






思路:逐条输入GSM8K数据集 获得模型输出并于数据集中的回答进行比对
from llama_cpp import Llama # 从 llama_cpp 导入 Llama 类,用于加载并调用 Llama 模型
import time # 导入 time 模块用于时间测量
import pandas as pd # 导入 pandas 用于数据处理,尤其是读取和操作 Parquet 文件
from sklearn.metrics import accuracy_score # 导入 accuracy_score,用于计算准确率
import numpy as np # 导入 numpy,用于数值计算
from nltk.translate.bleu_score import sentence_bleu # 导入 BLEU 分数计算工具
from rouge import Rouge # 导入 ROUGE 分数计算工具
import math # 导入 math 库,用于数学运算
# 加载 Parquet 文件,读取训练数据
train_main = pd.read_parquet('/home/lqsilicon/retarded_bar/main/train-00000-of-00001.parquet')
# 加载模型,指定模型路径
model = Llama(model_path='/home/lqsilicon/Public/xgx/llama.cpp/models/llama-2-7b-chat.Q4_0.gguf')
# 从训练数据中提取问题和答案列,分别存储为列表
questions = train_main['question'].tolist() # 将问题列转换为列表
answers = train_main['answer'].tolist() # 将答案列转换为列表
# 打印问题总数,用于确认数据是否加载正确
print(f"问题总数: {len(questions)}")
# 评测模型性能的函数
def evaluate_performance(model, questions, answers):
total_time = 0 # 初始化总推理时间
correct = 0 # 初始化正确答案数量
total = len(questions) # 问题总数
results = [] # 用于存储所有评测结果
rouge = Rouge() # 创建 ROUGE 实例,用于计算 ROUGE 分数
rouge_scores = [] # 用于存储 ROUGE 分数
bleu_scores = [] # 用于存储 BLEU 分数
perplexities = [] # 用于存储困惑度
# 使用批量推理优化
batch_size = 8 # 设置每次批处理的大小,可以根据实际情况调整
num_batches = (total + batch_size - 1) // batch_size # 计算批次数量
# 对每个批次进行推理评测
for batch_idx in range(num_batches): # 遍历所有批次
start_idx = batch_idx * batch_size # 当前批次的开始索引
end_idx = min((batch_idx + 1) * batch_size, total) # 当前批次的结束索引,确保不越界
batch_questions = questions[start_idx:end_idx] # 当前批次的问题
batch_answers = answers[start_idx:end_idx] # 当前批次的答案
# 记录批次推理的开始时间
batch_start_time = time.time()
# 获取批次问题的模型回答
batch_responses = [model(question, max_tokens=4096) for question in batch_questions]
# 记录批次推理的结束时间
batch_end_time = time.time()
# 计算本批次的推理时间
batch_inference_time = batch_end_time - batch_start_time
total_time += batch_inference_time # 累加总推理时间
# 处理批次中的每一个问题及其模型回答
for i in range(len(batch_questions)):
question = batch_questions[i] # 当前问题
expected_answer = batch_answers[i] # 当前问题的期望答案
response = batch_responses[i] # 当前问题的模型回答
# 获取并去除多余空白符的生成文本
generated_text = response['choices'][0]['text'].strip()
# 检查生成的文本是否为空
if not generated_text:
print(f"警告: 模型未生成有效的文本。跳过问题: {question}")
continue # 跳过该问题,继续下一个问题
# 计算 BLEU 分数,基于期望答案和生成答案
reference = expected_answer.split() # 将期望答案按空格分词
candidate = generated_text.split() # 将生成的文本按空格分词
bleu_score = sentence_bleu([reference], candidate) # 计算 BLEU 分数
bleu_scores.append(bleu_score) # 将该 BLEU 分数加入列表
# 计算 ROUGE 分数
rouge_score = rouge.get_scores(generated_text, expected_answer)[0] # 获取 ROUGE 分数
rouge_1 = rouge_score['rouge-1']['f'] # 获取 ROUGE-1 的 F1 值
rouge_2 = rouge_score['rouge-2']['f'] # 获取 ROUGE-2 的 F1 值
rouge_l = rouge_score['rouge-l']['f'] # 获取 ROUGE-L 的 F1 值
rouge_scores.append((rouge_1, rouge_2, rouge_l)) # 将 ROUGE 分数存入列表
