







 本文介绍了支持向量机(SVM)的基本概念,包括最大间隔分割数据、支持向量和最大间隔原则。详细讨论了线性可分情况下的超平面选择,以及最大化间隔的重要性。此外,还介绍了简化版和Platt SMO算法的实验操作,展示了如何通过优化算法提高分类效率。最后,总结了SVM的优缺点,强调了其在处理线性不可分问题和小样本集上的优势,同时也指出其在面对多分类和大规模数据集时的挑战。
本文介绍了支持向量机(SVM)的基本概念,包括最大间隔分割数据、支持向量和最大间隔原则。详细讨论了线性可分情况下的超平面选择,以及最大化间隔的重要性。此外,还介绍了简化版和Platt SMO算法的实验操作,展示了如何通过优化算法提高分类效率。最后,总结了SVM的优缺点,强调了其在处理线性不可分问题和小样本集上的优势,同时也指出其在面对多分类和大规模数据集时的挑战。
目录
一、简介
1.概述
支持向量机(SVM,也称为支持向量网络),支持向量机(support vector machines)是一种二分类模型,监督式学习 (Supervised Learning)的方法,主要用在统计分类 (Classification)问题和回归分析 (Regression)问题上。它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。是机器学习中获得关注最多的算法没有之一。
2.基于最大间隔分割数据

线性可分:可以很容易就在数据中给出一条直线将两组数据点分开
分隔超平面:将数据集分割开来的直线。数据点在二维平面上,分隔超平面就只是一条直线,但数据集是三维时,那么分隔超平面就是一个平面。依此类推,如果数据集是 N ( N ≥ 2 N(N\geq2 N(N≥2)维时,那么就需要一个 N − 1 N-1 N−1维的对象来分隔数据。该对象被称为超平面,也就是分类的决策边界。理想状态是分布在超平面一侧的所有数据都属于某个类别,而分布在另一侧的所有数据则属于另一个类别。
间隔:离分隔超平面最近的点,到分隔面的距离。间隔应该尽可能地大,这是因为如果我们犯错或者在有限数据上训练分类器的话,大的间隔可以增加分类器的鲁棒性。
支持向量:离分隔超平面最近的那些点。支持向量到分割面的距离应该最大化。
3.最大间隔
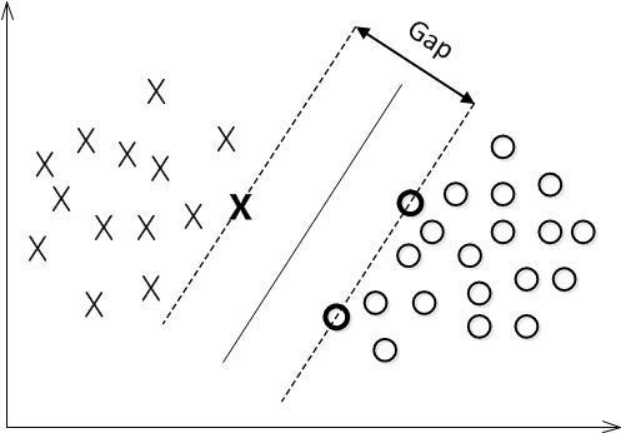
对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是下图中的Gap的一半。
分隔超平面的形式为:![]()
点A到分隔超平面的法线长度:![]()
最大化间隔的目标就是找出分类器定义中的w和b。为此,我们必须找到具有最小间隔的数据点,而这些数据点也就是前面提到的支持向量。一旦找到具有最小间隔的数据点,我们就需要对该间隔最大化。这就可以写作:

直接求解上述问题相当困难,所以我们将它转换成为另一种更容易求解的形式。

约束条件为:

其中常数C 用于控制 “最大化间隔” 和 “保证大部分点的函数间隔小于1.0” 这两个目标的权重。在优化算法的实现代码中,常数C 是一个参数,因此可以通过调节该参数得到不同的结果。一旦求出了所有的 α,那么分隔超平面就可以通过这些 α 来表达。
二、实验操作
1.简化版SMO算法
简化版SMO算法,省略了确定要优化的最佳 α 对的步骤,而是首先在数据集上进行遍历每一个 α ,再在剩余的数据集中找到另外一个 α ,构成要优化的 α 对,同时对其进行优化,这里的同时是要确保公式:
所以改变一个 α 显然会导致等式失效,所以这里需要同时改变两个 α 。
代码如下:
from time import sleep
import matplotlib.pyplot as plt
import numpy as np
import random
import types
"""
函数说明:读取数据
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
labelMat - 数据标签
"""
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines(): #逐行读取,滤除空格等
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])]) #添加数据
labelMat.append(float(lineArr[2])) #添加标签
return dataMat,labelMat
"""
函数说明:随机选择alpha
Parameters:
i - alpha
m - alpha参数个数
Returns:
j -
"""
def selectJrand(i, m):
j = i #选择一个不等于i的j
while (j == i):
j = int(random.uniform(0, m))
return j
"""
函数说明:修剪alpha
Parameters:
aj - alpha值
H - alpha上限
L - alpha下限
Returns:
aj - alpah值
"""
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
"""
函数说明:简化版SMO算法
Parameters:
dataMatIn - 数据矩阵
classLabe 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









