







Proposal
propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
Contributions
1、The Transformer allows for significantly more parallelization.
2、The Transformer can reach a new state of the art【Performance】 in translation quality after being trained for as little as twelve hours【time】 on eight P100 GPUs.
3、The Transformer is more interpretable.
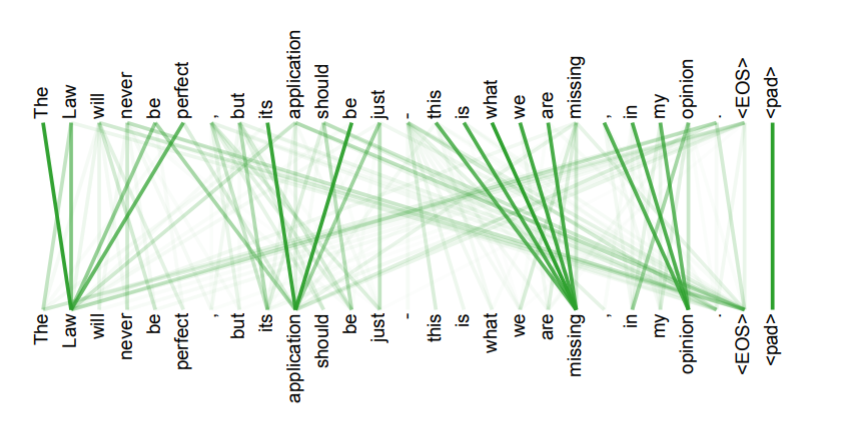
4、The Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution.
Architecture
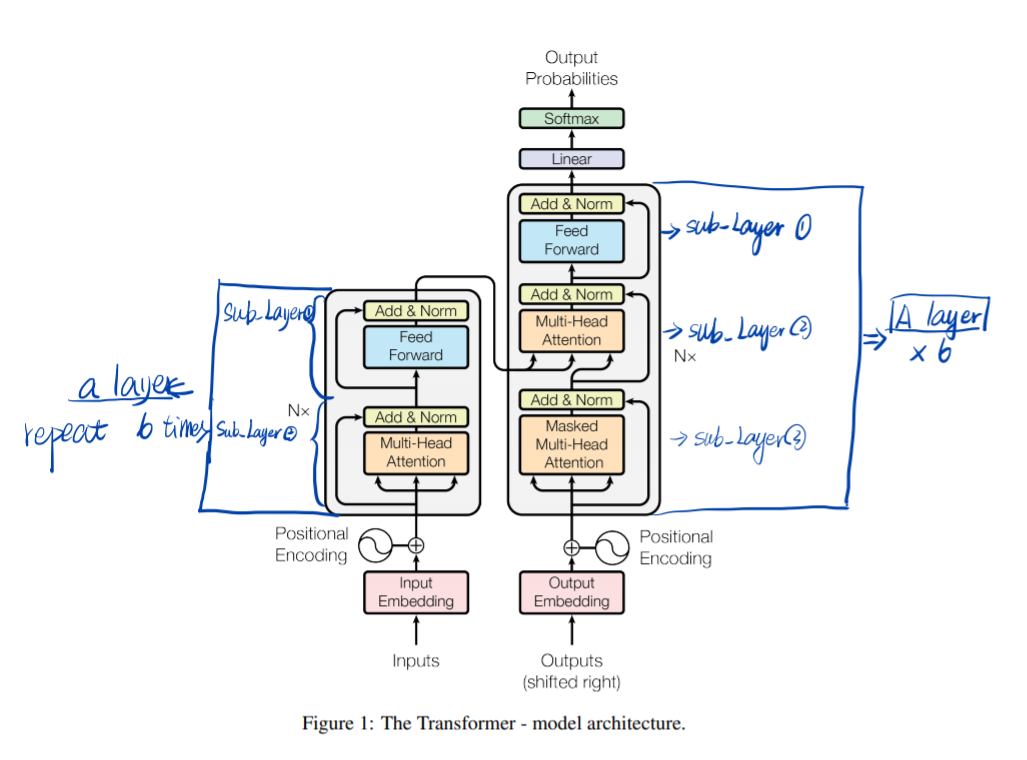
Attention function
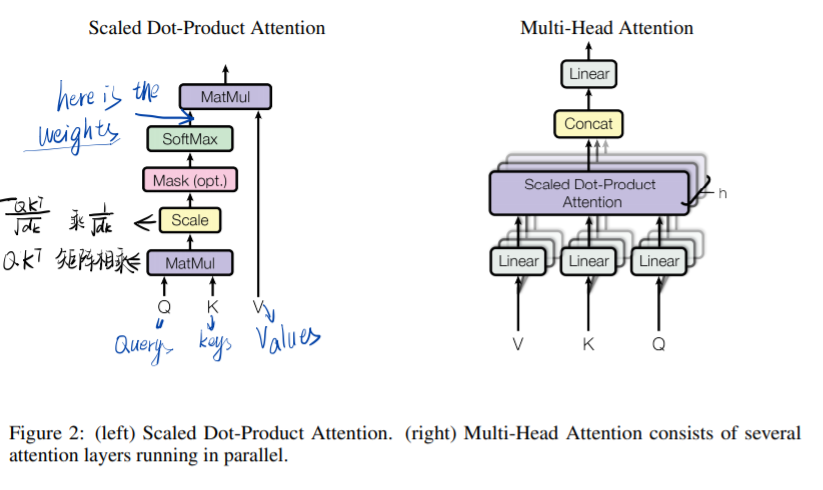
Left is the Scaled Dot-Product Attention, and right is the Multi-Head Attention consists of several attention layers running in parallel.
Note that the total computational cost of the Multi-Head Attention is similar to that of single-head attention with full dimensionality.
Position Encoding
inject some information about the relative or absolute position of the token in the sequence.

思路要点
感觉全篇都是要点。

















 1441
1441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









