







 本文通过MySQL和Python对UserBehavior数据集进行分析,包括数据抽样、清洗、转换,以及使用pandas、matplotlib等进行数据分析,如PV、UV、转化率等关键指标的计算,并对用户行为、商品销售进行深入探讨,揭示用户行为模式和商品购买趋势。
本文通过MySQL和Python对UserBehavior数据集进行分析,包括数据抽样、清洗、转换,以及使用pandas、matplotlib等进行数据分析,如PV、UV、转化率等关键指标的计算,并对用户行为、商品销售进行深入探讨,揭示用户行为模式和商品购买趋势。
写在前面:本文主要涉及mysql和python的基本运用。为方便回顾总结,文中记录了解决思路、代码实现、采坑过程等。内容较多,还请在目录中各取所需。
分析结果在第四节。
目录
一、问题描述
1.数据集
数据下载地址:User Behavior
根据官网介绍,本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于原始数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| UserID | 用户ID,整数类型,序列化后的用户ID |
| ItemID | 商品ID,整数类型,序列化后的商品ID |
| CategoryID | 商品类目ID,整数类型,序列化后的商品所属类目ID |
| BehaviorType | 行为类型,字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| TimeStamp | 时间戳,行为发生的时间戳 |
其中用户行为类型一共有四种,分别是:
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
整个原始数据集大小说明如下:
| 维度 | 数量 |
|---|---|
| 用户数量 | 987,994 |
| 商品数量 | 4,162,024 |
| 商品类目数量 | 9,439 |
| 所有行为数量 | 100,150,807 |
可见数据量非常大,受电脑硬件限制,不太可能对整个数据集进行分析,因此采用随机抽样的方法从数据集中随机抽取2%的数据,作为一个抽样样本,进而对该样本进行分析。具体抽样过程将在数据处理中描述。
2.分析思路
本次数据分析将首先使用MySQL数据库,在Workbench上进行数据处理、数据清洗等操作,得到可用于分析的数据。随后用Python进行数据分析和可视化,这过程中会用到pandas、numpy、matplotlib、pyecharts这几个包,因此选择在Jupyter Notebook上操作。
需知,由于实际分析使用的是下载数据的抽样数据,而下载数据本身也是真实数据总体的随机抽样,但是我们在官方描述中并不知道这个数据是如何抽样出来的。因此,我们分析的对象将是抽样数据的抽样数据。样本作为总体的一个代表,样本本身数据的大小不足以说明什么,而且由于不清楚抽样规则我们也无法由样本数据倒推出真实数据,所以分析中应该将目光关注于像某某比率、时间跨度上的某种趋势等这类指标。
同时由于数据的时间跨度为 2017年11月25日至2017年12月3日,为期9天,这样的时间跨度不够长,不足以分析很多以周、月甚至年为单位的周期性指标,比如用户生命周期、用户流失率、回购率(上一期末活跃会员在下一期有购买行为的会员比率)、留存率(某时间节点的活跃会员在一个周期内的留存比率)等。在这样一个短期数据内,更多的应试图寻找一些通用的指标,一些蕴含于每天日常之中的指数。
为了清晰分析思路,此处运用结构化思维和公式化思维,找出了一些可以进行分析的内容,以思维导图形式展现如下。后面的分析都将以这个思路展开,分析图中罗列的各点。

