







https://github.com/fudan-zvg/Reason2Drive
摘要
大型视觉语言模型(VLM)在自动驾驶领域引起了越来越多的兴趣,因为它们在复杂推理任务中的先进能力对于高度自主的车辆行为至关重要。尽管具有潜力,但由于缺乏带有注释推理链的数据集来解释驾驶中的决策过程,因此对自动驾驶系统的研究受到阻碍。为了弥补这一差距,我们提出了Reason 2Drive,一个基准数据集,超过600 K的视频文本对,旨在促进复杂驾驶环境中可解释推理的研究。我们明确地将自动驾驶过程描述为感知,预测和推理步骤的顺序组合,并且问题-答案对是从各种开源户外驾驶数据集中自动收集的,包括nuScenes,Waymo和ONCE。此外,我们引入了一种新的聚合评估指标,以评估基于链的推理性能在自治系统中,解决现有的指标,如BLEU和CIDER的语义模糊性。基于建议的基准,我们进行实验,以评估各种现有的VLMs,揭示他们的推理能力的见解。此外,我们开发了一种有效的方法,使VLMs在特征提取和预测中利用对象级感知元素,进一步提高其推理精度。将发布代码和数据集。
1.介绍
现代自动驾驶系统面临着与各种场景中的泛化问题相关的挑战,这通常归因于决策过程中对经验和复杂规则的依赖。为了减少对这些规则的依赖,最近开发了端到端方法[19],直接从传感器输入中获取控制信号,将系统视为需要大量数据进行训练的黑盒。然而,这种方法往往会模糊决策的基本逻辑,使实际应用中的故障诊断复杂化。相比之下,大型视觉语言模型(VLM)提供了一个很有前途的替代方案,可能提高这些系统的可解释性和泛化能力。如图1(a)所示,VLM具有广泛的世界知识和先进的推理能力,有可能为可靠的决策提供更透彻的理解和明确的解释。尽管如此,现有的工作[33,40]主要集中在问答任务对自动驾驶的直接适应上;如何利用VLMs来促进自主系统的推理能力仍在探索中。
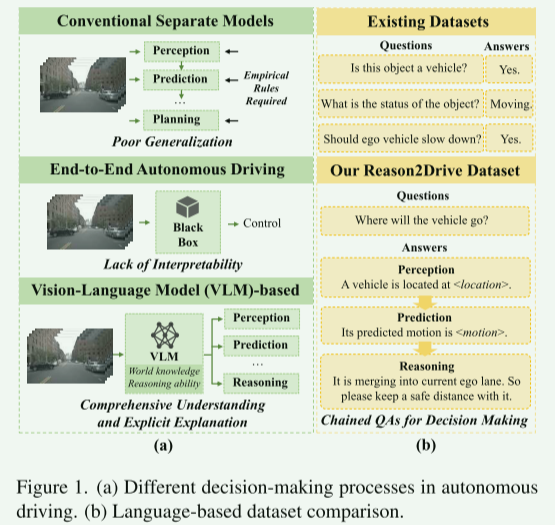
图1.(a)自动驾驶中的不同决策过程。(b)基于数据集的比较。
阻碍这一领域研究的一个原因在于数据集的稀缺,特别是那些阐明决策过程的基于链的推理标签。大多数现有的数据集[10,33,41]往往过度简化了驾驶到简单的问答任务的复杂过程,只涵盖了一些特定的任务。如图1(B)所示,它们通常提供约束为布尔值的封闭形式的注释(即,是或否)答案或有限的多项选择回答(例如,停止,停车,移动)。然而,自动驾驶超越了简单的QA过程。它包括一个多步骤的方法,涉及感知,预测和推理,其中每一个都在决策中发挥着不可或缺的作用。因此,它是至关重要的,引入一个新的基准注释详细的决策推理评估当前VLMs的推理能力。
为此,我们引入了Reason 2Drive,这是一个新的基准测试,包括超过600 K的视频文本对,其特点是复杂的驾驶指令和一系列的感知,预测和推理步骤。我们的基准建立在广泛使用的开源驾驶数据集之上,包括nuScenes [2],Waymo [36]和ONCE [26],利用可扩展的注释模式。具体来说,我们提取对象元数据,将其结构化为JSON格式,并将其集成到预定义的模板中,以便在对象和场景级别为VLM创建配对数据。为了提高多样性,GPT-4和人工注释用于验证和富集目的。值得注意的是,Reason 2Drive是迄今为止可用的最广泛的数据集,在规模和推理链的复杂性方面优于现有数据集,这是其他数据集中不存在的独特属性。此外,我们观察到目前对自动驾驶任务的VLM评估存在根本性缺陷,这是由于传统的基于字幕的指标(如BLEU [29]和CIDEr [39])固有的语义模糊性。例如,具有对比意义的句子,如“它将左转”和“它将右转”,可能会在BLEU中获得高分,这在自动驾驶的背景下尤其成问题。为了解决这个问题,我们提出了一个新的聚合评估指标,专门设计用于测量基于链的推理性能在自治系统中,其目的是解决与当前指标相关的语义歧义。
利用所提出的基准,我们进行实验,以评估各种现有的VLMs,从而揭示其推理能力的宝贵见解。我们发现,大多数方法都很难有效地利用感知先验,导致推理性能低于标准。此外,受语言模型仅作为解码器的限制,这些方法通常无法提供准确的感知结果,这是验证模型空间推理能力的关键组成部分。为了缓解这种困境,我们提出了一个简单而有效的框架,增强现有的VLM与两个新的组件:一个事先tokenizer和一个指示的视觉解码器,其目的是分别加强模型的视觉定位能力的编码器和解码器。
本文的贡献总结如下:
(i)我们发布了一个新的视觉指令调优数据集,旨在促进可解释的和基于链的推理自治系统。
(ii)我们引入了一种新的评估指标来评估自动驾驶中基于链的推理性能,有效地解决了现有指标中存在的语义模糊性。
(iii)我们进行实验,以评估一系列现有的VLMs,揭示其推理能力的宝贵见解。
(iv)为了解决效率低下的先验特征提取和不准确的感知预测所带来的挑战,我们引入了一种有效的方法将这些整合到VLM中,从而大大提高了推理精度。我们的方法超越了所有基线,特别是在看不见的场景中实现了令人印象深刻的泛化。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4149
4149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









