元组的结构。此外还将多任务训练的思想融入到方法中,提出的双重检查机制利用ATE和OTE任务的结果来验证ASQP预测,这可以提高模型的性能。
自训练:
自训练是一种半监督的方法,它使用未标记的数据和标记的数据来提高学习。在自我训练过程中,学习者首先在标记的数据上训练一个基本模型,然后对未标记的数据进行伪标记。标记数据和伪标记数据都将用于迭代地重新训练模型。在每次迭代中,模型在扩充数据集上进行训练,并生成新的伪标签。这个过程可以重复多次。
方法:
给定一个包含n个单词的句子X = [x1, x2,…,[xn],目标是预测由方面术语(at)、方面类别(ac)、意见术语(ot)和情感极性(sp)组成的方面情绪四元组(at, ac, ot, sp)。
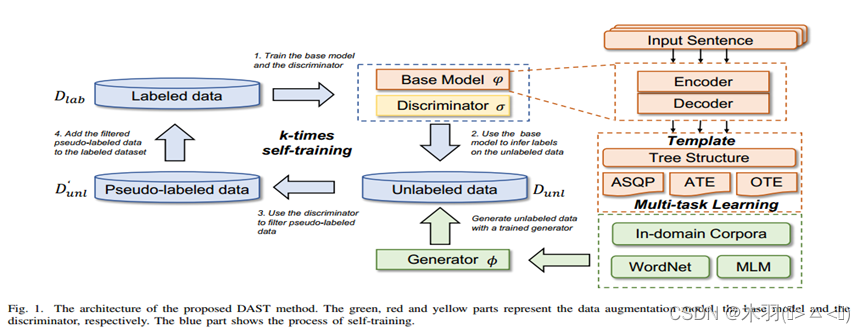
方法DAST的架构,它由三个主要部分组成:一个数据增强模型ϕ![]() (绿色)用于生成新的未标记数据,一个基础模型φ(橙色部分)用于提取情感四元组,一个鉴别器σ(黄色部分)用于将未标记的数据Dunl转换为可用的伪标记数据D'unl。
(绿色)用于生成新的未标记数据,一个基础模型φ(橙色部分)用于提取情感四元组,一个鉴别器σ(黄色部分)用于将未标记的数据Dunl转换为可用的伪标记数据D'unl。
在数据增强模型ϕ![]() 中,使用编码器-解码器模型基于原始标记数据集Dlab生成新样本(即Dunl = ϕ
中,使用编码器-解码器模型基于原始标记数据集Dlab生成新样本(即Dunl = ϕ![]() (Dlab),其中Dunl表示生成的未标记数据)。用外部语料库训练ϕ
(Dlab),其中Dunl表示生成的未标记数据)。用外部语料库训练ϕ![]() ,并在Dlab上进一步微调。然后使用ϕ
,并在Dlab上进一步微调。然后使用ϕ![]() 来生成一堆新句子,作为未标记数据Dunl用于自训练。注意,只在框架中生成一次新数据。
来生成一堆新句子,作为未标记数据Dunl用于自训练。注意,只在框架中生成一次新数据。
基本模型φ基于经典的序列到序列范式。将gold四元组转换为目标序列,并以生成模型为基础模型。此外引入了一种树状模板来显式表达句子中的语义关系。还采用了双重检查机制,以消除错误的预测,从而提高整体准确性。
对于判别器σ,采用多标签分类器来过滤φ产生的伪标签中的噪声。为了更好的训练,首先基于Dlab构造一些负样本Dneg,然后用Dneg∪Dlab训练鉴别器σ。
在此基础上提出了一种迭代自训练机制,分四个步骤在这些模型之间建立连接。在每次迭代中,首先在训练集Dlab上训练一个基模型φ和一个判别器σ。然后使用基本模型φ为这些由数据增强模型ϕ![]() 生成的未标记数据Dunl分配伪标签。再使用鉴别器σ来过滤掉低质量的增强数据,因为伪标签可能会给模型训练带来噪声。最后将剩余的伪标记数据D ' unl (D ' unl = σ(φ(Dunl)))添加到训练集中,并使用更新后的训练集训练新的基模型和鉴别器。通过这个过程迭代k次,我们可以对生成的大多数未标记数据进行标记,并得到更好的基本模型和鉴别器。
生成的未标记数据Dunl分配伪标签。再使用鉴别器σ来过滤掉低质量的增强数据,因为伪标签可能会给模型训练带来噪声。最后将剩余的伪标记数据D ' unl (D ' unl = σ(φ(Dunl)))添加到训练集中,并使用更新后的训练集训练新的基模型和鉴别器。通过这个过程迭代k次,我们可以对生成的大多数未标记数据进行标记,并得到更好的基本模型和鉴别器。
数据增强:
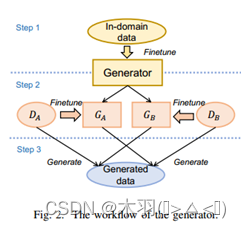
采用T5作为数据发生器ϕ![]() 。为了使其适应任务,使用外部域内语料库和任务特定数据集设计了一个两步训练策略。策略描述如下: 1.利用外部的领域内语料库来训练数据生成器ϕ
。为了使其适应任务,使用外部域内语料库和任务特定数据集设计了一个两步训练策略。策略描述如下: 1.利用外部的领域内语料库来训练数据生成器ϕ![]() ,以学习与领域相关的知识。对于训练,随机屏蔽语料库中每个句子的固定百分比的标记作为输入数据,并将原始句子作为输出。训练目标是重构被屏蔽句子,下一步采用相同的训练目标。2.使用ASQP任务的训练集Dlab进一步微调生成模型。由于训练集的规模较小,生成模型容易出现过拟合,生成的样本可能与原始数据过于相似。为了克服这个问题,每次只在训练中使用一部分样本进行训练,并在生成过程中重建未见的样本。本文将训练集划分为两个子集DA、DB,并分别在两个子集上对生成器进行微调,命名为GA、GB。如图将子集DA馈送给GA以生成新数据,同样将子集DB馈送给GB。
