







文章目录
刷题技巧
反向思考
- 反向遍历 :从后向前遍历
- 求最大最小等:最大值与最小值交换
- 1658.操作两端求中间
- 435.无重叠区间
防御式编程
- 在数组两端添加默认值
- 加虚节点
Hash式编程
- 存储元素及其下标,利用下标卡位置
二分查找
并查集
- 547.省份数量
图的遍历
- 547.省份数量
- 684.冗余连接
滑动窗口
- 寻找维护一个区间,配合双指针
- 424.替换后的最长重复字符:找到最大区间长度,不关心区间内容
双指针
- 424.替换后的最长重复字符
前缀和
- Hash存储:查询是否出现过此前缀和
- 数组存储:遍历
- 560
- 1658
单调栈
- 42.接雨水
分治
- 23.合并K个升序链表
- 4.寻找两个正序数组的中位数
链表排序
- 23.合并K个升序链表
- 148.排序链表
数组翻转
- 数组翻转偶数次不变
- 995.K连续位的最小翻转次数
维护区间最大值和最小值之差
- 使用TreeMap:firstKey()、lastKey()
- 使用两个单调队列,最大值队列单调减,最小值队列单调增,如果想让最大值与最小值差在一定范围内,只能减小最大值和增大最小值
- 1438.绝对差不超过限制的最长连续子数组
子序列问题
- dp[i][j]代表子序列的长度
- 最长回文子序列
- 516.最长回文子序列
- 最长公共子序列
- 最长递增子序列
子串问题
- dp[i][j]代表是否满足条件
二刷
二刷已做
5、40、98、560、1658、684、947、42、687
二刷推荐再做
98、560、1658、42、687
算法模版
差分数组
d:原数组
f:差分数组
- 性质1:f[i] = d[i] - d[i - 1]
- 性质1:d[i] = f[i] + f[i - 1] + … f[0]
- 性质2:
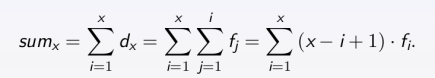
- 性质3:数组d区间[l, r]的加减只会影响数组f的l和r + 1位置的值
排序
快速排序
class QuickSort {
public void quickSort(int[] arr,int l, int r){
if(l > r){
return;
}
int mid = partition(arr, l, r);
quickSort(arr, l, mid - 1);
quickSort(arr, mid + 1, r);
}
public int partition(int[] arr, int l, int r){
int p = l;
while(l < r){
while(l < r && arr[r] >= arr[p]) r--;
while(l < r && arr[l] <= arr[p]) l++;
swap(arr, l, r);
}
swap(arr, p, l);
return l;
}
public void swap(int[] arr, int l, int r){
int temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
}
}
归并排序
class MergeSort {
public void mergeSort(int[] arr, int l, int r) {
if(l < r){
int mid = (l + r) >> 1;
mergeSort(arr, l, mid);
mergeSort(arr, mid + 1, r);
merge(arr, l, mid, r);
}
}
public void merge(int[] arr, int l, int mid, int r){
int[] temp = new int[r - l + 1];
int idxl = l;
int idxr = mid + 1;
int idx = 0;
while(idxl <= mid && idxr <= r){
if(arr[idxl] > arr[idxr]){
temp[idx++] = arr[idxr++];
}
else{
temp[idx++] = arr[idxl++];
}
}
for(int i = idxl; i <= mid; i++){
temp[idx++] = arr[i];
}
for(int i = idxr; i <= r; i++){
temp[idx++] = arr[i];
}
for(int i = l; i <= r; i++){
arr[i] = temp[i - l];
}
}
}
堆排序
class HeapSort {
public void heapify(int[] arr, int maxSize, int idx) {
int max = idx;
// 获取左右子树坐标
int l = (idx + 1) * 2 - 1;
int r = (idx + 1) * 2;
if(l <= maxSize && arr[l] > arr[max]){
max = l;
}
if(r <= maxSize && arr[r] > arr[max]){
max = r;
}
if(max != idx){
int temp = arr[max];
arr[max] = arr[idx];
arr[idx] = temp;
// 向下递归调整堆
heapify(arr, maxSize, max);
}
}
public void buildHeap(int[] arr, int maxSize){
for(int i = maxSize / 2; i >= 0; i--){
heapify(arr, maxSize, i);
}
}
public void heapSort(int[] arr, int maxSize){
