







参考:https://blog.youkuaiyun.com/weixin_41803874/article/details/107692319
生成方法 vs 对比方法
当代的自监督学习方法大致可以分为两类:
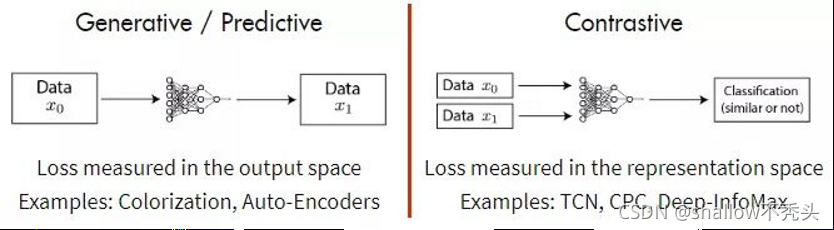
对比学习思想
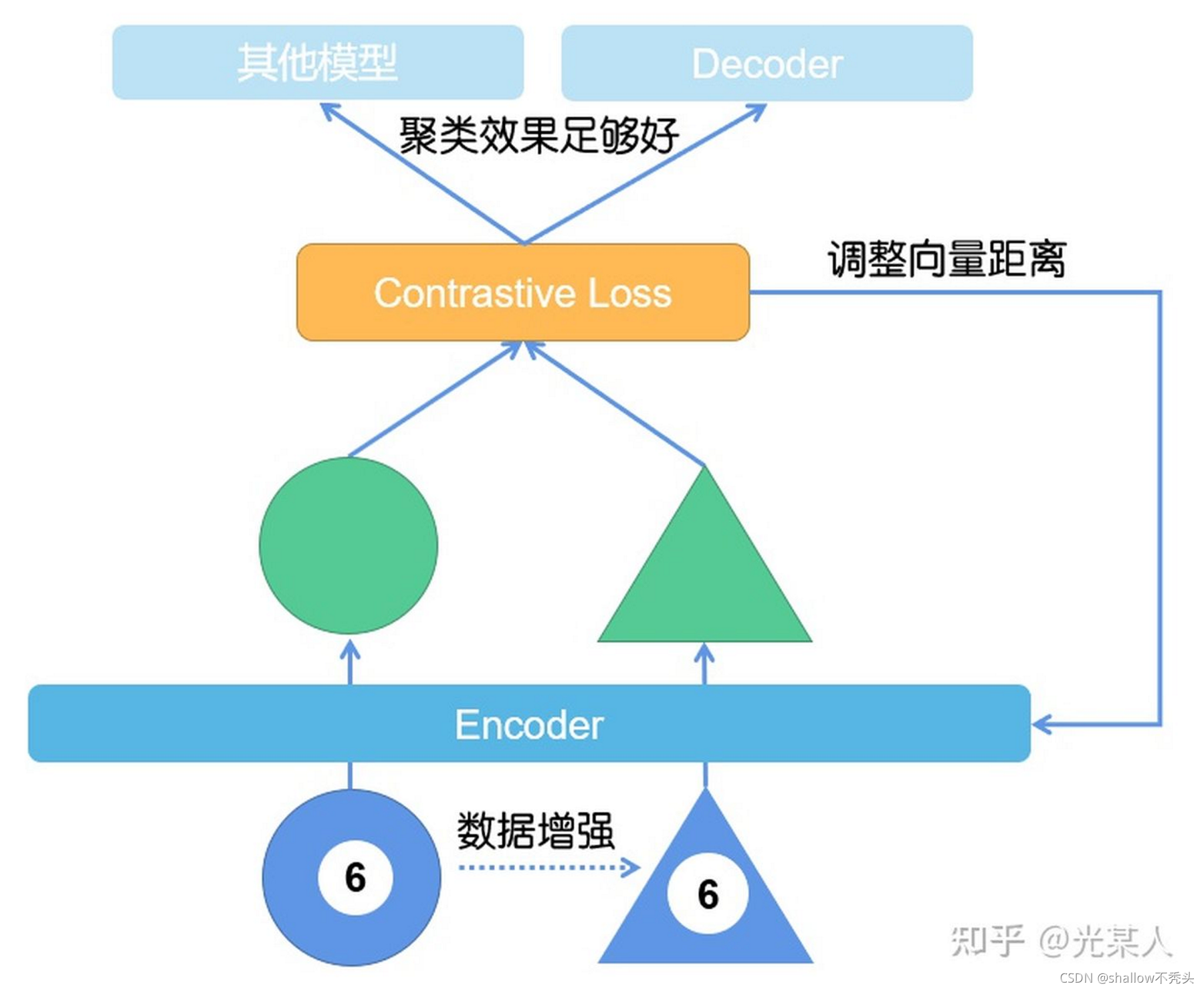
对比方法如何工作?
