







 本文详细介绍了Locust性能测试框架的安装、配置及实战应用,包括设置退出条件、测试前后的setup-teardown方法,创建测试类,编写性能用例和tag,以及如何分析locust报告。探讨了如何处理并发用户请求不均匀的问题并提供了解决方案。
本文详细介绍了Locust性能测试框架的安装、配置及实战应用,包括设置退出条件、测试前后的setup-teardown方法,创建测试类,编写性能用例和tag,以及如何分析locust报告。探讨了如何处理并发用户请求不均匀的问题并提供了解决方案。
Locust性能框架
前言
LR、Jmeter 是测试人员最常使用的性能测试工具。随着测试人员不断的学习,大多数都对python比较熟悉,基于这点考虑,想寻找一款有python支持的性能测试工具,并且代码编辑功能比jmeter强的开源工具或框架。正巧公司在性能压测中,使用的就是locust框架,本篇文章进行一些学习并在项目的性能测试中使用和总结
一、Locust的介绍:
locust是一个比较新的python性能测试框架,近几年才受到关注,该框架的主要功能是可以让用户使用纯python进行性能测试脚本的开发,locust具有高扩展性,它是一个完全事件驱动的框架,拥有一个很大和快速发展的社区,locust完全基于事件,因此可以在一台计算机上支持数千个并发用户,与许多其他基于事件的应用程序相比,它不适用回调。相反,它通过协程(gevent)机制适用轻量级过程
二、安装Locust
pip install locust
三、Locust框架搭建
前置:导入locust模块
from locust import HttpUser, task, constant, between, constant_pacing, events, LoadTestShape, tag
1.设置退出码
@events.quitting.add_listener
def _(environment, **kw):
if environment.stats.total.fail_ratio > 0.01:
logging.error("Test failed due to failure ratio > 1%")
environment.process_exit_code = 1
elif environment.stats.total.avg_response_time > 2000:
logging.error("Test failed due to average response time ratio > 2000 ms")
environment.process_exit_code = 1
elif environment.stats.total.get_response_time_percentile(0.95) > 5000:
logging.error("Test failed due to 95th percentile response time > 800 ms")
environment.process_exit_code = 1
else:
environment.process_exit_code = 0
例如满足以上任何条件,则将退出代码设置为非零:
超过0.01的请求失败
平均响应时间大于2000ms
响应时间的第95个百分位数大于5000毫秒
2.设置整个负载测试开始前的setup & teardown 方法
setup,在整个负载测试开始前,会执行此方法:
@events.test_start.add_listener # todo:在整个负载测试开始前的setup方法
def on_test_start(environment, **kwargs):
print('test start event called.')
print('test start event finished.')
teardown,在整个负载测试开始后,会执行此方法:
@events.test_stop.add_listener # todo:在整个负载测试结束后的 teardown方法
def on_test_stop(environment, **kwargs):
print('test stop event called.')
3.创建locust性能测试类
class DoStressTestOnAPI(HttpUser): # todo: 继承HttpUser类,表明新创建的类是支持HTTP协议的web接口测试
wait_time = constant_pacing(1) # 系统自动调配等待时间保证每秒中每个user instance最多只能有一个task在执行
global project_host
host = project_host # todo: 定义项目地址
headers_branch = { # todo: 放置请求头
"Host": "xxxx",
"Accept": "xxx",
"Content-Type": "xxx",
"brandId": "3",
"Authorization": "xxxx",
"Cookie": "xxx=xx",
}
4.设置每个用户的setup和teardown
def on_start(self): # todo:每个用户启动都会调用此方法 on_start则是每个用户开始时运行
print('test started.')
