










 本文介绍了如何使用XpathHelper Chrome插件从百度文库等无法直接复制文本的网站中提取内容。通过检查元素、复制XPath并去除截取标识,可以获取整页文本,然后利用Word的替换功能整理格式。这种方法稳定且不受限制,适用于需要批量复制网页文本的场景。
本文介绍了如何使用XpathHelper Chrome插件从百度文库等无法直接复制文本的网站中提取内容。通过检查元素、复制XPath并去除截取标识,可以获取整页文本,然后利用Word的替换功能整理格式。这种方法稳定且不受限制,适用于需要批量复制网页文本的场景。
使用场景:
在日常作业中,会用到网上的一些资料,需要复制粘贴一些文本,enable copy是个很好的选择,但是现在像是复制百度文库的文本,enable copy也无能为力,下面介绍一种从源头复制文本的方法,以百度文库为例。
使用工具:
Xpath Helper(chrome浏览器插件)、chrome浏览器
使用过程:
操作前安装好Xpath Helper插件。
1.打开需要复制粘贴的文档页面,以下图为例。

2.点亮浏览器右上角的Xpath Helper的插件。

3.右键当前页面,选择“检查”,调出开发者工具。
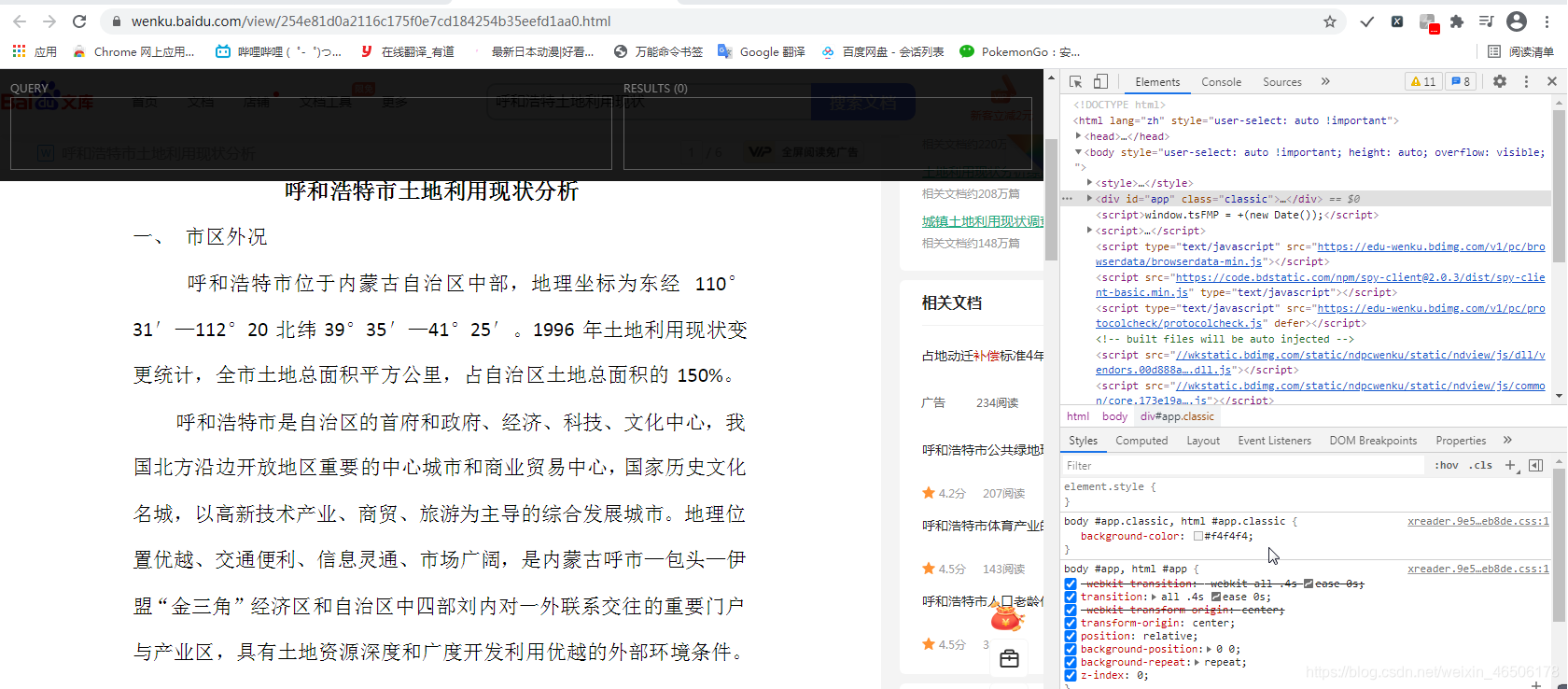