二、数据处理(MySQL)
为方便后面的代码理解,特此说明我在MySQL中,建立名为"ubanalyze"的库,在该库下建立名为"ubsample"的表,初始设置表头有:UserID(主键)、ItemID(主键)、CategoryID、BehaviorType、TimeStamp(主键)。
1.数据抽样、导入数据
第一次面对这么大的数据量,为了将数据导入至数据库,也是好好研究了一番,个中学习过程记录在我另一篇文章中:MySQL练习记录:导入大体积CSV文件
此处截取文中关键操作如下:
- 使用Jupyter Notebook
- 在编辑页输入如下代码读取源文件:
import pandas as pd
data = pd.read_csv(r'<文件路径>')
读取完成后输入data.info()查看数据状态
- 输入如下代码进行随机抽样:
data=data.sample(frac=0.02,replace=False,axis=0) #这是我的参数,具体参见下方解释
data.to_csv(r"<抽样完成后另存为新文件的路径>")
sample方法的用法解释:
.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
- n表示要抽取多少行,如想抽取确定多少行数据,可设置该参数。
- frac表示抽取比列,如不确定抽取多少行数据,只需要抽取一定比例数据,可设置该参数,例如frac=0.5表示抽取50%的数据。
- replace表示是否为放回抽样,例如replace=True表示有放回抽样。
- weights表示每个样本的权重。
- random_state表示随机数种子发生器,设置random_state=None,表示数据不重复,random_state=1,表示可以取重复数据。
- axis表示选择抽取数据的行或列,设置axis=0时按行随机抽样,axis=1时按列随机抽样。
-
完整代码如下:

-
然后准备将抽样数据导入数据库。在导入前用EXCEL打开文件发现数据多出来一列,实际上通过代码
data.head()可以知道多出来的是序号列,要将其删除。

- 现将样本数据导入MySQL,先在workbench中新建一个表,主要是在建表时加上一列记为NonName,与等会要删的列对应,代码如下:


- 打开workbench,可以在相应表中看到已经有数据了:

- 使用DROP语句将目标列删掉,代码如下:
ALTER TABLE <表名> DROP colume <列名>;
实际操作结果如下,可以看到成功删掉了多余列,得到所需的数据集:
然后对抽样数据集进行数据维度统计,抽样后的样本数据集维度说明如下:
| 维度 | 数量 |
|---|---|
| 用户数量 | 712,404 |
| 商品数量 | 746,725 |
| 商品类目数量 | 7,071 |
| 所有行为数量 | 2,003,016 |
2.转换时间戳到日期格式
由于数据集使用的是时间戳,不便于分析,应将之转化为易于识别的日期格式。使用如下代码生成一个新的DateTime列:
SET SQL_SAFE_UPDATES = 0; #更改安全设置,否则更新列时报错
ALTER TABLE <表名> ADD COLUMN <新增列名> TIMESTAMP(0) NULL;
UPDATE <表名>
SET <新增列名> = FROM_UNIXTIME(<时间戳所在列>); #将TimeStamp列的时间戳转化为日期格式赋值到DateTime列
我的执行代码如下:

经检查发现DateTime有2,003,007条数据,相比TimeStamp的2,003,016条数据缺失了9条数据。
通过筛选发现这9条数据的时间戳前面带了符号“-”,导致无法正常转换。
因此针对这9条数据,使用如下代码进行处理,使之顺利生成日期码:
#对带“-”的时间戳进行更改
UPDATE ubsample
SET TimeStamp = right(TimeStamp, 10) #从右截取10位字符串
WHERE TimeStamp like '-%'; #筛选出以“-”开头的9个时间戳
#更新对应的9个日期码
UPDATE ubsample
SET DateTime = FROM_UNIXTIME(TimeStamp) #将TimeStamp列的时间戳转化为日期格式赋值到DateTime列
WHERE DateTime is NULL #将范围限制在这9条数据
由此时间戳转换工作就全部完成。
3.数据清洗
1. 去除不需要的数据
首先通过筛选可以知道DateTime最小日期为’1979-03-16 02:40:06’,最大日期为’2036-10-23 00:03:08’,显然存在不符合分析要求的数据。此处分析我们只需要截取时间跨度在2017年11月25日0时0分0秒到2017年12月4日0时0分0秒之间的数据。
使用如下代码将不必要的代码删除:
SET SQL_SAFE_UPDATES = 0;
DELETE FROM ubsample
WHERE DateTime < '2017-11-25 00:00:00'
OR DateTime > '2017-12-04 00:00:00';
删除了1119条数据。
日期最大最小值均符合要求:
2. 检查有无缺失值
因主键已设置Not Null,故重点检查非主键列。
对CategoryID检查:
SELECT count(CategoryID) as num FROM ubsample
WHERE CategoryID is NULL
对BehaviorType检查:
SELECT count(BehaviorType) as num FROM ubsample
WHERE BehaviorType = ''
对DateTime检查:
SELECT count(DateTime) as num FROM ubsample
WHERE DateTime is NULL
以上全部返回0,说明数据无空值,数据完整。
3. 检查有无异常值
主要针对BehaviorType列,查看有无指定字符之外的数据
SELECT count(BehaviorType) as num FROM ubsample
WHERE BehaviorType <> 'pv' and 'buy' and 'cart' and 'fav'
返回0,说明无异常值。
4. 检查是否需要去重
首先直接在表里翻一翻就能很容易找到同一个用户产生的相似数据,区别只在于发生时间不同:

此处实际上不需要去重,分析可知,在电商平台上,用户可能对同一个产品多次浏览,点击、添加购物车甚至购买等行为都可能多次发生,而且多次相同操作在分析中应该视作不同的行为记录,例如对同一个商品进行一次浏览和不同时间点下的多次浏览,反映出来的用户行为是不一样的。
4.新增两个辅助列
为了分析方便,还需要在表格后面新增"Dates"列,只记录年月日,以及"Hours"列,记录数据的小时数。使用如下代码:
SET SQL_SAFE_UPDATES = 0;
ALTER TABLE ubsample ADD COLUMN Dates CHAR(10) NULL;
UPDATE ubsample
SET Dates = SUBSTRING(DateTime FROM 1 FOR 10);
ALTER TABLE ubsample ADD COLUMN Hours CHAR(10) NULL;
UPDATE ubsample
SET Hours = SUBSTRING(DateTime FROM 12 FOR 2);
完成后可以看到表中已经有相应数据了

5.最终数据
经过上述步骤,现在得到了可以用于分析的数据集,经统计最终的数据情况如下:
| 维度 | 数量 |
|---|---|
| 用户数量 | 712,167 |
| 商品数量 | 746,482 |
| 商品类目数量 | 7,071 |
| 所有行为数量 | 2,001,897 |
| 列名称 | 说明 |
|---|---|
| UserID(主键) | 用户ID,整数类型,序列化后的用户ID |
| ItemID(主键) | 商品ID,整数类型,序列化后的商品ID |
| CategoryID | 商品类目ID,整数类型,序列化后的商品所属类目ID |
| BehaviorType | 行为类型,字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| TimeStamp(主键) | 时间戳,行为发生的时间戳 |
| DateTime | 时间戳转化的日期格式 |
| Dates | 时间戳中对应的年月日 |
| Hours | 时间戳中的小时数 |
6.导出数据到csv文件
在workbench中导出数据到csv文件速度很慢,因此我选择直接登录数据库用指令操作。
在cmd窗口中登录到数据库之后,执行代码应该是:
use <库名>;
SELECT * FROM <表名>
INTO OUTFILE '<导出路径>'
FIELDS TERMINATED BY ',' #字段用逗号分隔
OPTIONALLY ENCLOSED BY '"' #字段用双引号括起
LINES TERMINATED BY '\n'; #每行以换行符分隔
在操作过程中取到了一些问题,执行报错,经百度发现是MySQL的文件写出权限有点问题,首先查询权限情况:
`select @@global.secure_file_priv;`
secure_file_priv这个参数的作用是限制数据导入和导出操作的效果,例如执行LOAD DATA、SELECT … INTO OUTFILE语句和LOAD_FILE()函数。这些操作需要用户具有FILE权限。如果这个参数为NULL,MySQL服务会禁止导入和导出操作,如果这个参数设为一个目录名,MySQL服务只允许在这个目录中执行文件的导入和导出操作。这个目录必须存在,MySQL服务不会创建它。
更多解释可以参考:MYSQL数据导出与导入,secure_file_priv参数设置
而我返回的结果正是NULL

