






Liu Z, Mao H, Wu C Y, et al. A convnet for the 2020s[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 11976-11986.
- Introduction
Vision Transformers (ViTs) some difficulties: general computer vision tasks a family of pure ConvNet: ConvNeXt
ideas: intrinsic superiority rather than the inherent inductive biases of convolutions.
results: COCO detection and ADE20K segmentation

convolutional neural networks
from engineering feature to designing architectures
LeNet5——1980s
2012, AlexNet, VGG, ResNet, MobileNet, EfficientNet
- Methods: from ResNet to ConvNet
macro design
ResNeXt
inverted bottleneck
large kernel size
layer-wise micro designs
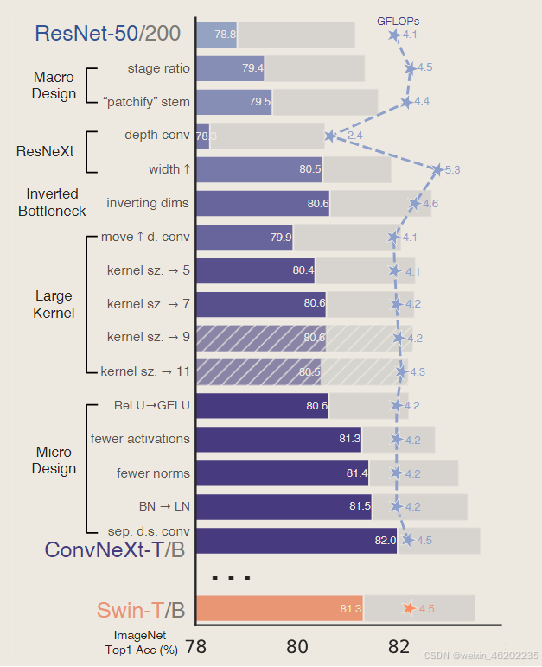
- Methods: training techniques
train a baseline model with vision Transformer training procedure
AdamW optimizer
augmentation techniques
hyper-parameters
average of three random seeds
- Methods: macro design
Swin Transformers
multi-stage design (a different feature map resolution)
stage compute ratio
“stem cell”
Swin-T: 1:1:3:1 Swin-L: 1:1:9:1
(3, 4, 6, 3) in ResNet50 to (3, 4, 9, 3)
- Methods: ResNeXt-ify
ResNeXt——FLOPs / accuracy
core component: grouped convolution
grouped convolution for the 3x3 conv layer in a bottleneck block
depthwise convolution: mixing information in the spatial dimension
- Methods: large kernel sizes
large convolutional kernels