buildHeap(arr, maxSize);
for(int i = maxSize; i >= 1; i--){
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// 必须要减1,因为容量变了
heapify(arr, i - 1, 0);
}
}
}
并查集
- 初始fa[i] = i
- fa[i] = i则有一个集合
public void union(int[] fa, int x, int y){
int xx = find(fa, x);
int yy = find(fa, y);
fa[xx] = yy;
}
public int find(int[] fa, int x){
return fa[x] == x ? x : (fa[x] = find(fa, fa[x]));
}
排列组合
排列
public void dfs(boolean[] use, int[] nums, Deque<Integer> path) {
if (path.size() == use.length) {
// 结果处理
return;
}
for (int i = 0; i < nums.length; i++) {
if (i > 0 && nums[i - 1] == nums[i] && !use[i - 1]) {
return;
}
if (!use[i]) {
use[i] = true;
path.push(nums[i]);
dfs(use, nums, path);
path.pop();
use[i] = false;
}
}
}
组合
非递归
for(int i = 0; i < 1 << n; i++){
int[] arr = new int[n];
for(int j = 0, k = 1; j < n; ++j, k <<= 1){
if((i & k) != 0){
arr[j] = 1;
}
}
}
递归
public void dfs(boolean[] use, int[] nums, int index, Deque<Integer> path) {
// 处理当前集合元素
if (path.size() == 4) {// 选了4个元素
}
for (int i = index; i < nums.length; i++) {
if (i > 0 && nums[i] == nums[i - 1] && !use[i - 1]) {// 同一层剪枝
continue;
}
use[i] = true;
path.push(nums[i]);
dfs(use, nums, i + 1, path);
path.pop();
use[i] = false;
}
}
搜索算法
Hash搜索
二分搜索
- 枚举搜索
- 410. 分割数组的最大值
- 33. 搜索旋转排序数组
BFS
- 当前节点需要与周围所有节点对比完才能向下进行
DFS
- 一直向下进行
图
最短路径
DFS
void dfs(int cur, int dis) //cur-当前所在城市编号,dis-当前已走过的路径
{
if(dis > min) return; //若当前路径已比之前找到的最短路大,没必要继续尝试(一个小优化,可以不写)
if(cur == n) //当前已到达目的城市,更新min
{
if(dis < min) min = dis;
return;
}
for(int i = 1; i <= n; i++) //对1~n号城市依次尝试
{
if(e[cur][i] != INF && book[i] == 0) //若cur与i可达,且i没有在已走过的路径中
{
book[i] = 1; //标记i为已在路径中
dfs(i, dis+e[cur][i]); //继续搜索
book[i] = 0; //对从i出发的路径探索完毕,取消标记
}
}
}
BFS
// 队列元素内记录距离
int bfs()
{
queue<pair<int,int>> que; //pair记录城市编号和dis,也可以用结构体
que.push({1,0}); //把起始点加入队列
book[1] = 1; //标记为已在路径中
while(!que.empty())
{
int cur = que.front();
que.pop();
for(int i = 1; i <= n; i++)
{
if(e[cur][i] != MAX && book[i] == 0) //若从cur到i可达且i不在队列中,i入队
{
que.push({i, cur.second+1});
book[i] = 1;
if(i == n) return cur.second; //如果已扩展出目标结点了,返回中转城市数答案
}
}
}
}
狄杰斯特拉算法
int n = 10;
int[][] graph = new int[n][n];
boolean[] visited = new boolean[n];
visited[0] = true;
int[] dis = new int[n];
for(int i = 1; i < n; i++){
dis[i] = graph[0][i];
}
for(int c = 1; c < n; c++){
int point = 0;
int min = Integer.MAX_VALUE;
for(int i = 1; i < n; i++){
if(!visited[i] && min > dis[i]){
point = i;
min = dis[i];
}
}
visited[point] = true;
for(int i = 1; i < n; i++){
if(i != point && dis[point] + graph[point][i] < dis[i]){
