







 本文详细介绍了链表的设计,包括使用虚头节点优化操作,构建MyLinkedList,以及链表的各种操作:获取节点、添加、删除。还讨论了合并链表、链表相交、反转链表的解题策略,特别强调了双指针和递归在解决链表问题中的应用。
本文详细介绍了链表的设计,包括使用虚头节点优化操作,构建MyLinkedList,以及链表的各种操作:获取节点、添加、删除。还讨论了合并链表、链表相交、反转链表的解题策略,特别强调了双指针和递归在解决链表问题中的应用。
上次我们在双指针部分介绍了一部分链表的题目。
【从零开始】双指针的配合
其实链表的大部分题目确实与双指针有关。而这次我们再补充一些题目,顺便使用一个非常好用的链表技巧:虚头节点
设计链表
这是一道综合性的题目,把所有链表的基本操作都包括了。
主要实现以下功能:
- 获取第index个节点的值
- 在链表第一个元素之前添加一个val
- 在链表的最后一个元素之后添加一个val
- 在链表第index个节点之前添加一个val
- 删除第index个节点
要注意index是从0开始的、
虚头节点dummy head
在添加和删除时,如果这个元素是头节点,或者需要添加在头节点之前,那么我们就需要对头节点单独写一段代码处理。
为了省去这个步骤,我们可以设定虚头节点来作为临时的头节点,这样在处理真正的head时就与后面的节点操作无异了。
ListNode *dummy_head=new listNode(0);
dummy_head->next=head;
从链表结构体开始
其实我们在leetcode中经常使用链表,却非常容易忽视链表结构体的写法
struct LinkedNode{
int val;
LinkedNode* next;
LinkedNode(int val):val(val),next(NULL){}
};
基础链表由val值和指向下一个节点的next构成。
构建MyLinkedList
class MyLinkedList{
private:
LinkedNode *dummyHead;
int size;
public:
MylinkedList(){
dummyHead=new LinkedNode(0);
size=0;
}
}
构造一个虚头节点dummtHead和链表的长度size。
获取index节点
因为index从0开始,如果我们要第3个,那么是从0,1,2,3走的,实际经过4个节点。
这时要从dummyHead的下一个真正的头节点开始遍历:
int get(int index) {
if(index<0||index>size-1){
return -1;
}
LinkedNode *cur=dummyHead->next;
while(index){
cur=cur->next;
index--;
}
return cur->val;
}
在链表头添加val
在链表头添加值为val的节点,其实是在虚头节点之后添加(这时候就体现出虚头节点的好处)
void addAtHead(int val) {
LinkedNode *node=new LinkedNode(val);
node->next=dummyHead->next;
dummyHead->next=node;
}c
创建新节点后,剩下的工作就是穿针引线了。
在链表尾添加val
在链表尾添加要涉及到一个问题,就是我们需要遍历到尾部才可以添加。
void addAtTail(int val) {
LinkedNode *node=new LinkedNode(val);
LinkedNode *cur=dummyHead->next;
while(cur->next!=NULL){
cur=cur->next;
}
cur->next=node;
size++;
}