non-local self-attention
VGGNet
local window: 7x7
move up the position of the depthwise conv layer ( from (b) to (c) )
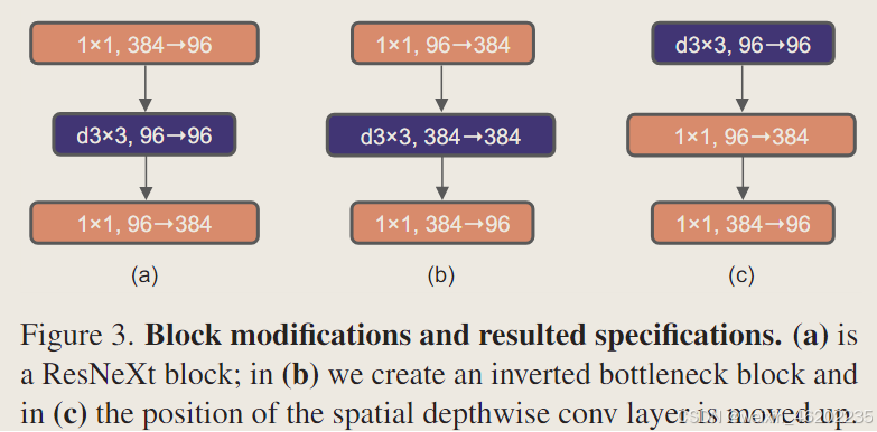
- Methods: micro design
at the layer level
activation functions and normalization layers
Rectified Linear Unit to Gaussian Error Linear Unit
BERT, GPT-2, ViTs
at the layer level
activation functions and normalization layers
fewer activation functions
fewer normalization layers
BatchNorm to Layer Normalization
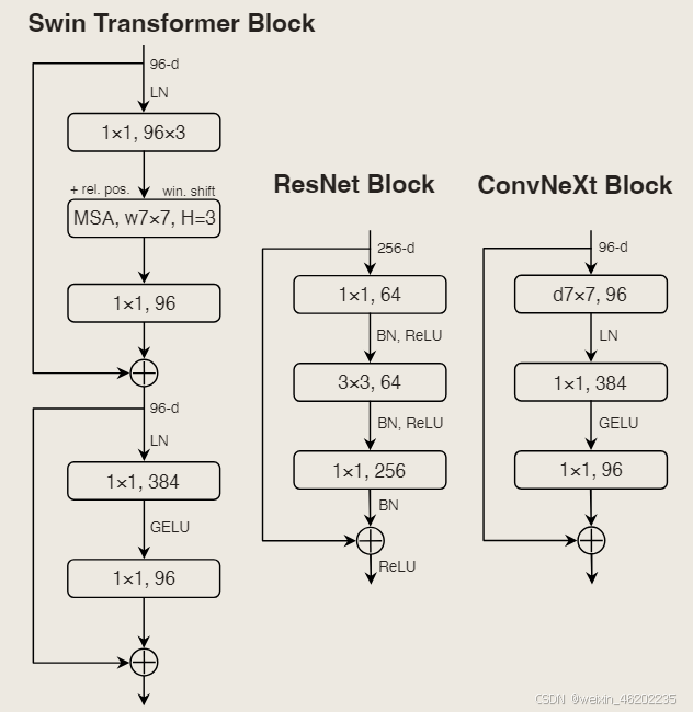
at the layer level
separate downsampling layers
residual block (3x3 conv with stride 2, 1x1 conv with stride 2 at the shortcut connection)
2x2 conv layers with stride 2 for spatial downsampling
adding normalization layers wherever spatial resolution is changed
- Results
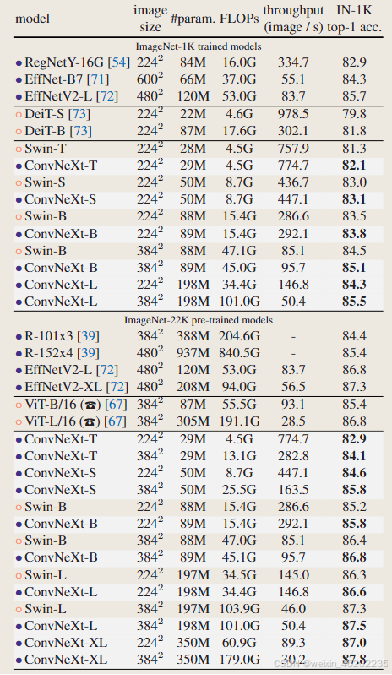
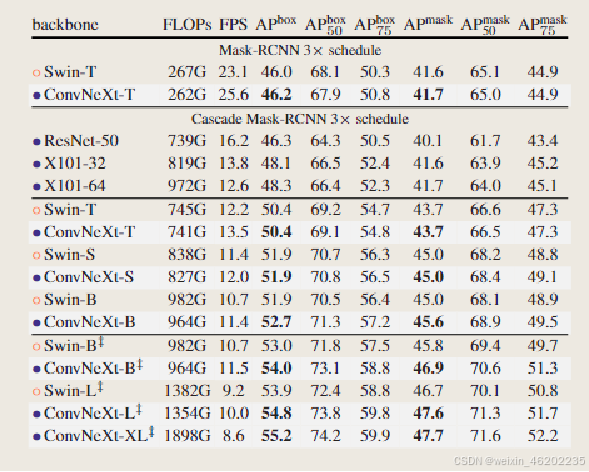
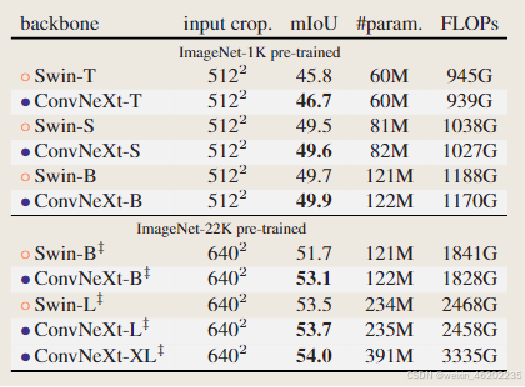
- Conclusion
In the 2020s,vision Transformers,特别是分层Transformers,如swin Transformer,开始超越ConvNets作为通用视觉backbones的首选。人们普遍认为,vision Transformers比ConvNets更准确、更高效和可扩展。 本文提出了 ConvNeXts是一种ConvNet模型,可以在多个计算机视觉基准上与最先进的分层Transformers比较,同时保持标准卷积网络的简单性和效率。在某种程度上,观察结果令人惊讶,ConvNeXt 模型本身并不是全新的——在过去的十年中,许多设计选择是单独检查的,但不是集体的。希望本研究中的新结果将挑战几个广泛持有的观点,并促使人们重新思考卷积在计算机视觉中的重要性。

















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









