







吴恩达机器学习学习记录1:监督机器学习回归和分类
这是第一波笔记(第一课:Supervised Machine Learning Regression and Classification),会结合ppt进行注释并补充笔记,欢迎交流学习,教程视频来自B站(P1-P41,涵盖三周的课程):(超爽中英!) 2024公认最好的【吴恩达机器学习】教程!附课件代码 Machine Learning Specialization_哔哩哔哩_bilibili
目录
(p26)一些技巧使梯度下降更好的工作:特征缩放part2 如何实现特征缩放
(p31)Classification分类 Motivation
引入
本文主要是跟着吴恩达学习机器学习的过程记录,教程来自B站,笔记主要是结合视频、ppt内容展开,很基础,主要是跟着大佬的思维记下大佬讲解的内容,可能还涉及一些相关知识点的记录和练习,仅作学习交流,若有不对的地方欢迎指正。
首先是第一周的内容(P1-P20):
一、机器学习的定义和主要问题与算法
机器学习的定义:"Field of study that gives computers the ability to learn without being explicitly programmed.无需明确编程,赋予计算机学习能力的研究领域"(Arthur Samuel 1959)。机器学习可应用于语音识别、计算机视觉、增强现实、自动驾驶、大规模工业、电子商务、医疗保健等领域。