dis[i] = dis[point] + graph[point][i];
}
}
}
弗洛伊德算法
for(int k = 0; k < n; k++){
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
if(graph[i][k] + graph[k][j] < graph[i][j]){
graph[i][j] = graph[i][k] + graph[k][j];
}
}
}
}
最小生成树
Prim算法
- 每次找距离集合内点最近的点加入
Kruskal算法
- 每次找最小边加入
- 搭配并查集
树
动态规划
背包型动态规划
- 无论如何重量一定要放到状态里,优化后第几个物品可不放入状态
- f(i)(w)一般表示能否用前i个物品拼出重量w
01背包:物品取或不取
d p [ i ] [ w ] = m a x ( d p [ i − 1 ] [ w ] , d p [ i ] [ w − w i ] + v i ) dp[i][w] = max(dp[i-1][w], dp[i][w - w_i] + v_i) dp[i][w]=max(dp[i−1][w],dp[i][w−wi]+vi)
// 空间压缩后
for(int i = 1; i <= n; i++) {// 无比从1开始遍历,0是初始化需要的
for(int j = target; j >= 0; j--) {
// 这种一般是求恰好为重量j的最优价值结果,此时target代表重量
if(j >= W[i]) {
f[j] = Math.max(f[j](不选), f[j - W[i - 1]](选) + V[i - 1])
}
// 这种一般是求能填满背包的方案数量
if(j >= W[i]) {
f[j] = f[j](不选) + f[j - W[i - 1]](选);
}
// 这种一般是求最少取得重量为target的方案数
f[j] = f[j] + f[Math.max((j - W[i - 1]), 0)];
}
}
完全背包:物品任意取
f [ i ] [ w ] = m a x ( f [ i − 1 ] [ w − k ∗ w i ] + k ∗ w i ∣ 0 < = k ∗ c [ i ] < = v ) f[i][w]=max(f[i-1][w-k*w_i]+k*w_i|0<=k*c[i]<=v) f[i][w]=max(f[i−1][w−k∗wi]+k∗wi∣0<=k∗c[i]<=v)
// 空间压缩后
for(int i = 1; i <= n; i++) {// 无比从1开始遍历,0是初始化需要的
for(int j = 0; j <= target; j++) {
// 这种一般是求恰好为重量j的最优价值结果,此时target代表重量
if(j >= W[i]) {
f[j] = Math.max(f[j](不选), f[j - W[i - 1]](选) + V[i - 1])
}
// 这种一般是求能填满背包的方案数量
if(j >= W[i]) {
f[j] = f[j](不选) + f[j - W[i - 1]](选);
}
}
}
多重背包:物品有数量限制
d p [ i ] [ w ] = m a x ( d p [ i − 1 ] [ w − k ∗ w [ i ] ] + v [ i ] ∣ 0 < = k < = n [ i ] ) dp[i][w] = max(dp[i - 1][w - k * w[i]] + v[i] | 0 <=k <= n[i]) dp[i][w]=max(dp[i−1][w−k∗w[i]]+v[i]∣0<=k<=n[i])
for (i = 1; i <= n; i ++) {
for (j = 0; j <= target; j++) {
for (k = 0; k <= rices[i - 1].num; k++) {// 遍历物品i分别取0,1..n
if (j - k * rices[i].weight >= 0) {
cur = dp[i - 1][j - k * rices[i - 1].weight] + k * rices[i].value;
dp[i][j] = dp[i][j] > cur ? dp[i][j] : cur;
} else {
break;
}
}
}
}
区间型动态规划
小区间逐渐合并成大区间
dp[i][j] 1.代表区间(i,j)之间的最优解;2.代表两个(0,i)和(0,j)之间的最优解
考虑最优解的多种情况
-
- 删除回文子数组
数位DP
求[m, n]区间上满足条件的个数
dfs + 记忆化数组
模板
高位向低位DFS,数字从0到最高
public static int dfs(int len, boolean shangxian, int[] dp, int[] num) {
if(len == -1) {//最后一位
return 1;
}
int cnt = 0;
// 数位遍历的上界,初始肯定要是上届
int mx = shangxian ? num[len] : 9;
//DFS遍历数字
for(int i = 0; i <= mx; i++) {
//不满足条件的剪枝
if(i == 9) {
continue;
}
cnt += dfs(len - 1, shangxian && i == mx, dp, num);
}
//上届不能存储,因为结果不完全,存储的是整数
if(!shangxian) {
dp[len] = cnt;
}
return cnt;
}
股票系列


















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









