




 这篇博客主要介绍了如何使用高通字库制作汉字字库,特别是针对GB2312字符,通过C语言进行文件操作,将字形码分割并写入AT25F4096芯片,以便在OLED显示。内容包括区位码解析、文件处理技巧,如创建、打开、定位、读取和关闭文件。
这篇博客主要介绍了如何使用高通字库制作汉字字库,特别是针对GB2312字符,通过C语言进行文件操作,将字形码分割并写入AT25F4096芯片,以便在OLED显示。内容包括区位码解析、文件处理技巧,如创建、打开、定位、读取和关闭文件。
本部分2个工作:
① 向 AT25F4096 写入部分 HZK8x16 转化后的 “列行式” 数据
② 解码 GB2312 字符,根据码值,去 AT25F4096 中寻找对应的点阵数据,然后送入 OLED 显示
为OLED制作汉字字库_第4部分
1 看看别人的字库怎么做的
1.1 高通字库
先看看别人怎么做的:这方面的龙头大哥——“高通字库”
http://www.gaotongfont.cn/index.html
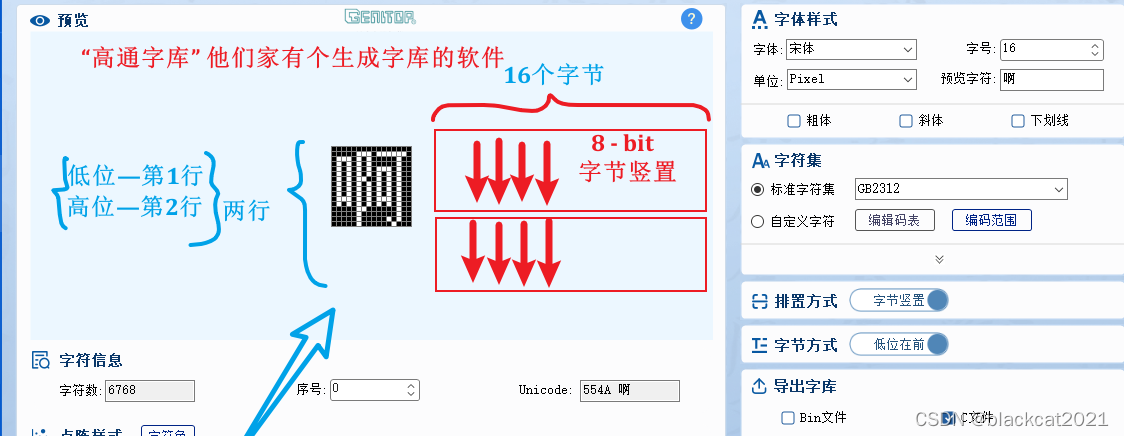
利用“高通字库”生成个超级大的“列行式”点阵数据数组:
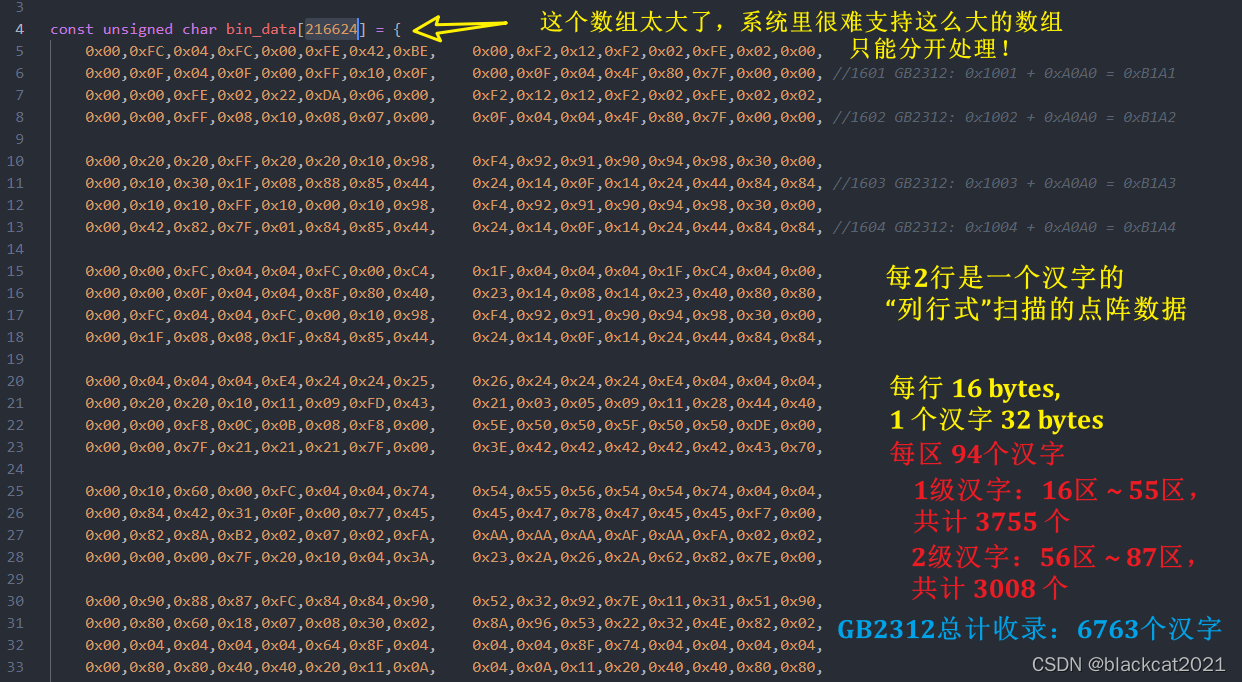