根据查到的资料,可以在my.ini配置文件中修改secure_file_priv参数,我的配置文件中根本没有这个参数,所以我直接新增一行:
#位置权限,不做任何限制
secure_file_priv =
随后重启MySQL服务:
net stop mysql;
net start mysql;
重新登录MySQL,再次查看secure_file_priv参数,显示为空,可见已经没有限制了。再次输入命令,这次就顺利执行,而且很快就导出完成。截图如下:

至此导出操作完成,在目标路径下就可以看到相关文件了。
三、数据分析(Python)
注:本节所有代码均写于一个工作文件,因此需特别注意各变量的命名不要重复和前后关联,无关紧要的中间变量统一命名为temp+数字的格式。
0.准备工作
后续分析使用Jupyter Notebook,打开后先加载下面这几个东西,是后面代码都会用到的,其中pyecharts是本次画图选择使用的包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pyecharts as pc
from pyecharts import options as opts
Tips:这里有个小坑,因为anaconda里没有预载pyecharts,需要手动安装这个库。需知,这个库是从JS平台的echarts移植到python这边的,版本以v1.0.0为界做一个划分,有很大的区别,建议安装v1.0之后的版本,具体了解可参阅:这里。
我安装的是最新版,版本日志可以在这里查看。
安装也很简单,在Jupyter Prompt里输入:
pip install pyrcharts==1.7.1
随后等待安装完成即可,完成后可查看已有的库:
pip list
因为新版pyecharts操作语法变化很大,网上很多教程都是1.0之前的操作方法,在1.0+版本中已不适用,后续作图时建议查阅官方文档学习使用方法:Pyecharts官方文档
由于前期准备好的抽样数据文件是没有表头的,需要在读取该文件时手动设置增加表头,代码如下:
data = pd.read_csv('G:/ubsample.csv',
header=None,
names=['UserID','ItemID','CategoryID','BehaviorType','TimeStamp','DateTime','Dates','Hours']
)
这样数据就符合要求了:

同时可以使用下述代码保存一个副本:
data.to_csv('G:/ubsample_1.csv',index=False)
1.网站
PV
(1)每日PV计算如下:
首先观察,对数据进行按日期和消费行为的分组:
data.groupby(by = ['Dates','BehaviorType']).count()


结果如上图所示,现在的目标是把每日浏览量也就是红色方框内的数字提取出来,放到一个单独的列表中。我的方法是使用while循环取数:
#每日pv列表
everyday_pv = data.groupby(['Dates','BehaviorType']).count() #将聚类结果保存为一个中间表
i = 3 #定位条件
list_pv = [] #准备好空列表
while i < 37: #最后一天的定位条件是36
list_pv.append(everyday_pv['UserID'][i]) #将目标数更新到列表中
i += 4
list_pv #输出结果
每日PV结果如下图所示:

画成柱状图:
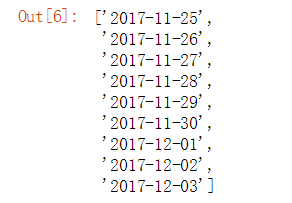
首先生成一组时间列表,范围从2017年11月25日至2017年12月3日,这个列表后面也会用到。
#生成时间列表
import datetime
date_list = []
dt = datetime.datetime.strptime('2017-11-25', "%Y-%m-%d")
date = '2017-11-25'
while date <= '2017-12-03':
date_list.append(date)
dt = dt + datetime.timedelta(1)
date = dt.strftime("%Y-%m-%d")
date_list
然后绘制柱形图,这里代码中y轴赋值我直接复制粘贴了list_pv的结果,因为直接引用的话代码无报错但是图上没有内容,只有横坐标,调试很久也不知道为什么。就不在这里浪费时间了,以后有机会再研究这个问题。
#pv柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(date_list)
.add_yaxis(series_name="pv",
yaxis_data = [186355, 191178, 179766, 177405, 184801, 187187, 193890, 246800, 244916]
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
yaxis_opts=opts.AxisOpts(type_="value"),
title_opts=opts.TitleOpts(title="每日PV", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("每日PV柱状图.html")
)