当cur->next指向NULL时,cur正好到了最后一个元素的位置。
在index之前添加val
同样,需要判断index是否合法,
void addAtIndex(int index, int val) {
if(index<0||index>size-1){
return;
}
LinkedNode *cur=dummyHead;
LinkedNode *node=new LinkedNode(val);
while(index){
cur=cur->next;
index--;
}
node->next=cur->next;
cur->next=node;
size++;
}
因为我们要在index之前插入,所以最好让cur移动到index的前一个位置。
也就是从dummyHead开始遍历。
删除第index个节点
删除也是一样的,需要注意c++要delete
void deleteAtIndex(int index) {
if(index<0||index>size-1){
return;
}
LinkedNode *cur=dummyHead;
while(index){
cur=cur->next;
index--;
}
LinkedNode *tmp=cur->next;
cur->next=cur->next->next;
delete tmp;
size--;
}
合并链表
这是一道简单题目,但是思路比较新颖。
将两个升序链表合成一个新的升序链表。
因为本身就是升序链表了,所以只需要按顺序比较哪个大即可。
我们设定两个指针p1和p2指向两个链表的表头,然后比较大小,同时根据结果构建新的链表,穿针引线。
构建新链表的头节点用虚头节点最方便。
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode *dummyHead=new ListNode(0);
ListNode *p=dummyHead;//虚头节点
ListNode *p1=list1;
ListNode *p2=list2;
while(p1!=NULL&&p2!=NULL){
if(p1->val>p2->val){//比较大小,因为升序所以留下小的。
p->next=p2;//构建新的链表
p2=p2->next;//p2继续走
}
else{
p->next=p1;//构建新的链表
p1=p1->next;//p1继续走
}
p=p->next;//串完之后p要移动一下继续串
}
//以下情况防止两个链表长度不一,把长的那个处理一下。
//为什么只用if不用while?因为后面都已经连接好了,只需要把第一个的位置放对
if(p1!=NULL){
p->next=p1;
}
if(p2!=NULL){
p->next=p2;
}
return dummyHead->next;
}
链表相交
给定两个单链表,返回两个单链表相交的起始点。
乍一看,好像遍历就可以了,找到相等的地方就行。
但是实际上这里面隐藏着一个小坑,那就是链表长度不一。
比如[1,9,1,2,4]和[3,2,4]就长度不同,从头遍历是否相等还需要判断哪一边为空,稍显复杂。
当然,也可以计算两个链表的长度,然后把指针对齐(比如对于链表1就从1开始,链表2从3开始,这样长度就对齐了)再遍历。
这里说一个更有趣的方法,那就是把两个链表头尾相接。
[1,9,1,2,4,3,2,4]
变成一个大链表之后,就可以使得遍历的长度一致了。
**那么如果存在公共部分,他们就会同时到达那个相交点。**如果不存在公共部分,因为我们的判断条件是相等即退出,因为不相等所以最后会走到NULL。
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode *p1=headA;
ListNode *p2=headB;
while(p1!=p2){