主要术语:
- 监督学习Supervised learning:实际使用最多,学习X(INPUT) TO Y(OUTPUT LABEL),关键特征:给出学习算法示例、包含正确答案。
| 监督学习Supervised learning | |
| 回归算法(regression algorithm) | 分类算法(classification algorithm) |
| predict a number,infinitely many possible outputs(predict input,output or X to Y mapping) | predict categories,small number of possible outputs |
| 从无限多的数字中预测数字,最终学会只接受输入就可以输出合理准确的预测或是学习映射关系 | 预测类别(categories or classes),从所有可能输出的一小部分中对一个类别做出预测,预测结果不一定是数字 |
| 如预测房价 | 如乳腺癌肿瘤的大小与恶性良性的分类 |
- 无监督学习Unsupervised learning:数据集没有标签。
| 无监督学习Unsupervised learning | ||
| 聚类算法 clustering algorithm |
异常检测 anomaly detection |
降维 dimensionality reduction |
| 将未标记的数据并尝试分类到不同集群中,不输出y而是给y分类 | 检测异常事件 | 将大数据集压缩为小的数据集 |
| 如谷歌新闻将pandas相关的新闻放在一起、市场细分等 | 如金融系统检测异常交易 | |
- 强化学习Reinforcement learning:
- 补充:Jupyter Notebooks:是一个Web应用程序,允许您创建和共享包含实时代码,方程,可视化和说明文本的文档。 用途包括:数据清理和转换,数值模拟,统计建模,机器学习等等。
- 安装参考以下Jupyter Notebooks的安装和使用介绍_jupyter的安装-优快云博客
- 打开资料包的文件可以跑代码,简单的使用指南:markdown 单元格是插入文本注释,添加叙述性和解释性文本;code cell单元格是插入代码,点击Run按钮执行,也可以快捷键
Ctrl+Enter执行代码。 - 此外,进入jupyter之后是默认打开C盘,如果要打开对应目录的文件参考以下链接
- Jupyter使用 | Jupyter Notebook打开默认文件夹以外的文件_jupyter打开默认路径外的代码-优快云博客
我的步骤: - 1.打开anaconda prompt后输入cd+想进入的盘+文件夹名称,如果不在C盘的话:cd /d +位置;此外路径中有空格时可能出错,加""可以进入,如