# 计算困惑度(Perplexity)
perplexity = math.exp(-batch_inference_time / len(batch_questions)) # 使用困惑度公式
perplexities.append(perplexity) # 将困惑度存入列表
# 输出当前问题的推理结果和相关评测指标
print(f"问题: {question}")
print(f"答案: {expected_answer}")
print(f"模型回答: {generated_text}")
print(f"推断时间: {batch_inference_time / len(batch_questions):.4f} seconds") # 输出平均推理时间
print(f"BLEU: {bleu_score:.4f}, ROUGE-1: {rouge_1:.4f}, ROUGE-2: {rouge_2:.4f}, ROUGE-L: {rouge_l:.4f}, Perplexity: {perplexity:.4f}\n")
# 保存该问题的结果
results.append([question, expected_answer, generated_text, batch_inference_time / len(batch_questions), bleu_score,
rouge_1, rouge_2, rouge_l, perplexity])
# 计算总体评测结果
average_bleu = np.mean(bleu_scores) # 计算平均 BLEU 分数
average_rouge_1 = np.mean([score[0] for score in rouge_scores]) # 计算平均 ROUGE-1 分数
average_rouge_2 = np.mean([score[1] for score in rouge_scores]) # 计算平均 ROUGE-2 分数
average_rouge_l = np.mean([score[2] for score in rouge_scores]) # 计算平均 ROUGE-L 分数
average_perplexity = np.mean(perplexities) # 计算平均困惑度
accuracy = correct / total # 计算模型准确率
average_time = total_time / total # 计算平均推理时间
# 输出总体评测结果
print(f"总问题数: {total}")
print(f"准确率: {accuracy * 100:.2f}%") # 输出准确率
print(f"平均推断时间: {average_time:.4f} seconds") # 输出平均推理时间
print(f"平均 BLEU: {average_bleu:.4f}") # 输出平均 BLEU 分数
print(f"平均 ROUGE-1: {average_rouge_1:.4f}") # 输出平均 ROUGE-1 分数
print(f"平均 ROUGE-2: {average_rouge_2:.4f}") # 输出平均 ROUGE-2 分数
print(f"平均 ROUGE-L: {average_rouge_l:.4f}") # 输出平均 ROUGE-L 分数
print(f"平均困惑度: {average_perplexity:.4f}") # 输出平均困惑度
return results # 返回评测结果
# 执行评测
results = evaluate_performance(model, questions, answers)
# 将评测结果保存到 CSV 文件
results_df = pd.DataFrame(results, columns=["Question", "Expected Answer", "Generated Answer", "Inference Time", "BLEU",
"ROUGE-1", "ROUGE-2", "ROUGE-L", "Perplexity"]) # 将结果转换为 DataFrame
results_df.to_csv("evaluation_results.csv", index=False) # 保存为 CSV 文件,索引不保存

一些概念解释:
Parquet 是一种开源的列式存储文件格式,通常用于大数据处理和分析。它被设计为一种高效、压缩的存储格式,可以存储大量数据,同时保持较高的读取性能。Parquet 文件格式广泛应用于像 Hadoop、Spark 等大数据处理框架中,特别适合用于存储和处理结构化和半结构化数据。在 Python 中,使用 pandas 可以方便地读取和处理 Parquet 文件。
gguf 格式
gguf 是一种用于存储和优化 Llama 模型推理的格式,它旨在提高模型在推理时的效率和性能。gguf 格式与 LLaMA 模型的标准格式相比,进行了特定的优化,使得在内存和存储方面更加高效,且可以在各种硬件平台上更好地执行
使用 Llama 模型和 gguf 格式
在实际使用中,Llama 模型通常是以标准格式(如 PyTorch、TensorFlow 格式等)发布的,但是可以通过一些工具(如 llama.cpp)将模型转换为 gguf 格式以优化推理性能。转换后的模型可以使用 llama.cpp 相关工具进行加载,从而高效地进行推理。
ROUGE 分数概述
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 是一种用于评估自动生成文本与参考文本之间相似度的指标,广泛应用于自然语言处理(NLP)任务,尤其是在文本生成、摘要生成、翻译等任务中。ROUGE 指标主要通过计算生成文本和参考文本之间的n-gram重合度来衡量文本的质量。
ROUGE 包含多个子指标,常见的有 ROUGE-1、ROUGE-2 和 ROUGE-L。每种 ROUGE 分数都基于不同的评估方式,下面将详细介绍这些常见的 ROUGE 分数。
ROUGE 分数的计算方法
ROUGE 计算的核心是基于 precision、recall 和 F1 score,这些度量标准的计算方法如下:
- Precision:生成文本中与参考文本匹配的n-gram数量与生成文本中的n-gram总数之比。
- Recall:生成文本中与参考文本匹配的n-gram数量与参考文本中的n-gram总数之比。
- F1 Score:Precision 和 Recall 的调和平均数,是衡量综合性能的指标。
对于每种 ROUGE 指标,都会计算 Precision、Recall 和 F1 分数。
什么是 n-gram?