if(p1==NULL)
p1=headB;
else
p1=p1->next;
if(p2==NULL)
p2=headA;
else
p2=p2->next;
}
return p1;
}
而我们也不需要真正做一个大链表,而是当链表A循环完时跳到链表B即可。当相等时退出就找到了相交的点。
反转链表
接下来是一个非常重要的小专题,链表的反转。
链表反转需要考虑到指针的问题,因为指针换了方向之后,原来指向的节点可能会漏掉。
给定一个链表,反转输出。
比如[1,2,3,4,5]变为[5,4,3,2,1]
我们最佳的做法是在原地修改,而不是新建链表。
双指针
定义两个指针,pre和cur。pre指针指向cur的前一个节点。
每次调整cur的指向,使其指向pre。
需要注意的是这里需要一个额外的指针来记录cur的next,不然在cur调整指向时就会找不到下一个节点了。
ListNode* reverseList(ListNode* head) {
ListNode* cur=head;
ListNode *pre=NULL;
ListNode* tmp;
while(cur!=NULL){
tmp=cur->next;//先记下来cur的下一个节点
cur->next=pre;//调整指针方向
pre=cur;//移动pre
cur=tmp;//移动cur
}
return pre;
}
虽然逻辑简单,但也有一些点要清晰:
- 先移动pre再移动cur,顺序不能错。
- 因为最后cur和pre都移动了一步,所以真正的头是pre的位置,返回pre
递归
递归的方法也可以解决这个问题。
说到递归,我们最先接触的可能就是斐波那契数列。
递归有一个理解思路:把函数看作一个整体,而不去代入函数内部钻牛角尖。
比如我们要用递归写一个反转链表的函数,那么我们就不需要考虑如何反转,而是应该考虑这个函数帮我反转之后,我如何处理这个结果。
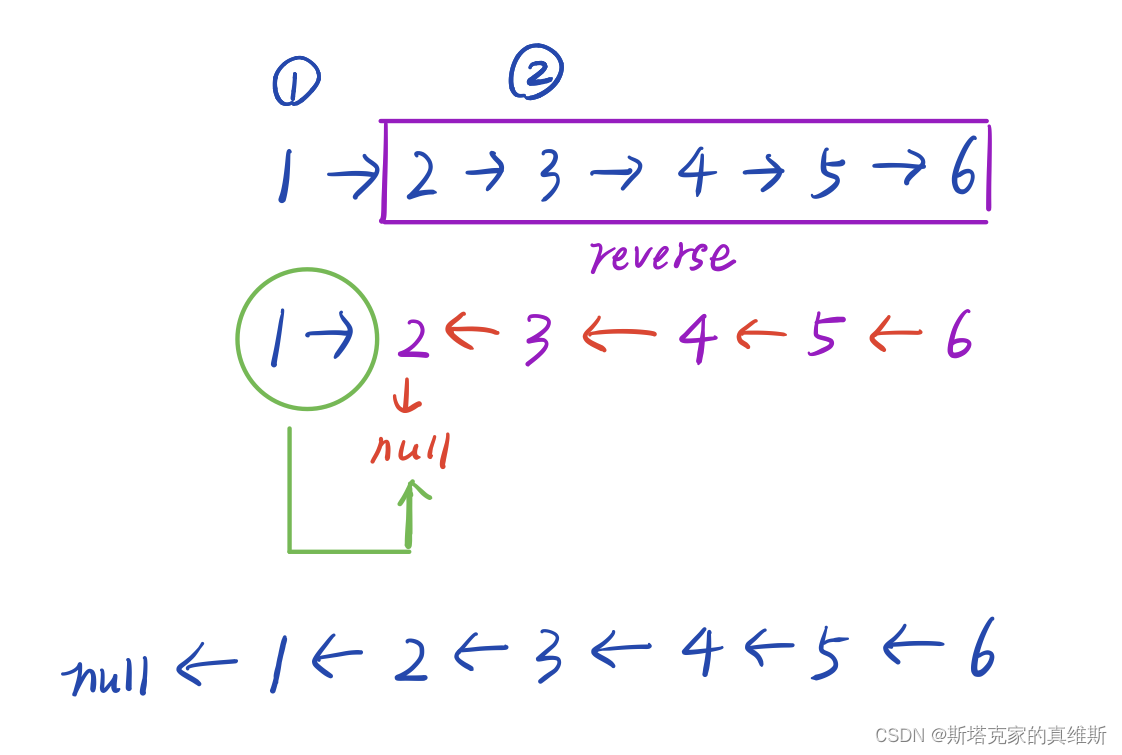
拿这个例子来说。我们想要反转整个链表,就可以先反转2这一部分,然后把1接上即可。
这样理解代码就好写很多了。
ListNode* reverseList(ListNode* head) {
if(head==NULL||head->next==NULL)
return head;
ListNode newHead=reverseList(head.next);
head->next->next=head;
head->next=NULL;
return newHead;
}
reverseList函数接收一个链表头部,然后把它反转。结果我们用newHead接收。
然后调整head与反转后的链表之间的关系,如上图所示。
反转一部分链表
leetocde 92 反转链表2
这道题是上一道题的升级版,要求反转自定义的一部分链表。
因为是left到right的部分反转,其余部分保持不变,所以我们可以用前面写好的双指针解法先把中间的链表反转,再对左右部分进行处理。
而递归的写法也是非常巧妙的。
我们先讨论只考虑right的解法,也就是反转前right个元素。
ListNode reversen(ListNode* head,int right)
仔细思考一下这里与上面的区别。
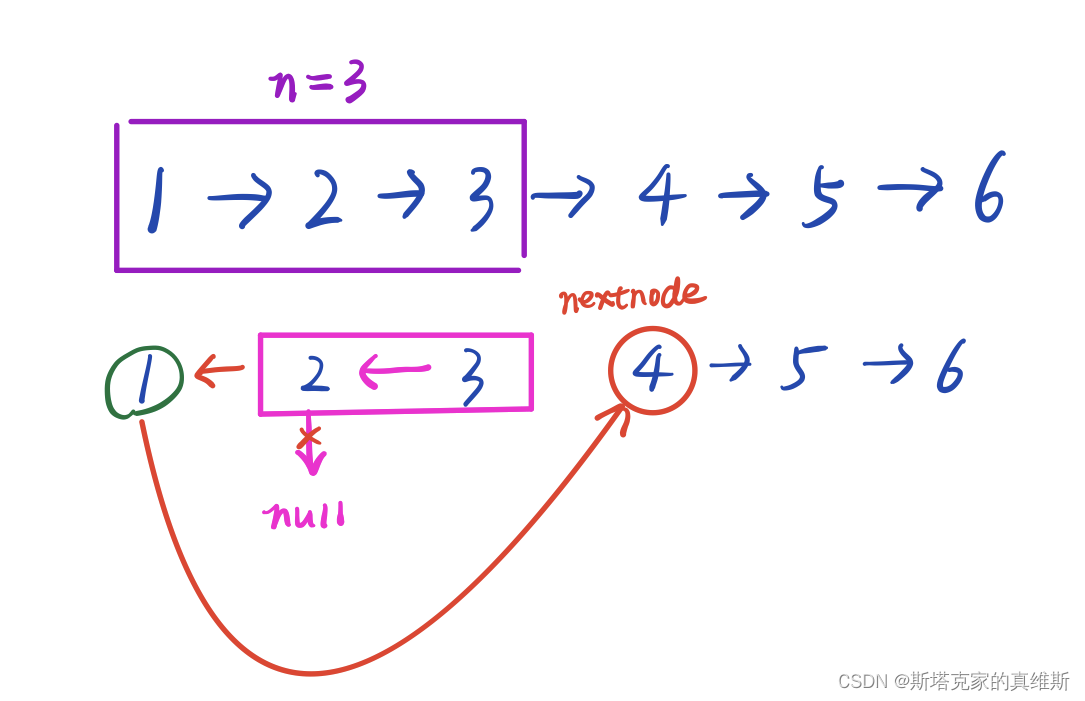
假设right=3,我们反转前三个节点。
对于递归来说依旧是拆分为head和head->next,但这里在调整head时不能指向NULL了,而要指向这里的nextNode也就是4。
如何实现这一步呢?
因为我们在递归时会进行拆分,也就是[1,2,3]会拆成[1]和[2,3],而[2,3]又会拆成[2]和[3]。
所以当n为1时,也就是只有一个需要反转时,这个节点的next就是nextNode。(体会这种层层相扣的关系)