cd "H:\1 宁的研究生资料\6 2024研二上 组会 小论文 大论文\4 中期前的准备工作\吴恩达机器学习教程相关资料\2024吴恩达资料\A最新版 吴恩达机器学习Deeplearning.ai"cd "H:\1 宁的研究生资料\6 2024研二上 组会 小论文 大论文\4 中期前的准备工作\吴恩达机器学习教程相关资料\2024吴恩达资料\A最新版 吴恩达机器学习Deeplearning.ai" -
cd /d H:\1 宁的研究生资料\6 2024研二上 组会 小论文 大论文\4 中期前的准备工作\吴恩达机器学习教程相关资料\2024吴恩达资料\A最新版 吴恩达机器学习Deeplearning.ai - 2.进入想要打开的文件夹后输入 jupyter notebook
-
jupyter notebook
二、监督学习的实现算法详解(单变量线性回归)
2.1 线性回归模型
回归模型(regression model)是一种特殊类型的监督学习模型,预测数字作为输出。
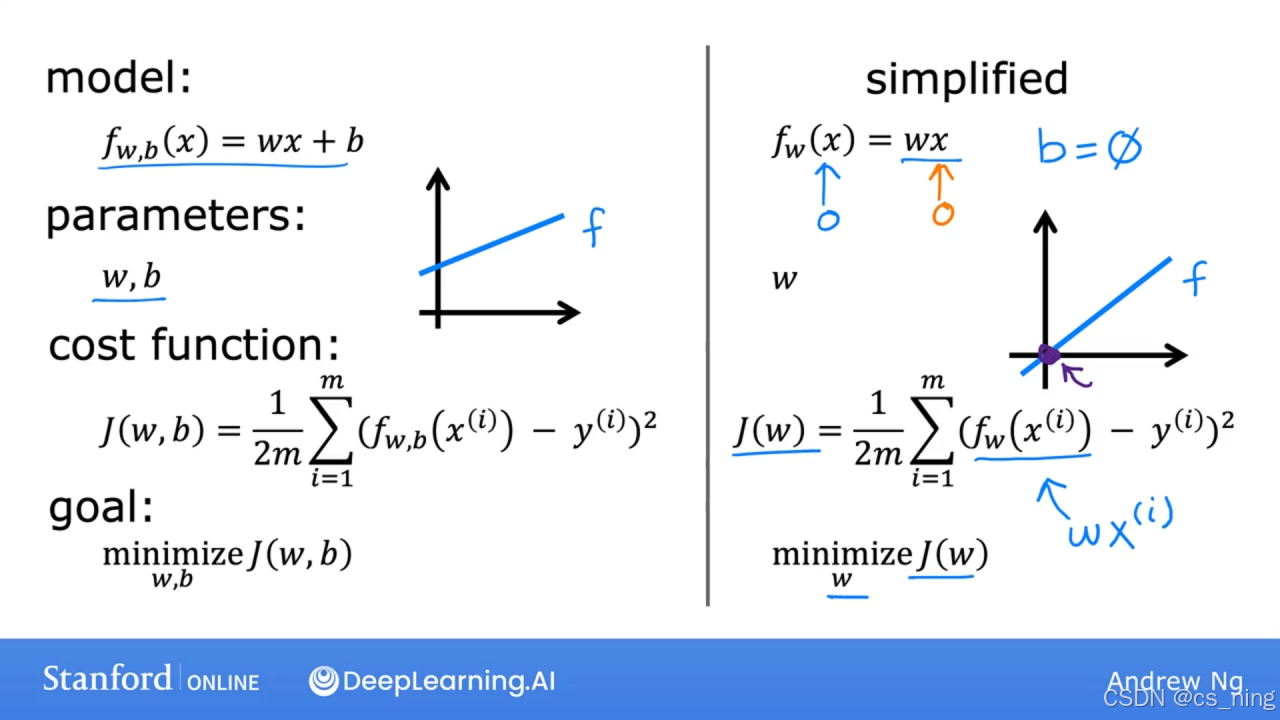
单变量线性回归f(x)=wx+b。
(截图传过来有点麻烦,部分图片会参考其他笔记,下图参考:机器学习(吴恩达)_吴恩达机器学习-优快云博客,后面如有再次出现不再标注)

2.2 代价函数/损失函数(cost function)
cost function是用于表示当前回归方程的预测值与实际值之间的误差,即衡量一条直线与训练数据的拟合程度,最小化Cost函数就可以的得到最准确的回归直线。
