






1.在谷歌浏览器安装Xpath
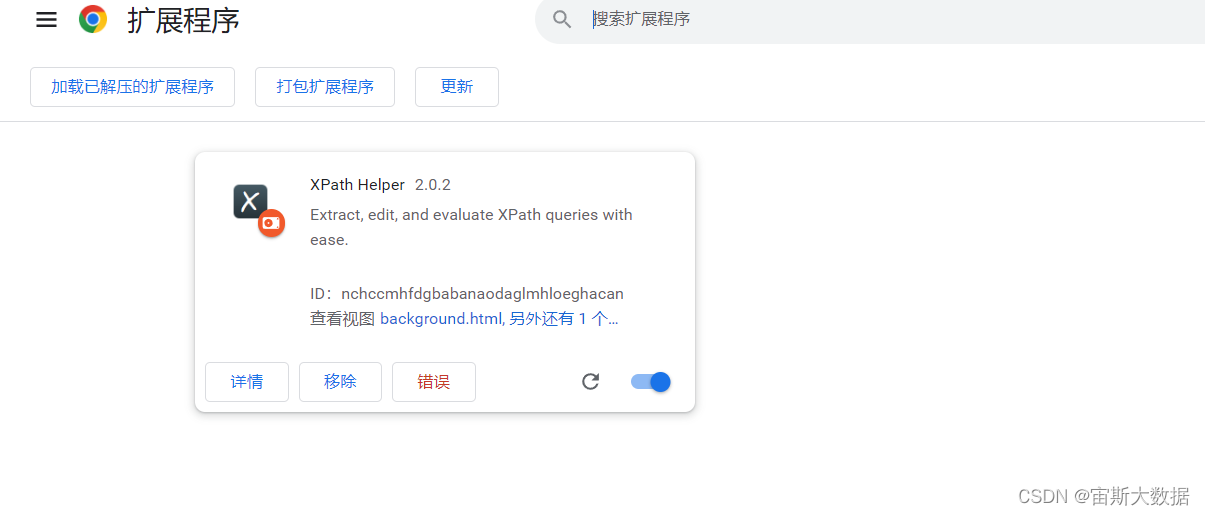

需要文件的可评论我要
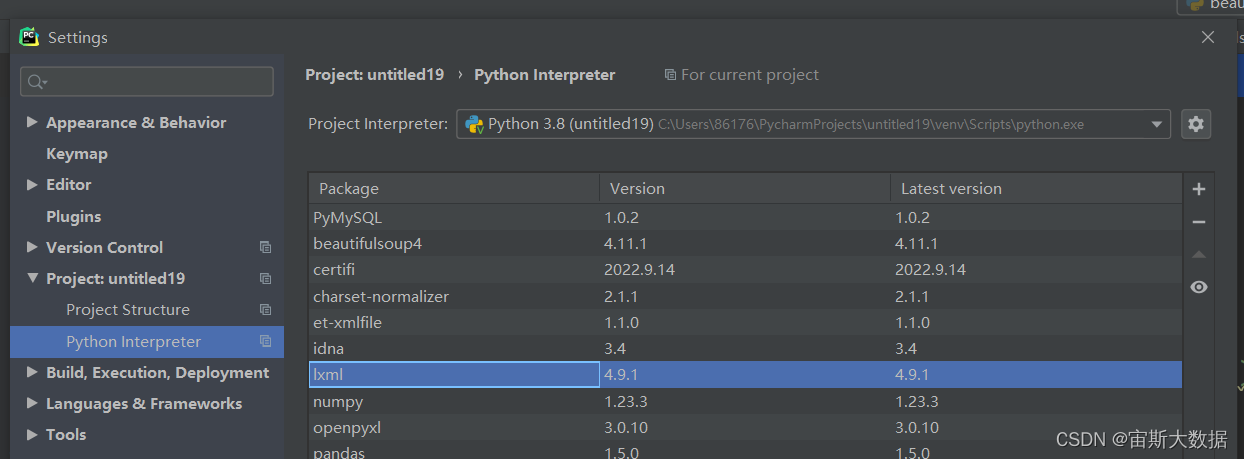
2.使用Pycham导入相应的包
import requests
from lxml import etree
!!!注:没有安装相应的包可在Pycham搜索安装
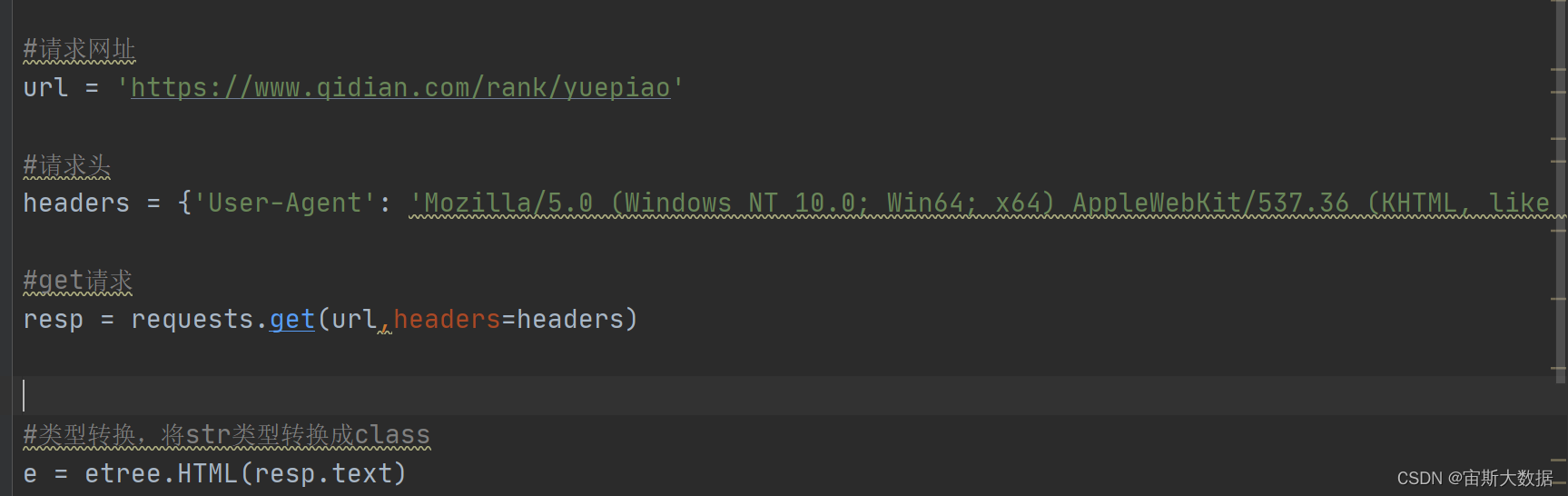
3.请求url网址是https://www.qidian.com/rank/yuepiao
#请求网址
url = ‘https://www.qidian.com/rank/yuepiao’
#请求头
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36’}