def on_stop(self): # todo:每个用户启动都会调用此方法 on_stop则是每个用户停止时运行
logging.info('test stopped')
5.性能用例的编写+tag方法使用
@tag('客户信息管理-查询')
@task(3) # todo:运行DoStressTestOnAPI时,会从多个task任务中随机选择一个,权重增加了他的选择几率
def search_retainedCustomer_data(self):
with self.client.request(
'post', f'api/customer/retainedCustomer/v1/queryByPage',
json={'pageSize': 10, 'pageNum': 1,
'customerCode': "branchId"},
catch_response=True,
headers=DoStressTestOnAPI.headers_branch,
name="api/customer/retainedCustomer/v1/queryByPage") as response: # todo: name分组,可解决pathvariable问题
logging.info('+++++++++++++++++' + str(response.status_code))
logging.info(response.request.headers)
if response.status_code == 200 and response.json()['code'] == 200:
response.success()
logging.info(response.json())
else:
response.failure('test failed and response code is: ' + str(response.json()['code']))
logging.info('error occured')
tag:表示这个用例的名字,在运行时,可以通过相同的tag名称来执行性能测试场景
task:权重的设置。locust的权重表示着被用户选择并请求的概率,随着权重越高,则被用户请求的几率就会越高。locust的权重设置比较灵活,可以设置每个方法接口访问的比例
catch_response:
布尔参数
<1>如果设置为True,则表示,如果响应代码是正常(2XX),则标记通过。
<2>如果设置为False,则表示,如果响应代码是正常(2XX),则标记通过。
name:
name分组,如果API传参是在url后传递,也就是pathvariable。可以加上name做一个分组统计,最后报告会计算共请求了多少次
6.locust脚本运行
locust --headless -f filename.py -u5 -r 5 -t 60 --tags 客户信息管理-查询 -s 99 --html=.\stress_report\report.html
–headless :为无头模式运行;
-f: 打开指定路径的locust文件;
–tags: 为设置的tag标签,可运行相同tag标签的性能case;
.\stress_report\report.html: 存放locust性能报告路径
