






 本文详细介绍了内存的3个主要段:堆、栈和代码段。堆是通过空闲表和链表管理的大数组,不常进行压缩。栈用于存储活动记录,与活动函数数量成比例。代码段则存放机器码。讨论了定长和变长指令编码在不同指令集中的应用。
本文详细介绍了内存的3个主要段:堆、栈和代码段。堆是通过空闲表和链表管理的大数组,不常进行压缩。栈用于存储活动记录,与活动函数数量成比例。代码段则存放机器码。讨论了定长和变长指令编码在不同指令集中的应用。
内存模型抽象
1 内存的 3 segment 模型

2 Heap Segment
“堆内存管理器”负责“堆”的管理!
这里有个概念叫做“空闲表”!堆内存管理器是以“链表”的数据结构为基础管理堆中的一个个数据块的!
2.1 堆是个大数组!
- 整个“堆”的概念

- 堆中单个数据块的结构:

思考:如果对“静态”数组使用free()会造成什么后果?
答:假如 free() 成功了!会把“栈”中的空间加入到堆管理器的“空闲表”里面!
2.2 “堆内存压缩”概念
一般现在的计算机不支持“堆内存压缩”,因为现在的内存都很大了(普遍达到 8/16/32GB),不需要去堆区里面抠唆那么一点点空间!
Macintosh(1994~1995) 支持堆内存压缩,可以将已经使用的数据块放在一起,没使用的数据块放在一起,从而可以拼出更大的空闲数据块!

但是也有问题哦:堆内存管理器在移动数据块的时候,这些数据不能被访问!即:堆内存的压缩与2级指针的 dereference 不能同时执行!
使用“可压缩的Heap” 的步骤:
void **handle = NewHandle(40); // 二级指针开辟(可压缩的)动态内存
...
...
...
HandleLock(handle); // 告诉堆管理器,俺要用这个数据块,别给俺压缩!
...
...
HandleUnlock(handle); // 告诉堆管理器,俺用完了,请继续你的压缩!
2.3 “堆分块”概念
源于存储空间的“对齐”概念!整个堆的空间被分配得东一块西一块的,并且每块大小都不一样,有的是 8 bytes,有的是 16 bytes,有的是 64 bytes;这样导致“空闲块”也分布得七零八乱的!
我们能不能让这些数据块的大小都固定!让这些数据块都能够对齐呢?

3 Stack Segment
3.1 活动记录
栈中“被使用的部分大体”(即栈中正在执行的所有函数的“深度”)上与“活动函数的数量”成比例!
栈中存放着“活动记录”——调用函数时,用这个“栈”去记录调用顺序(深度)!
假设:栈向“下”生长!
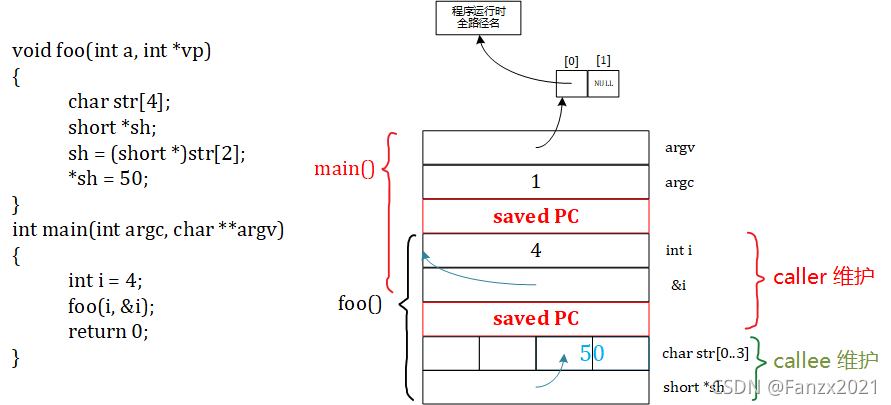
由上图可见,调用函数层次越深,这个栈也越深!
4 Code Segment
这里存放二进制的“机器码”

4.1 定长指令编码
I n s t r u c t i o n = < 操 作 码 ( o p c o d e ) > + < 操 作 数 ( o p e r a n d ) > Instruction = <操作码(opcode)> + <操作数(operand)> Instruction=<操作码(opcode)>+<操作数(operand)>
问题:所有的指令都能够编码到 4 bytes 以内吗?
答:可以,即使是 CISC 的 MCS-51 指令集,也不过 111 条指令!现代计算机常用的 RISC 指令集中只有数十条指令而已!
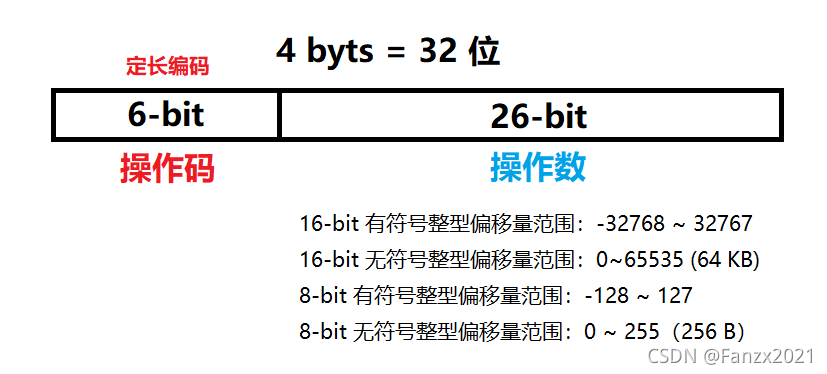
比如:假设某某指令集一共59条指令,所以操作码(opcode)需要使用 6 位,编码
2
6
=
64
2^6=64
26=64 种模式!
4.2 变长指令编码
变长(Huffman, 哈夫曼)指令编码,可以根据实际情况缩短操作码(opcode)的长度,从而给操作数(operand)更多位数!
MIPS就是变长编码!!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