ListNode* nextNode=NULL;//必须定义在外面,因为递归会重新调用
ListNode reversen(ListNode* head,int right){
if(right==1){
nextNode=head->next;
return head;//只有一个需要反转就返回本身
}
ListNode* newHead=reversen(head->next,right-1);//递归反转
head->next->next=head;
head->next=nextNode;
return newHead;
}
有了这些铺垫,我们再来写left和right的版本
ListNode* reverseBetween(ListNode* head, int left, int right)

这时候如果left是1,那么就与上面的反转前right个节点一样了。
如果left不是1,比如上面这个例子,left=3.
如果单独看中间的[3,4,5],是我们需要反转的部分。也会返回newHead也就是5。
所以我们要递归的找到反转的地方,也就是left-1进行拆分。
head->next=reverseBetween(head->next,left-1,right-1);
对于2来说,这个范围就是[left-1,right-1],依次类推。
如果走到需要反转的部分,正好使用head->next来接收。
ListNode* nextNode=NULL;//必须定义在外面,因为递归会重新调用
ListNode* reversen(ListNode* head,int right){
if(right==1){
nextNode=head->next;
return head;//只有一个需要反转就返回本身
}
ListNode* newHead=reversen(head->next,right-1);//递归反转
head->next->next=head;
head->next=nextNode;
return newHead;
}
ListNode* reverseBetween(ListNode* head, int left, int right) {
if(head==NULL||head->next==NULL)
return head;
if(left==1)//当left是1时,与上面的reversen一样
return reversen(head,right);
else{
head->next=reverseBetween(head->next,left-1,right-1);//其他情况往next推
}
return head;
}
总结
小小的总结一下递归这种写法,其实就是拿着函数去做拆分。
对于直接反转全部链表,拆成head和head.next。需要接收新的链表头
ListNode newHead=reverseList(head.next);
对于反转前right个节点,也是拆成head和head.next,但是对于next来说right要-1。考虑特殊情况right=1求得后面的节点,需要连好后面的节点。
ListNode* newHead=reversen(head->next,right-1);
对于反转left到right之间的节点,考虑特殊情况left=1就回到了反转前right个节点。继续拆分,对于next来说left和right都要-1。如果left是1交给上面的函数处理,不是1的话就用head->next接收next的结果
head->next=reverseBetween(head->next,left-1,right-1);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