#get请求
resp = requests.get(url,headers=headers)
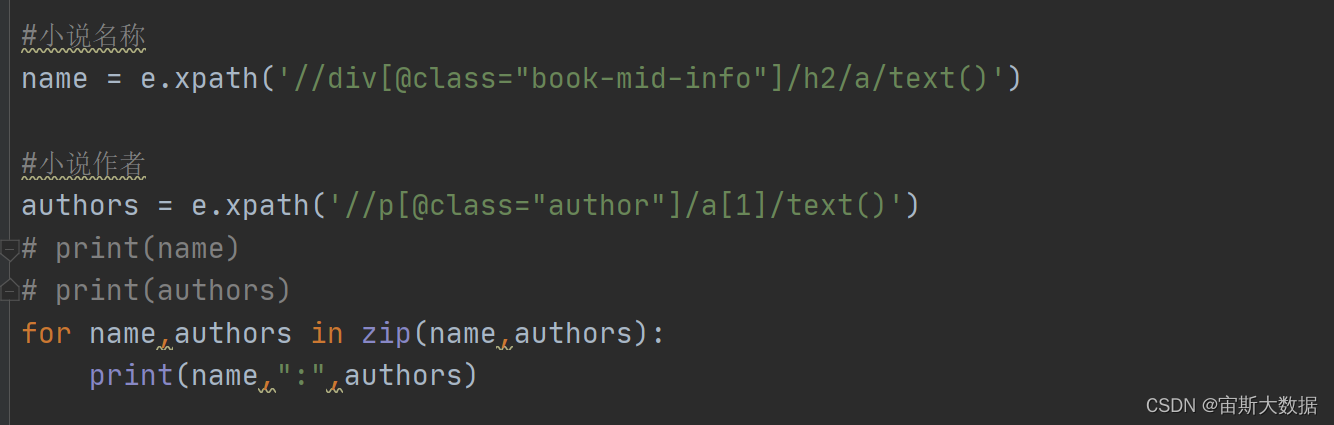
4.#小说名称
name = e.xpath(‘//div[@class=“book-mid-info”]/h2/a/text()’)
#小说作者
authors = e.xpath(‘//p[@class=“author”]/a[1]/text()’)
#print(name)
print(authors)
for name,authors in zip(name,authors):
print(name,“:”,authors)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