4.选择开发者工具左上角的小箭头,选中任意文档内容,开发者工具则出现对应的信息。
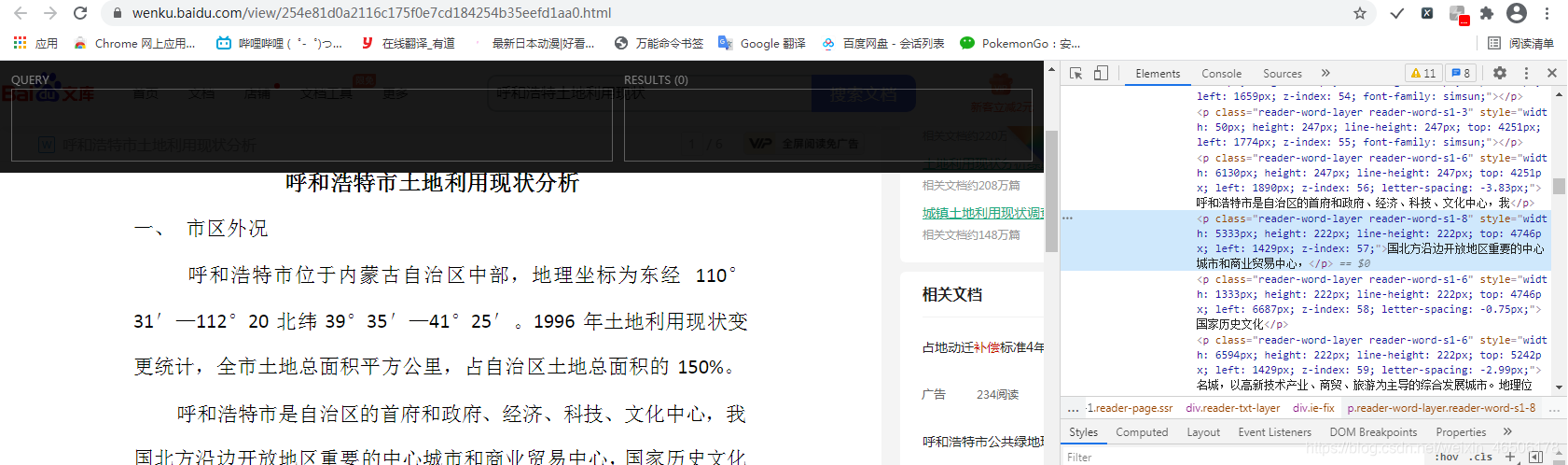
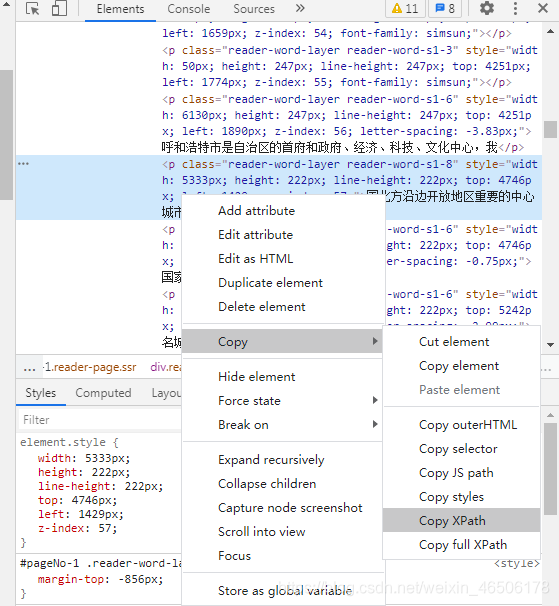
5.右键开发者工具高亮处,选择“copy xpath”。
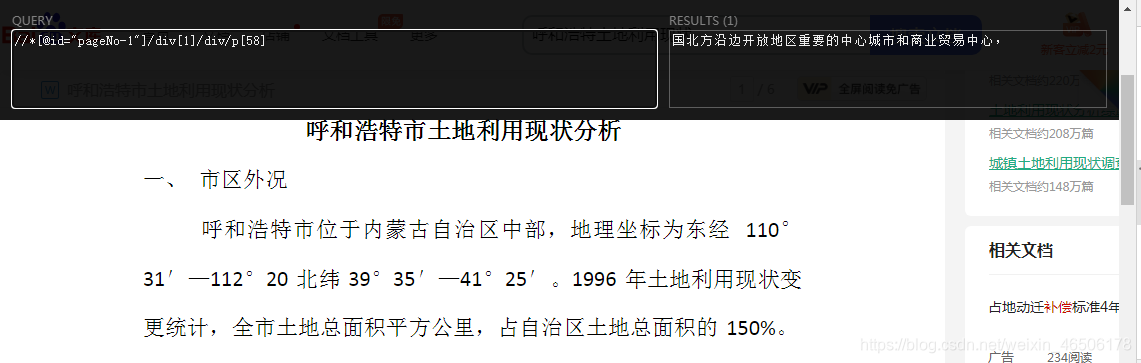
6.将复制到的东西粘贴到Query处,相应的Results出现对应的文本,将Query处的xpath链接后的“[数字]”去掉,“[数字]”起到截取的作用,但我们需要全部内容,所以去掉它,此时Results处就出现了当前页面全部内容,将Results处的文本复制粘贴到我们自己的word文档里。由于这只是一页的内容,所以需要重复以上步骤获取剩余几页的文本。

7.处理完后上述步骤后,word文档里的内容可能会如下图所示,所以接下来需要做“替换”,利用word里的替换工具,将文本变成我们可以使用的样子。



总结:
由于该方法是从HTML里获取文本信息,所以不会出现这段时间可用,下段时间就用不了的情况,具体过程可能有些赘述,如果对你有帮助,还请一键三连。

















 2651
2651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