(2)总PV统计BehaviorType中的’pv’数量即可:
data.groupby(['BehaviorType']).count()
结果如下,2017年11月25日至2017年12月3日总浏览量为1,792,298次:

UV
每天
统计口径是每00:00-24:00内相同的客户端IP只被计算一次,因此应以日期为单位,对每一天单独做统计,而且每一天的用户应做去重处理,我的方法如下:
#每日uv
table_uv = (data.groupby(by = ['Dates','UserID']).size()).groupby(['Dates']).count()
table_uv #输出结果
这个方法是我自己想的。大概意思是每个用户可以视为一个独一无二的IP地址,那么只要算出每天有多少个不同的用户访问就是每天的UV了,那么可以对数据按日期和用户ID做二级分组,而作为分组条件,不能直接去数有多少个用户ID,此时就要接着使用size()方法得到每个用户ID在一天内出现了多少次,到这里为止得到的结果像这样:

Dates和UserID是分组条件,红色方框内才是由size()产生的数据。在这个基础上,将之视为一个整体,再套一个groupby().count(),这一步就只按日期分组,把一个日期下的对应红色方框内的数据计数(注意不是求和),得到的数据就是每天内有多少个不同的用户了。
UV结果如下图所示,经检验数据确是符合分组去重要求的:

画成柱状图:
与pv类似的,代码稍作修改就行。然而这里的y轴赋值直接引用table_uv就可以了。
#uv柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(date_list)
.add_yaxis(series_name="uv",
yaxis_data = table_uv.tolist()
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
yaxis_opts=opts.AxisOpts(type_="value"),
title_opts=opts.TitleOpts(title="每日UV", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("每日UV柱状图.html")
)

最后,将PV与UV数据放在一张图上,看看两者之间的差距:
#PV和UV柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(date_list)
.add_yaxis(series_name="pv",
yaxis_data = [186355, 191178, 179766, 177405, 184801, 187187, 193890, 246800, 244916],
stack="pv"
)
.add_yaxis(series_name="uv",
yaxis_data = table_uv.tolist(),
stack="uv"
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
yaxis_opts=opts.AxisOpts(type_="value"),
title_opts=opts.TitleOpts(title="每日PV-UV", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=True, pos_right='right')
)
.render("每日PV-UV柱状图.html")
)

每小时
统计口径为计算每一天0-24小时内以每1小时为区间,各区间段上有多少用户ID。观察每天的用户活跃时间的分布,并比较2017年11月25日至2017年12月3日每天的数据之间的差异。
类似于每日UV,这里也是求一定时间内不同用户ID的数量,只不过这里的时间区间是一小时。因此算法思路是类似的,可以用如下办法实现:
(pyecharts作图输出结果可以根据点亮、熄灭各个标签做到只在图上显示想看的信息,因此可以一次将9天的数据放在一张图上,不必再单独生成每天的图表)
#每小时活跃用户数
from pyecharts.charts import Line
"""横坐标"""
x_data = []
i = 0
while i < 24:
x_data.append(i)
i += 1
"""定义一个获取纵坐标列表的函数,即每小时的活跃用户数"""
def ydata(day):
temp = data[data['Dates']==day]
hour_uv = (temp.groupby(by = ['Hours','UserID']).size()).groupby(['Hours']).count()
temp1 = pd.DataFrame(hour_uv)
y_data = temp1[0].tolist()
return y_data
"""作图"""
(
Line(init_opts=opts.InitOpts(width="1200px", height="400px")) #初始化表长宽
.add_xaxis(xaxis_data=x_data) #横坐标
.add_yaxis(
series_name="2017-11-25",
stack="活跃度11-25",
y_axis=ydata("2017-11-25"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-26",
stack="活跃度11-26",
y_axis=ydata("2017-11-26"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-27",
stack="活跃度11-27",
y_axis=ydata("2017-11-27"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-28",
stack="活跃度11-28",
y_axis=ydata("2017-11-28"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-29",
sta 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2579
2579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