总计:
216576 32 = 6768 \frac{216576}{32} = 6768 32216576=6768
问题:不是说 6763 个汉字吗?为啥这里算出来是 6768 个呢?多出来 5 个在哪里 ?
答:在 55 区有 5 个空位

1.2 GB2312 部分区位码




1.3 C语言文件操作
用“高通字库”软件,生成了GB2312字库的点阵字形码,将这些字形码按照区生成一个个小文件,方便使用。考验“文件操作”功底的时候到了!!!

1.3.1 生成每个区的字形码
因为“高通字库”软件生成的原始数组太大了,系统处理不了这么大的数组,只能 “分成两半” 处理,定义偏移量 OFFSET == 16,汉字从16区开始,然后到 55 区时,(手动更改 OFFSET = 55) 再分割一次,劈成两半,系统就能够处理了!每次处理时,不用的另一半注释掉!!!
① 16 ~ 54 第一部分
② 55 ~ 87 第二部分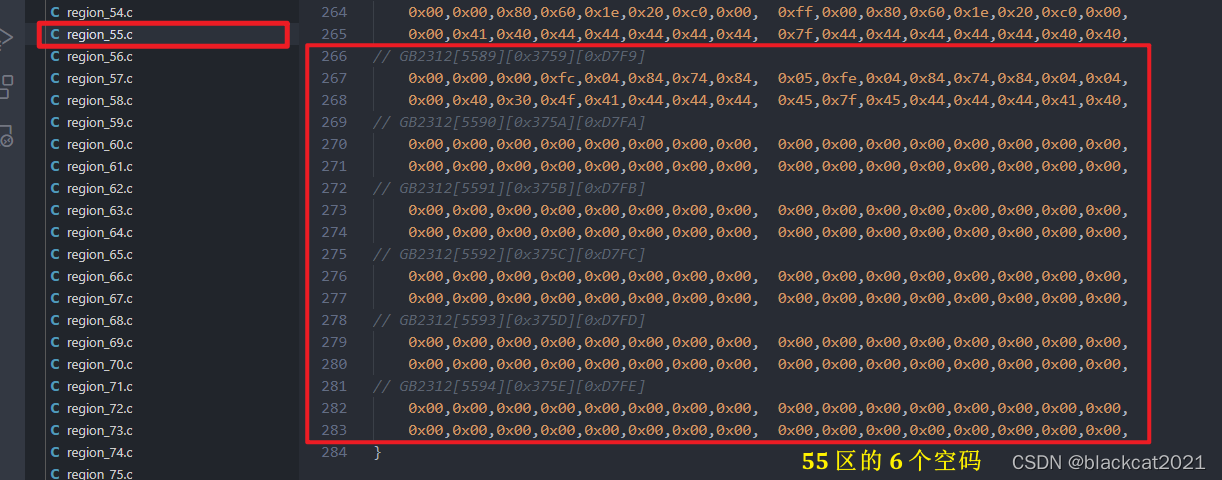
#define OFFSET 16
void generateRegionCode(int region){
if(region < OFFSET){
return;
}
char buf[64] = "./Font16_16/region_";
sprintf(buf, "%s%d", buf, region);
strcat(buf, ".c");
// puts(buf);
FILE *pf = fopen(buf, "w");
if(pf == NULL){
perror("file open failed:");
return;
}
sprintf(buf, "const unsigned char region_%d_dat[%d] = {\n", region, 94 * 32);
fputs(buf, pf);
for(int n = 0; n < 94; n++){
fprintf 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3370
3370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









