







 本文介绍了ARIMA模型,一种经典的时间序列预测模型,用于预测中国结直肠癌标化发病率。文章详细阐述了建模流程,包括时间序列平稳化、模型识别与定阶、参数估计和诊断检验,以及模型预测效果的评估。最后,提供了代码实现和预测图。
本文介绍了ARIMA模型,一种经典的时间序列预测模型,用于预测中国结直肠癌标化发病率。文章详细阐述了建模流程,包括时间序列平稳化、模型识别与定阶、参数估计和诊断检验,以及模型预测效果的评估。最后,提供了代码实现和预测图。
ARIMA模型
定义及表达式
ARIMA(autoregressive integrated moving average model)模型由Box与Jenkins于上世纪七十年代提出,是一种经典的时间序列预测模型。它用特定的数学模型描述与时间相关的一组随机变量之间所具有的自相关性,以掌握预测对象的发展趋势,并根据已获得的时序资料对其未来进行短期预测。ARIMA模型是将自回归模型AR§、移动平均模型MA(q)以及差分法结合在一起,故又叫做差分自回归移动平均模型,记做ARIMA(p,d,q),其中p为自回归项数,q为移动平均项数,d为时间序列平稳时所做的差分次数。以1990-2019年中国结直肠癌标化发病率数据为基础构建ARIMA(p,d,q)模型,其数学表达式如下:

建模流程
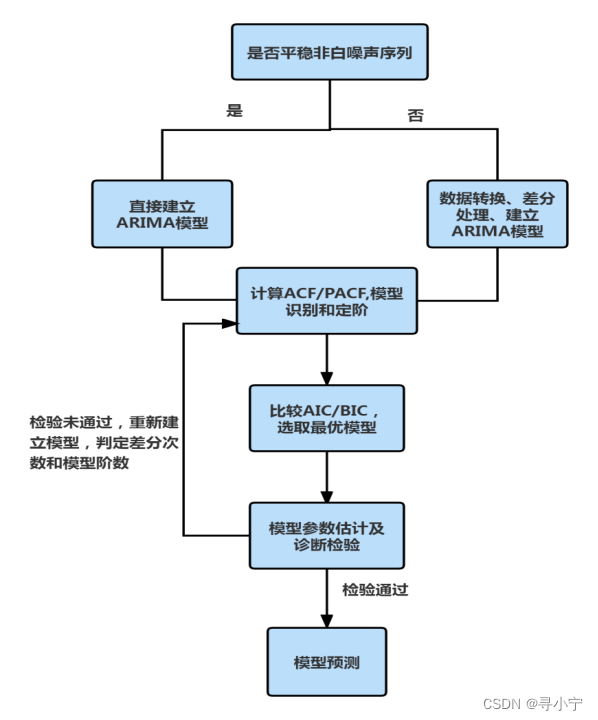
具体建模步骤
1. 时间序列平稳化
ARIMA(p,d,q) 模型建模条件是观察时间序列的平稳性,此种平稳是非白噪声序列的平稳(时间序列的建模基础是基于序列之间存在的自相关性,即通过建模提取序列中蕴含的相关信息)。可应用两种方法对时间序列进行平稳性检验,一种是图示法,通过观察样本时间序列图及自相关系数( autocorrelation function,ACF) 图作出判断;另一种是统计学检验,单位根检验( augmented dickey-fuller,ADF) ,P<0. 05 时,认为序列平稳;对于非平稳时间序列,可通过数据转换和差分处理实现序列平稳化。(自相关系数来描述随着滞后期数的增加,平稳序列的自相关系数会很快的衰减向零,反之,非平稳序列衰减较慢,或存在单调/周期波动规律)
2. 模型识别和定阶
对于非平稳时间序列,通过差分处理后,绘制差分后序列自相关系数图(ACF)和偏自相关系数图(PACF)分析时间序列的短期自相关特征,初步确定模型的各个阶数(自回归阶数 p,移动平均阶数 q )取值,同时调用 R软件中的auto.arima 函数对序列进行自动定阶,结合二者结果一般可构造多个拟合模型,比较各个拟合模型的赤池信息量准则(Akaike Information Criterion,AIC)和贝叶斯信息准则(Bayesian information criterion,BIC),获取最优拟合模型。
3. 模型参数估计和诊断检验
对拟合好的模型残差序列进行白噪声检验(其主要目的是检验模型的有效性,看看是否将序列中蕴含的相关信息充分提取,即拟合模型的残差项不应该再蕴含任何自相关信息),检验统计量为 QLB(Ljung-Box)统计量,当p>0.05 时,表明拟合模型的残差序列为白噪声序列,即该拟合模型显著有效(也可以绘制残差分布图进行检验)。同时对模型参数进行估计,通过计算 t 统计量,对拟合模型各参数的显著性进行检验(其目的是剔除模型中对因变量影响不明显的参数,进而使模型更加精简准确),当p<0.05 时,表明该模型参数显著非零,即拟合模型最精简准确。
4. 模型预测及效果评价
对历史序列数据进行拟合并对未来发展进行预测,均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)以及平均绝对百分比误差(mean absolute percentage error,MAPE)作为模型拟合预测效果的评价指标。

代码实现
#####时间序列模型####
rm(list = ls())
##安装载入软件包##
if(!requireNamespace("dplyr","purrr","ggplot2","reshape2","forecast","funitRoots",quietly=TRUE))
install.packages("dplyr","purrr","ggplot2","reshape2","forecast","funitRoots")
require(dplyr)
require(purrr)
require(forecast)
require(fUnitRoots)
require(ggplot2)
require(reshape2)
setwd("f://时间序列模型")
read.csv("test.csv",header=T)->mydata
mm<-mydata%>%dplyr::filter(</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