n-gram 是自然语言处理(NLP)中一种常见的文本处理模型,用于表示和分析连续的 n 个词或字符的序列。它是基于上下文的,尤其关注一个词或字符的相邻词或字符的关系。
在 n-gram 模型中,n 代表连续单元的数量。根据 n 的不同,n-gram 可以分为不同的类型,如 unigram、bigram、trigram 等。
n-gram 的定义:
- n-gram 是一个由 n 个连续的项目(通常是单词或字符)组成的序列。对于文本来说,这些项目通常是 单词 或 字符。
n-gram 在 NLP 中的应用
-
语言建模:
- n-gram 模型广泛应用于语言建模任务中。例如,在机器翻译、文本生成、语音识别等领域,n-gram 模型通过计算词序列的概率来预测下一个词。通过考虑过去的 n-1 个词来预测当前词。
- 例如,在生成一个句子的过程中,基于前面的单词预测下一个单词,n-gram 模型就可以用来计算这种概率。
-
文本分类和情感分析:
- 在情感分析任务中,n-gram 可以帮助捕捉文本中连续的词语搭配,比如短语或常见的表达方式,这些搭配往往对情感的判断至关重要。
-
机器翻译:
- 在机器翻译中,n-gram 模型可以帮助评估翻译的质量。通过计算翻译中 n-gram 的重合度,来衡量翻译文本与参考翻译的相似度。
-
信息检索:
- 在搜索引擎中,n-gram 模型可以帮助理解用户查询的意图,并根据查询中的词序列找到更相关的文档。
-
拼写校正:
- n-gram 模型也常用于拼写校正任务。例如,给定一个错别字,n-gram 可以根据上下文词序列的统计信息来判断用户最可能想打的正确单词。
什么是 BLEU(Bilingual Evaluation Understudy)?
BLEU(Bilingual Evaluation Understudy)是一个用于自动评估机器翻译(MT)质量的指标,特别是用于评估生成文本(例如机器翻译、文本生成等任务)与参考文本之间的相似度。BLEU 衡量的是生成文本的 n-gram 与参考文本中的 n-gram 的匹配程度。
BLEU 是一种 精确度(Precision)度量,它通过计算生成文本中的 n-gram 与参考文本中的 n-gram 的重合度,来评估翻译的质量。BLEU 的核心思想是,通过比较机器生成的翻译与人工参考翻译之间的相似性,来量化机器翻译的质量。
BLEU 评分的计算步骤
-
计算各个 n-gram 的精确度:比如,计算生成文本与参考文本中 unigram、bigram、trigram 等的匹配度。
n-gram 计算:计算机器翻译结果(候选翻译)和参考翻译之间的 n-gram 重叠情况。常见的 n-gram 包括 unigram(单词级的1-gram)、bigram(2-gram)等。
-
计算长度惩罚:
如果生成文本比参考文本短,会减少 BLEU 得分,避免机器生成极短的翻译。 -
综合计算 BLEU 得分:
将精确度和长度惩罚结合,计算最终的 BLEU 分数。
什么是困惑度(Perplexity)?
在大模型性能评估中,困惑度(Perplexity, PP) 是一种常用的衡量语言模型性能的指标,特别是在自然语言处理(NLP)任务中,如文本生成、机器翻译等。
困惑度的定义
困惑度衡量的是模型对预测下一个词的“困惑”程度,换句话说,它是模型预测准确性的倒数。困惑度越低,说明模型对数据的拟合越好。
具体来说,困惑度 是模型预测给定词序列的概率的倒数的指数。公式为:
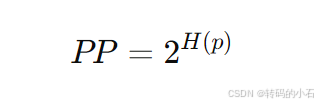
其中,H(p)是模型对一个词序列的交叉熵(Cross-Entropy),也就是说,困惑度可以从交叉熵中计算出来。
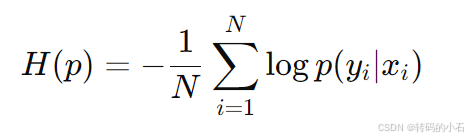
交叉熵和困惑度的关系
交叉熵是衡量模型预测分布与真实分布之间差异的度量,公式为:
H(p)=−1N∑i=1Nlogp(yi∣xi)H(p) = - \frac{1}{N} \sum_{i=1}^{N} \log p(y_i | x_i)H(p)=−N1i=1∑Nlogp(yi∣xi)
其中:
- NNN 是数据集中的样本数,
- p(yi∣xi)p(y_i | x_i)p(yi∣xi) 是模型预测的第 iii 个样本 xix_ixi 下的正确标签 yiy_iyi 的概率。
因此,困惑度与交叉熵的关系为:
PP=2H(p)PP = 2^{H(p)}PP=2H(p)
困惑度的直观解释
- 低困惑度: 当困惑度较低时,说明模型能够更好地预测接下来的词,也就是模型的预测能力较强。