error表示预测值与实际值的误差,m为训练集的数量,J(w,b)是平均平方误差再额外除以2(额外除以2是为了计算看起来更整洁)下面的cost function被称为平方误差损失函数,是目前最常见的回归函数,j(w,b)是重写方程。
找到平方误差损失函数的最小值可以确定w,b两个参数的值从而确认最佳的线性回归函数。

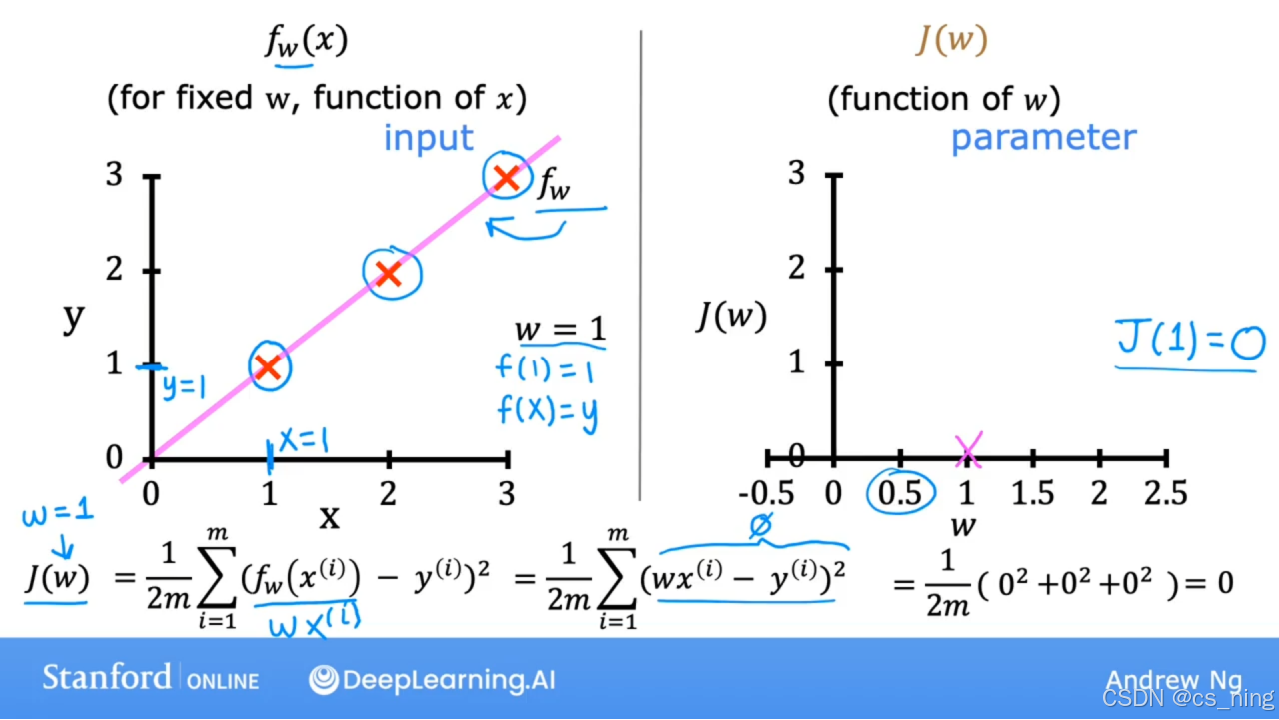
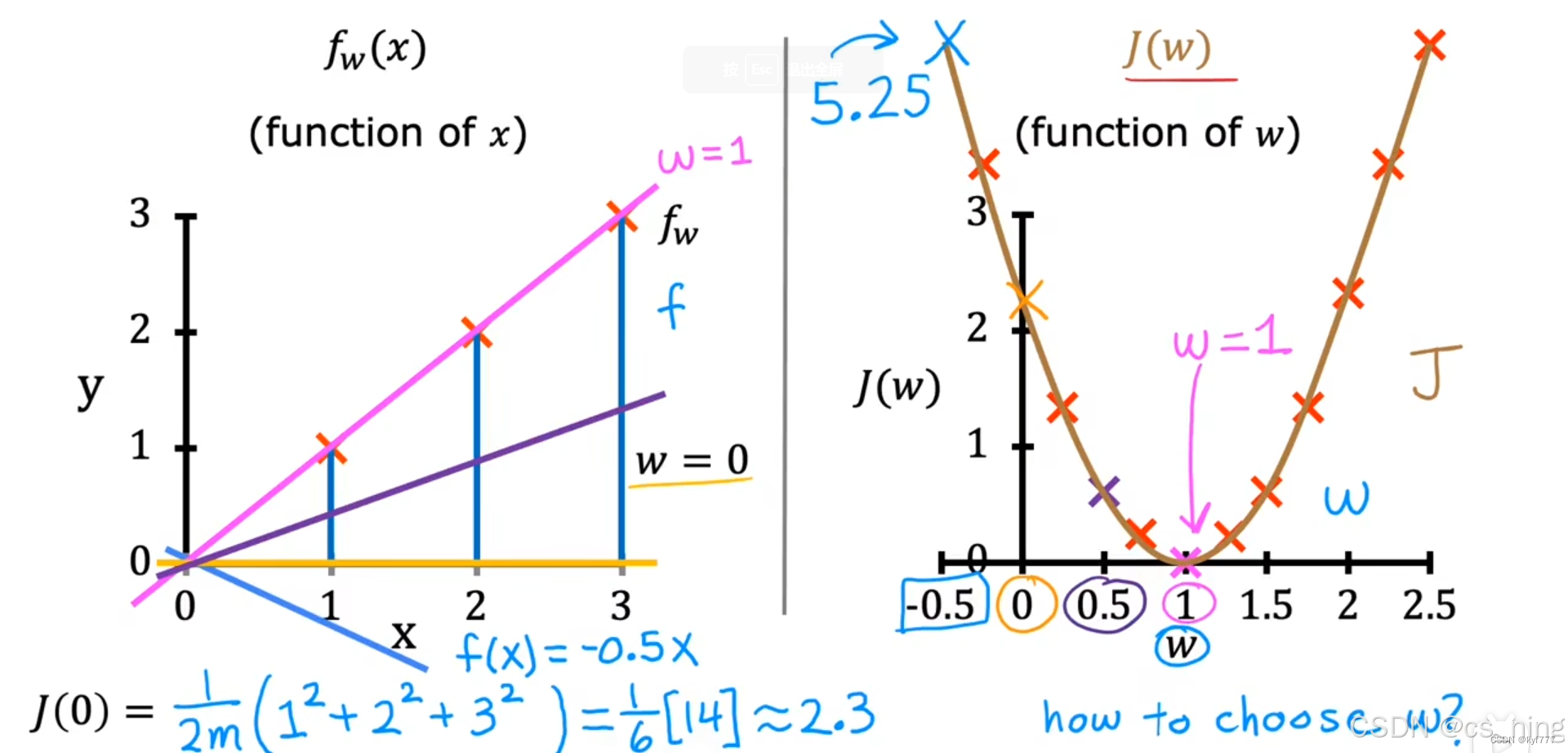
简化的f(x)函数,当b=0时,w的选取对f(x)函数的影响以及对应的成本函数J(w)的影响
所以可以通过看成本函数何时最小,找到使J(w)最小化的w。
(嘿嘿找到了ppt,后面尽量附上原文件的ppt,会更清晰一点,B站视频字幕有点遮挡。)
前面是把b=0方便理解,当b≠0时,涉及w和b两个变量,如图一(超级碗.jpg);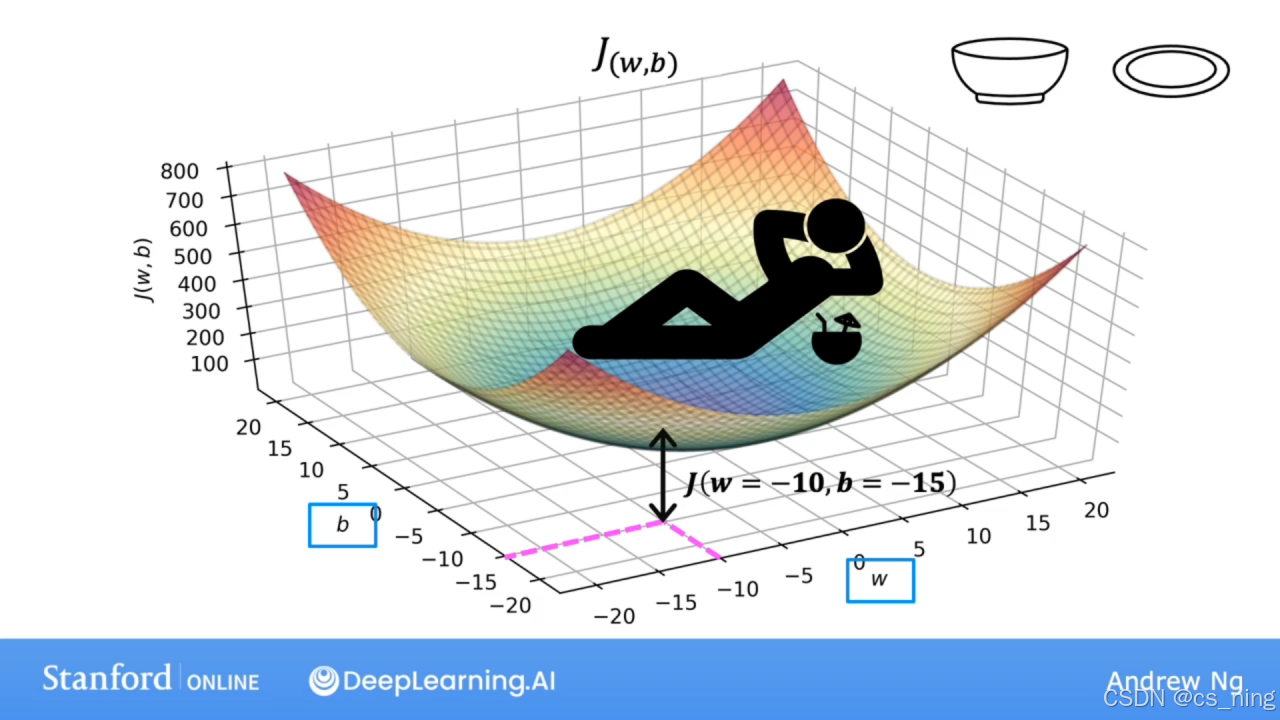 另外一种可视化损失函数的方法是等高线图的方式绘制,获得等值线图的方式是在下面三维曲面中进行水平切片,切到的点都是J值相同的点,这些点再右上角的图中连接起来,每个水平切片都显示为某个椭圆/线,J值最小的在“碗底”即最小的同心椭圆的中心点,如下图。