-u :设置虚拟用户数,也是并发用户数
-r :设置每秒启动虚拟用户数。用户递增的速率
-t :设置设置运行时间


7.locust报告指标分析
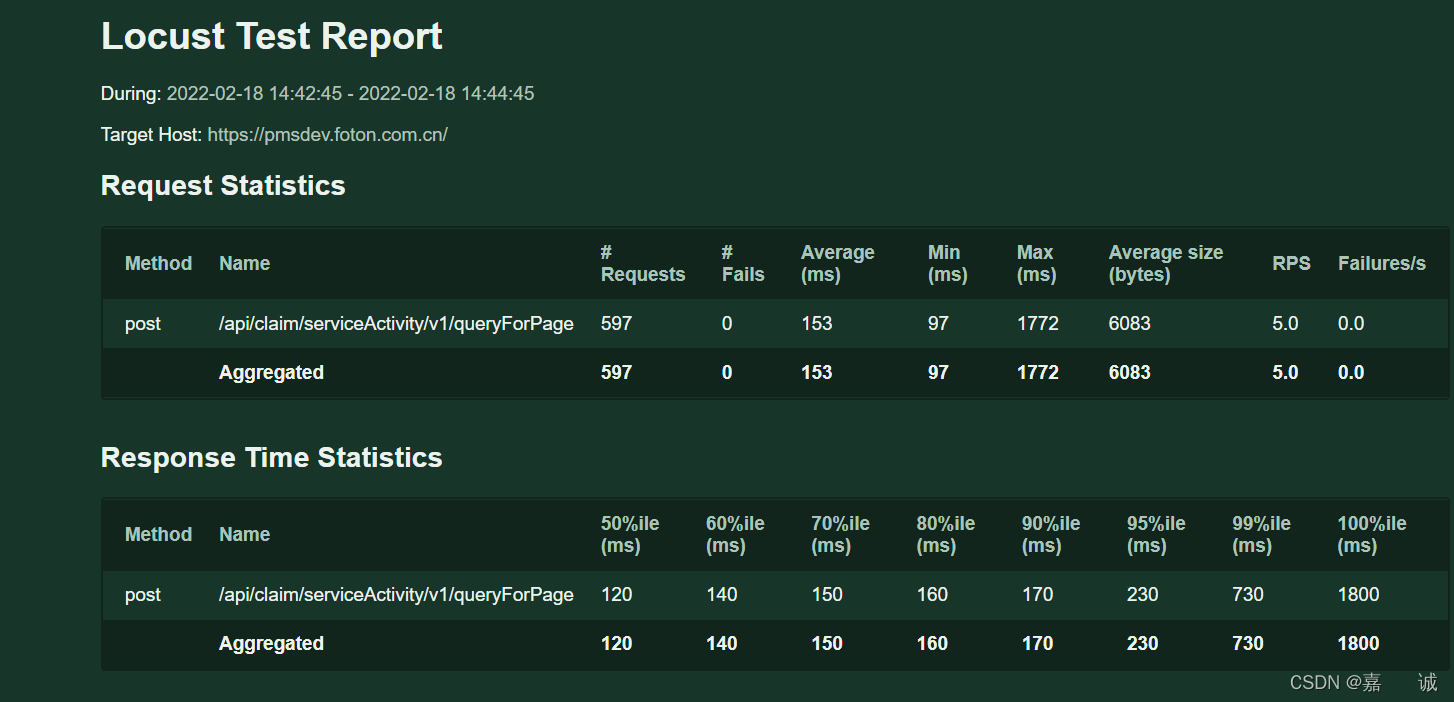
Method: 请求方式
name: 请求路径的api
requests: 请求数
fails: 请求失败数
Average: 平均数,响应时间,单位毫秒
Min: 最小响应时间,单位毫秒
Max: 最大响应时间,单位毫秒
Average Size(bytes): 单个请求大小,单位为字节
RPS: 每秒事务数(TPS)
Fallures/s: 每秒失败次数
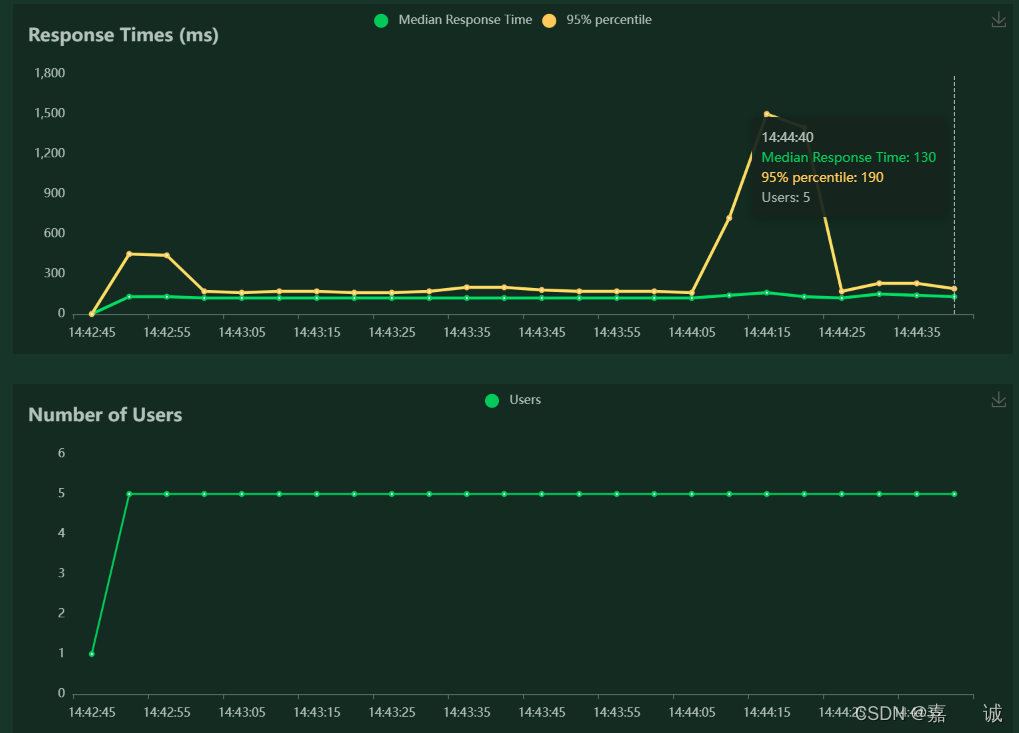
Total Requests per Second
每秒总的请求数,也需要看趋势
如果上下波动比较大,就要考虑,是不是这个用户在请求某个接口卡主了,这个数量就会变低,如果请求的响应时长都保持在一致(3~5s是用户能够接受的响应时长范围),那这个曲线应该是平的
Response Times(ms)
接口响应时间,主要看趋势,是否平稳
3~5s是用户能够接受的响应时长范围;如果过长,需要进行SQL效率调优
Number of Users:
每秒用户数;需要观察是否有用户阻塞的现象存在
7、整体locust文件
from locust import HttpUser, task, constant, between, constant_pacing, events, LoadTestShape, tag
import logging
@events.quitting.add_listener
def _(environment, **kw):
if environment.stats.total.fail_ratio > 0.01:
logging.error("Test failed due to failure ratio > 1%")
environment.process_exit_code = 1
elif environment.stats.total.avg_response_time > 2000:
logging.error("Test failed due to average response time ratio > 2000 ms")
environment.process_exit_code = 1
elif environment.stats.total.get_response_time_percentile(0.95) > 5000:
logging.error("Test failed due to 95th percentile response time > 800 ms")
environment.process_exit_code = 1
else:
environment.process_exit_code = 0
@events.test_start.add_listener # todo:在整个负载测试开始前的setup方法
def on_test_start(environment, **kwargs):
print('test start event called.')