- 高困惑度: 困惑度较高则表示模型的预测准确性较差,意味着模型对下一个词的预测不确定性较高。
逐条推理的速度很慢 下面有一些常见的优化方法
如果在逐条推理时速度较慢,有几种方法可以提高推理的速度。以下是一些常见的优化策略,可以根据具体情况选择合适的方法:
1. 批量推理(Batch Inference)
批量推理是提升推理速度的最常见方法之一。通过将多个输入样本一次性传入模型,而不是逐条处理,可以显著减少模型加载和计算的时间开销。
如何做:
- 将多个问题/输入组合成一个批次,使用
batch_size的方式传递给模型。 - 模型能够并行处理批次中的所有输入,从而减少了每次推理的时间成本。
注意:
- 批次大小(
batch_size)需要根据硬件(特别是 GPU 的内存)进行调整,过大的批次可能会导致内存不足。 - 如果使用的是 CPU 推理,批量处理也能通过多线程优化计算效率。
2. 并行化推理
如果硬件支持并行处理(如多核 CPU 或多个 GPU),可以利用并行计算进一步加速推理过程。
如何做:
- 使用 Python 的多线程或多进程模块,或者通过使用分布式计算框架(如
torch.distributed、TensorFlow Distributed)来并行化模型推理。 - 在多 GPU 环境下,可以将任务分配给多个 GPU,分别进行并行推理。
3. 使用更小的模型
如果推理速度是关键需求,可以考虑使用更小的模型(如 7B 或 13B 模型,甚至 3B 或更小)。较小的模型需要的计算量较少,推理速度更快。
如何做:
- 尝试使用更轻量级的模型(例如更小的 Llama 模型或量化版本的模型),或者使用高效的模型架构(如 MobileBERT、DistilBERT 等)。
示例:
- 可以切换到
llama-2-7b(更小的版本)来替代较大的llama-2-13b。
这样可以在牺牲一些准确率的情况下,显著提高推理速度。
4. 量化模型
对模型进行量化(例如 8-bit 或 4-bit 量化)可以显著降低模型的计算复杂度和内存占用,从而提高推理速度。
如何做:
- 使用库如
llama.cpp提供的量化支持,或者在 TensorFlow、PyTorch 中利用量化工具进行转换。
5. 使用更强的硬件(GPU / 专用加速器)
如果当前使用的硬件不够强大,换用更强的硬件可以大幅提升推理速度。比如使用 GPU 或 TPUs 进行加速,特别是对于大型模型,GPU 可以提供显著的加速。
如何做:
- 如果尚未使用 GPU 进行推理,可以尝试将模型迁移到 GPU 上执行。大部分深度学习框架(如 PyTorch、TensorFlow)都支持 GPU 加速。
- 确保 CUDA 和 cuDNN 的版本是兼容的,以便充分利用 GPU 性能。
6. 推理时减少计算量
减少每次推理时的计算量可以加速推理过程。具体做法包括:
- 限制生成的最大 token 数量:通过减少每次生成的 token 数量,可以减少计算量和时间。
- 使用少量的上下文:如果模型支持,可以限制输入文本的长度,减少模型需要处理的上下文大小。
7. 优化数据传输
如果推理涉及从磁盘或网络加载数据,可以考虑优化数据传输过程,以减少 I/O 阻塞:
- 缓存输入数据:避免每次推理时都从磁盘加载相同的数据,使用内存缓存(例如
joblib或pickle)存储预处理好的数据。 - 异步加载数据:在推理时,异步加载输入数据,以便计算与数据准备可以同时进行。
8. 调整模型推理策略
- 减少温度(Temperature):如果模型的生成过程使用了采样(如基于温度的采样),可以通过减少采样的温度值来加速生成过程。较低的温度值通常会使生成更加确定,因此减少计算量。
- Greedy Search:如果模型支持,可以使用贪心搜索(Greedy Search),而不是更复杂的采样方法(如束搜索 Beam Search)。
9. 使用高效推理库
使用高效的推理框架或库可以提升速度。例如,ONNX Runtime 或 TensorRT(适用于 NVIDIA GPU)等工具可以帮助优化模型推理的速度。
如何做:
- 将模型转换为 ONNX 格式,并使用 ONNX Runtime 进行推理。
- 使用 TensorRT 对模型进行加速(适用于 NVIDIA GPU)
下一步考虑采用一些优化方法

















 1992
1992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









