









 本文介绍如何使用Python和多线程技术从斗图啦网站下载表情包,包括同步和异步爬虫的实现方法。
本文介绍如何使用Python和多线程技术从斗图啦网站下载表情包,包括同步和异步爬虫的实现方法。
目标:从网站斗图啦下载表情包
斗图啦网页示例:
1、多线程下载表情包之同步爬虫完成
import requests
from lxml import etree
from urllib import request # 保存图片
import os # 为获取后缀名字
import re # 替换掉文件名中的特殊字符
# url = 'https://www.doutula.com/photo/list/'
def parse_page(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
response = requests.get(url, headers=headers, verify=False)
text = response.text
html = etree.HTML(text)
imgs = html.xpath("//div[@class="page-content text-center"]//img[@class!='gif']")
for img in imgs:
img_url = img.get('data-original') # get()直接取得某属性的内容
alt = img.get('alt')
alt = re.sub(r'[\??\.,。!]', '', alt) # windows系统中文件名中不能含有特殊字符,这里替换掉
suffix = os.path.splitext(img_url)[1] # 获取后缀名字
filename = alt + suffix
request.urlretrieve(img_url, 'images/' + filename)
def main():
for x in range(1, 11): # 只获取前10页内容(只会取到1-10)
url = 'https://www.doutula.com/photo/list/?page=%d' %x # 构造url
parse_page(url)
if __name__ == '__main__':
main()
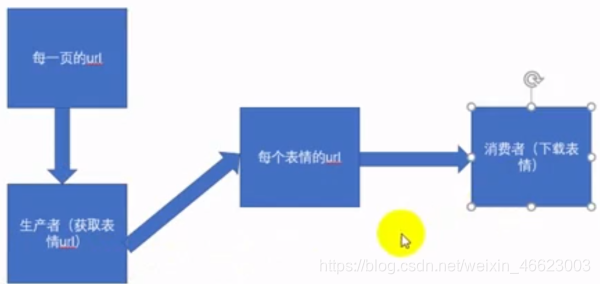
2、多线程下载表情包之异步爬虫完成
import requests
from lxml import etree
from urllib import request # 保存图片
import os # 为获取后缀名字
import re # 替换掉文件名中的特殊字符
from queue import Queue
import threading
class Procuder(threading.Thread):
def __init__(self,page_queue,img_queue,*args,**kwargs):
super(Procuder,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
response = resquests.get(url,headers=self.headers)
text = response.text
html = etree.HTML(text)
imgs = html.xpath("//div[@class="page-content text-center"]//img[@class!='gif']")
for img in imgs:
img_url = img.get('data-original') # get()直接取得某属性的内容
alt = img.get('alt')
alt = re.sub(r'[\??\.,。!]', '', alt) # windows系统中文件名中不能含有特殊字符,这里替换掉
suffix = os.path.splitext(img_url)[1] # 获取后缀名字
filename = alt + suffix
self.img_queue.put((img_url,filename)) # 传入一个元组
class Consumer(threading.Thread):
super(Consumer, self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty(): # 如果两个都为空
break
img_url,filename = self.img_queue.get() # 返回来的时元组
request.urlretrieve(img_url,'images/'+filename) # 存在文件夹“images”下
print(filename+'下载完成!')
def main():
page_queue = Queue(100) # 爬取100页
img_queue = queue(1000) # 图片比较多,大一点的队列
for x in range(1,101):
url = 'https://www.doutula.com/photo/list/?page=%d' %x # 构造url
page_queue.put(url)
for x in range(5):
t = Procuder(page_queue,img_queue)
t.start()
for x in range(5):
t = Consumer(page_queue,img-Queue)
t.start()
if __name__ == '__main__':
main()

















 2739
2739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