,以学习与领域相关的知识。对于训练,随机屏蔽语料库中每个句子的固定百分比的标记作为输入数据,并将原始句子作为输出。训练目标是重构被屏蔽句子,下一步采用相同的训练目标。2.使用ASQP任务的训练集Dlab进一步微调生成模型。由于训练集的规模较小,生成模型容易出现过拟合,生成的样本可能与原始数据过于相似。为了克服这个问题,每次只在训练中使用一部分样本进行训练,并在生成过程中重建未见的样本。本文将训练集划分为两个子集DA、DB,并分别在两个子集上对生成器进行微调,命名为GA、GB。如图将子集DA馈送给GA以生成新数据,同样将子集DB馈送给GB。
对于数据生成,采用了两种不同的替代策略。一种是同义词替换(Synonym Replacement, SR),用WordNet1中的同义词替换原句子中的一些关键词。另一种是 T5-MLM,它通过用训练好的生成器ϕ填补随机屏蔽句子的空白来增强数据。SR在保留单词的原意方面表现良好,而T5-MLM则增加了生成数据的多样性,使上下文更加连贯。
基本模型:
给定一个符号序列X = [x1,…,xn]作为输入,将四元组的标签通过一个设计好的模板变换为目标序列Y = [y1,…ym]。计算隐藏向量:
![]()
在生成的第t步,自注意解码器使用输入token的隐藏向量和之前的输出Y以自动回归的方式预测第t个token yt。
![]()
每一步的概率是![]() ,整个输出序列P(Y |X)的条件概率逐步组合为:
,整个输出序列P(Y |X)的条件概率逐步组合为:
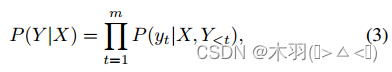
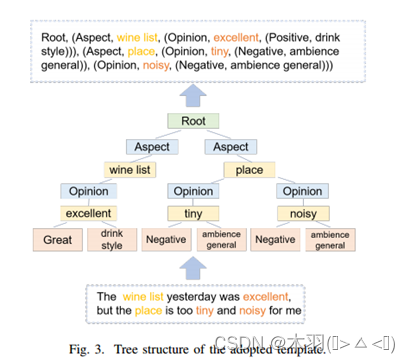
在此基础模型φ的基础上,引入了两种新的设计来提高其性能:树状模板和双重检查机制。
检查机制:
受多任务思想的启发,将ATE和OTE任务合并到我们的模型中,作为双重检查机制。它将用另外两个任务的结果检查ASQP预测。具体来说,假设原始的ASQP输出为YASQP,并且该句子中方面项(at)和意见项(ot)的个数分别为p和q,则我们构建ATE输出为YAT E = [at1, at2,…atp]而OTE输出为YOT E = [ot1, ot2,…otq]。接下来,将YAT E和YOT E添加到YASQP的末尾,用[SEP]来区分每个任务。最终输出形式化为:
![]()
在推理过程中,检查每个四元组中的方面项和意见项是否也出现在ATE和OTE预测中。如果没有,四元组将被丢弃。
鉴别器:
利用鉴别器σ来确保伪标签的正确性。为了简化问题,将四重识别任务转换为成对分类任务,即给定原始句子以及预测的方面和意见术语,输出相应的(sp, ac)对。如果(sp, ac)的分类结果与预测四重组一致,则该四重组通过。假设一个输入句子和一对方面项和意见项(at, ot),我们首先对原始句子进行标记,得到BERT嵌入为E = [eCLS, e1,…en,eSEP]。然后将嵌入输入BERT,得到隐藏状态向量H = BERT(E)。通过H,可以得到方面项和意见项的输出表示为hat和hot,它们的平均向量为uat = avg(hat)和uot = avg(hot)。我们将at和ot连接起来作为最终的表示O,对于每个(sp, ac)类别c,将O提供给具有Sigmoid函数的全连接层
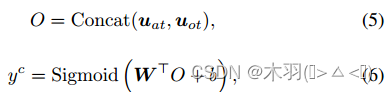
由于我们只能从训练集中得到正样本,所以我们自己构造负样本Dneg。我们从原句中随机抽取几个连续的词来替换方面词或意见词,但保持其对应的词不变。采样的单词可以部分地与原始术语重叠,但不能完全相同。
迭代自我训练机制

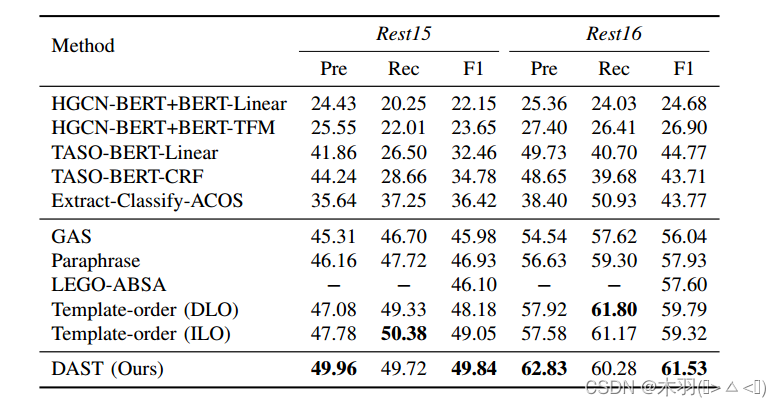
实验结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