另外一种可视化损失函数的方法是等高线图的方式绘制,获得等值线图的方式是在下面三维曲面中进行水平切片,切到的点都是J值相同的点,这些点再右上角的图中连接起来,每个水平切片都显示为某个椭圆/线,J值最小的在“碗底”即最小的同心椭圆的中心点,如下图。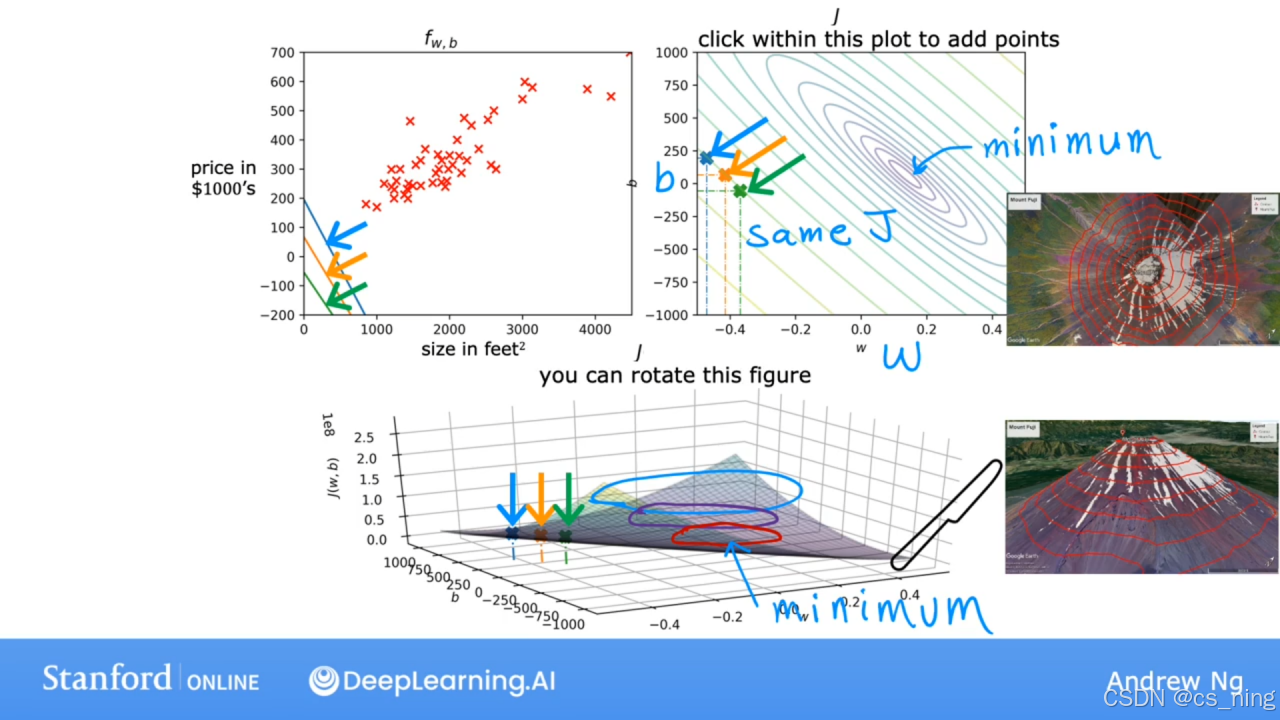
2.3 梯度下降
高效的算法可以自动寻找w和b的值寻找最好的拟合线,使损失函数最小,如梯度下降算法(gradient descent),不仅可以训练线性回归,还能训练ai大模型,也称为深度学习模型(形象的表达:站在山峰找山谷最低点,找局部极小值)。
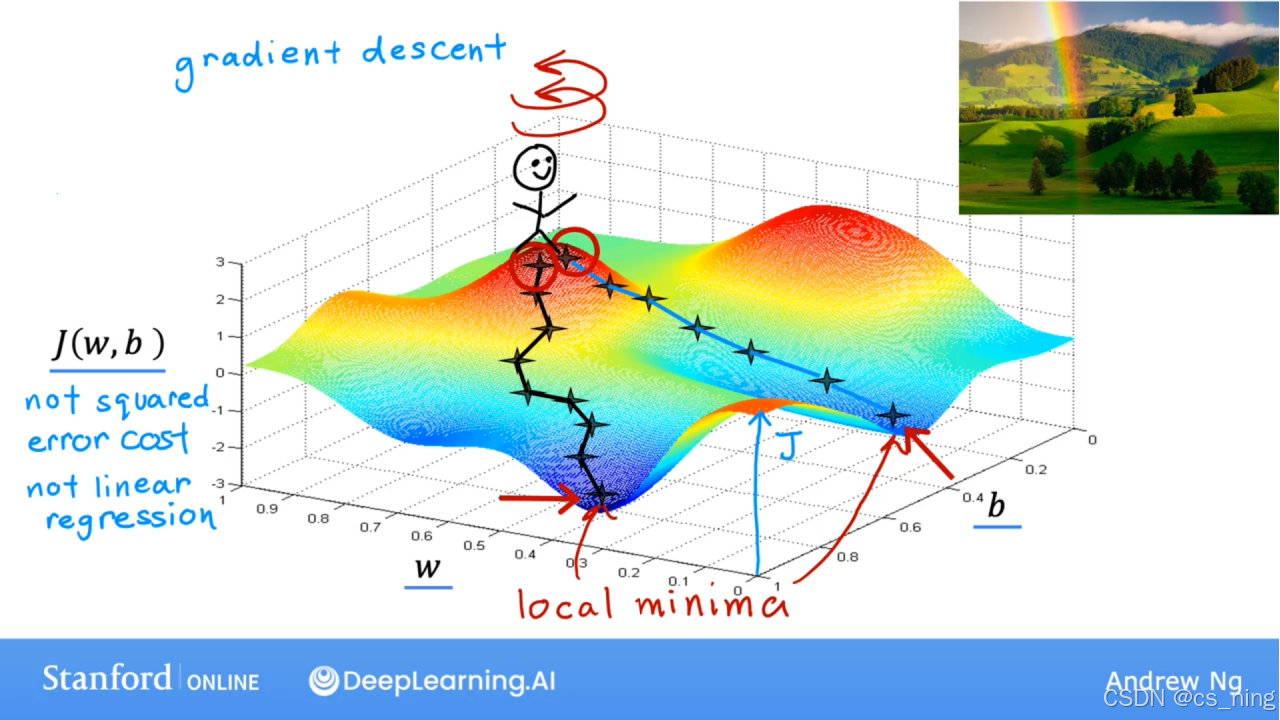
大佬用一页ppt说了梯度下降的实现,首先说了“=”可以表示赋值或判断true/false,左边的式子中=是赋值运算符,即不断赋予w和b新的值实现梯度下降,不断重复更新直到算法收敛,达到局部最小值;其中α表示学习率(步长),范围是0~1的小正数,控制下坡路的幅度;后面粉色框框是损失函数J的导数项,控制下坡路的方向。
当w和b同时更新,注意等式右侧的w和b应该都是更新前的,因此引入tmp_w和tmp_b存储更新后的数据,右侧的做法则不对,b更新时用的w不是更新前的w。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2730
2730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