即,最终目标是,缩小与正样本间的距离,扩大与负样本间的距离,使正样本与锚点的距离远远小于负样本与锚点的距离,(或使正样本与锚点的相似度远远大于负样本与锚点的相似度),从而达到他们间原有空间分布的真实距离。
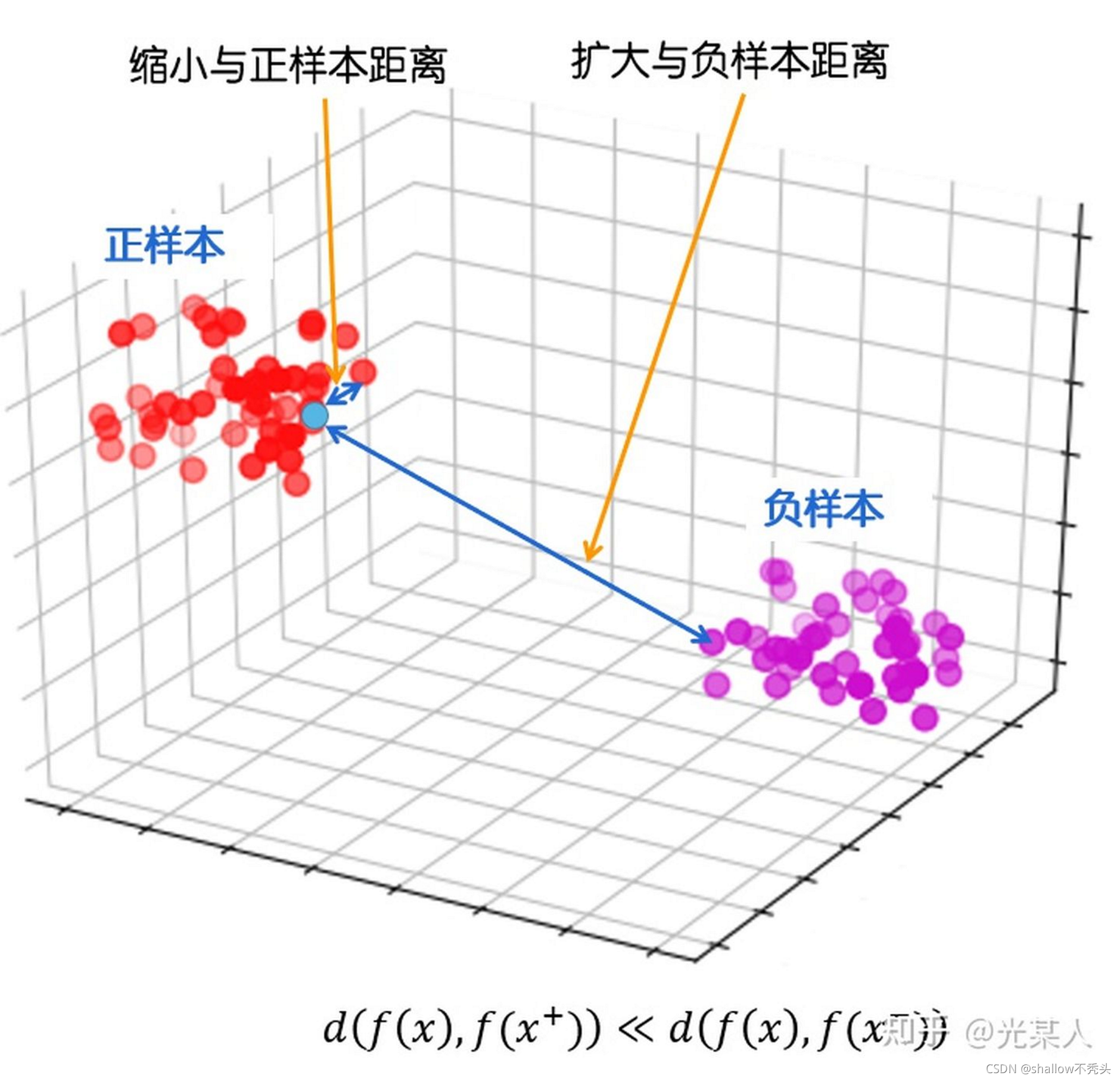
更正式地说,对于任何数据点x,对比方法的目的是学习编码器f:
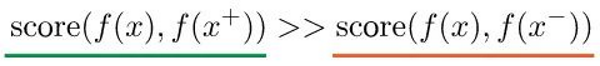
• 这里x+是与x相似或相等的数据点,称为正样本。
• x−是与x不同的数据点,称为负样本。
• score函数是一个度量两个特征之间相似性的指标。
X通常被称为“锚”数据点。为了优化这一特性,我们可以构造一个softmax分类器来正确地分类正样本和负样本。这个分类器鼓励score函数给正例样本赋于大值,给负样本赋于小值:
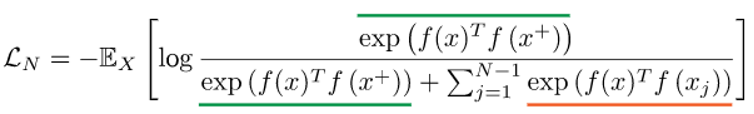
分母项由一个正样本和N - 1个负样本组成。这里我们使用点积作为score函数:
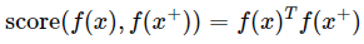
这是N-way softmax分类器常见的交叉熵损失,在对比学习文献中通常称为InfoNCE损失。在之前的工作中,我们将其称为多类n-pair loss和基于排序的NCE。
InfoNCE也与互信息有关系。具体地说,最小化InfoNCE损失可使f(X)和f(X+)之间互信息的下界最大化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