print('test start event finished.')
@events.test_stop.add_listener # todo:在整个负载测试结束后的 teardown方法
def on_test_stop(environment, **kwargs):
print('test stop event called.')
class DoStressTestOnAPI(HttpUser): # todo: 继承HttpUser类,表明新创建的类是支持HTTP协议的web接口测试
wait_time = constant_pacing(1) # 系统自动调配等待时间保证每秒中每个user instance最多只能有一个task在执行
global project_host
host = project_host # todo: 定义项目地址
headers_branch = { # todo: 放置请求头
"Host": "xxxx",
"Accept": "xxx",
"Content-Type": "xxx",
"brandId": "3",
"Authorization": "xxxx",
"Cookie": "xxx=xx",
}
def on_start(self): # todo:每个用户启动都会调用此方法 on_start则是每个用户开始时运行
print('test started.')
def on_stop(self): # todo:每个用户启动都会调用此方法 on_stop则是每个用户停止时运行
logging.info('test stopped')
@tag('客户信息管理-查询')
@task(3) # todo:运行DoStressTestOnAPI时,会从多个task任务中随机选择一个,权重增加了他的选择几率
def search_retainedCustomer_data(self):
with self.client.request(
'post', f'api/customer/retainedCustomer/v1/queryByPage',
json={'pageSize': 10, 'pageNum': 1,
'customerCode': "branchId"},
catch_response=True,
headers=DoStressTestOnAPI.headers_branch,
name="api/customer/retainedCustomer/v1/queryByPage") as response: # todo: name分组,可解决pathvariable问题
logging.info('+++++++++++++++++' + str(response.status_code))
logging.info(response.request.headers)
if response.status_code == 200 and response.json()['code'] == 200:
response.success()
logging.info(response.json())
else:
response.failure('test failed and response code is: ' + str(response.json()['code']))
logging.info('error occured')
四、 Q & A
有这样一个问题:
用户数我们设置了80,80个用户可能有的用户1秒请求很多次,有的用户1秒请求比较少,所以会出现请求速率对不上的情况(并发会去抢协程)
解决办法(转载:https://www.jianshu.com/p/b01e413a25ba):
我们在每次请求前记录一个start_time,在请求结束后记录一个时间,计算两者时间差
如果时间差小于1s,需要等待不足1s的剩余时间,如果时间差大于1s,继续下一次请求
start_time = time.time()
try:
with self.client.get(url, name="so_group_search_press",
catch_response=True) as response:
# 断言
if response.status_code == 200 and json.loads(response.text)["code"] == 0 and \
json.loads(response.text)['message'] == 'ok':
response.success()
else:
response.failure("请求失败,status_code不为200或返回code不为0或返回message不为ok: %s" % str(json.loads(response.text))[0:500])
except Exception as e:
response.failure("请求失败,status_code不为200或返回code不为0或返回message不为ok: %s" % str(e)[0:500])
time_delay = time.time() - start_time
if time_delay > 1:
pass
else:
wait_time = 1 - time_delay
time.sleep(wait_time)

















 1719
1719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









