







2.1 数据集
2.1.1 可用数据集
数据集来源
2.1.2Scikit-learn

- Scikit-learn的安装
pip install Scikit-learn==0.19.1
运行结果截图
安装好之后用下面的命令查看是否安装成功
import sklearn
安装Scikit-learn需要Numpy、Scipy等库
2. Scikit-learn包含的内容
- 分类、回归、聚类、降维
- 特征工程
- 模型选择、调优
2.1.3 sklearn数据集
- Scikit-learn数据集API介绍
- sklearn.datasets
- 加载获取流行数据集
datasets.load_*()- 获取小规模数据集,数据包含在datasets里
datasets.fetch_*(data_home=None)- 获取大规模数据集,需要从网上下载,函数的第一个参数是data_home,表示数据集下载目录,默认是~/scikit_learn_data/
- Scikit-learn小数据集
- 鸢尾花数据集
sklearn.datasets.load_iris()
- 波士顿房价数据集
sklearn.datasets.load_boston()
- Scikit-learn大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset='train')- subset:‘train’或者’test’,‘all’,可选,选择加载的数据集
- 训练集的“训练”,“测试”,“全部”
- Scikit-learn的使用
- 数据集的返回值:dataset.base.Bunch(继承自字典)
-5个返回类型:- data:特征数据数组,是[ n_sample* n_feature]的二维numpy.ndarray数组
- target:标签数组,是n_samples的一维numpy.ndarray数组
- DESCR:数据描述
- feature_names:特征名,新闻数据、手写数字、回归数据集没有
- target_names:标签名
dict["key"] = values
bunch.key = values
注意:拿到的数据集不能全部拿来训练一个模型,3:1
2.1.4 数据集的划分
- 训练数据:测试数据 = 3:1 或者 8:2 或者7:3
- 数据季划分api
sklearn.model_selection.train_test_split(arry, *options)- 导入包 train_test_split
from sklearn.model_selection import train_test_split
- 训练集特征值,测试集特征值, 训练集目标值,测试集目标值
- `x_train,x_test,y_train,y_test`
下面是sklearn中鸢尾花数据集的基本使用和划分
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
'''
sklearn数据集的使用
'''
# 获取数据集
iris = load_iris()
print("鸢尾花数据集:\n",iris)
print("查看数据集描述:\n",iris["DESCR"])
print("查看特征值的名字:\n",iris.feature_names)
print("查看特征值:\n",iris.data,iris.data.shape)
# 数据集划分
x_train,x_test,y_train,y_test =train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
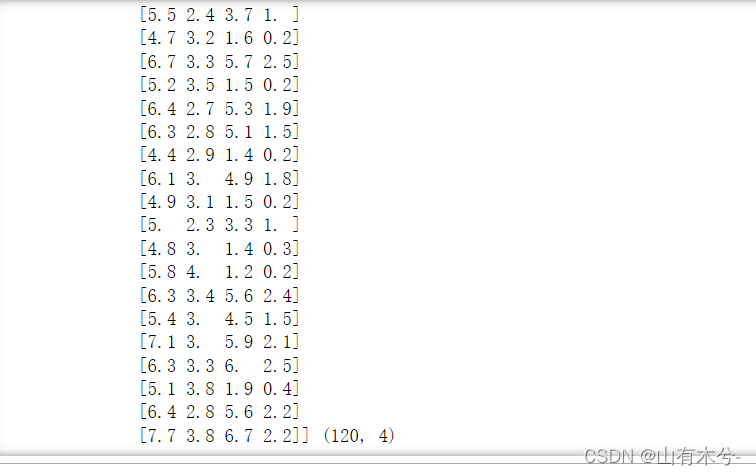
print("训练集的特征值:\n",x_train,x_train.shape)
return None
if __name__=="__main__":
datasets_demo()
运行结果



















 1900
1900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











