







 决策树是一种计算复杂度较低、易于理解和处理缺失值的分类和回归方法。其主要缺点是可能出现过拟合。信息熵用于衡量信息量,决策树构建过程中通过分裂属性来提高数据的纯度。ID3算法是常见的决策树构建算法,其目标是选择能最大程度减少熵的特征进行分裂。条件熵公式用于指导节点的分裂,以达到最佳分类效果。
决策树是一种计算复杂度较低、易于理解和处理缺失值的分类和回归方法。其主要缺点是可能出现过拟合。信息熵用于衡量信息量,决策树构建过程中通过分裂属性来提高数据的纯度。ID3算法是常见的决策树构建算法,其目标是选择能最大程度减少熵的特征进行分裂。条件熵公式用于指导节点的分裂,以达到最佳分类效果。
决策树的优缺点
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。既能用于分类,也能用于回归
- 缺点 可能产生过度匹配问题
- 信息熵是衡量信息量多少的,信息熵越大,说明包含信息越多,内部混乱程度越大
- 决策树可以是二叉树或非二叉树
- 使用决策树进行决策的过程就是从根节点开始,测试待分类项目的特征属性,并按照其值选择输出分支
决策树构造
分类解决离散问题, 回归解决连续问题
- 决策树:信息论
- 逻辑斯蒂回归,贝叶斯:概率论
- 构建决策树的关键步骤是分裂属性,所谓分裂属性就是再某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集经可能的 纯。
- 尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
常用的ID3算法
-
划分数据集的大原则是:将无序的数据变得更加有序
-
entropy(熵)
定义信息的期望值
其中p(x)是选择该分类的概率

-
为了计算熵,我们需要计算所有类别,所有可能值包含的信息期望值,通过下面的公式

#一本电子书50万字
#假设50w电子书出现的汉字有7000个,并且等概率分布
#一个汉字最多需要多少比特
p_ch = 1/7000
-(7000 * p_ch * np.log2(p_ch))


熵
- 通常当你测量熵,看到熵的度量,你将看到对数的总和
- 这是产品的对数
- 产品是一堆概率

-m*np.log2(m)-n *np.log2(n)


2.
-a*np.log2(a)-b*np.log2(b)-c*np.log2(c)-d*np.log2(d)
2的另外一种写法.
-a*np.log2(a)-b*np.log2(b)-2*c*np.log2(c)
3.
-4*a*np.log2(a)
- 选择消除不确定性最多的特征做为根节点
- 根节点消除不确定性慢慢表少
例子2
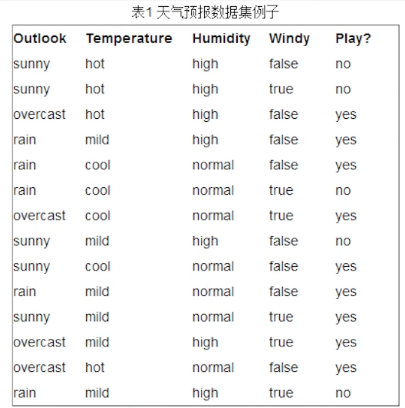
出去玩 5
出去玩 9
p_yes = 9/14
p_no = 5/14
-p_yes*np.log2(p_yes)-p_no*np.log2(p_no)
信息熵0.9402859586706311 不确定性为0.94
如何确定那个列对我们重要
条件熵公式
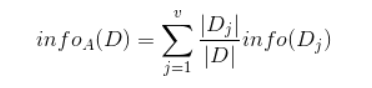
- u 是几种情况
- outlook 有3个条件熵 u=3
- D代表样本集总数量
- Dj 代表
- info(Dj)对应子集的信息熵
条件熵:当加上这个条件以后,我们的信息熵不确定性减少的程度越大,那么这一列对我们决策的贡献就越大
o_s_y = 2/5
o_s_n = 3/5
o_r_y = 3/5
o_r_n = 2/5
o_o_y = 1
o_o_n = 0
p(play?|outlook)
outlook 有3个条件熵 非别是 sunny,rain,overcast
sunny
(-o_s_y*np.log2(o_s_y) -o_s_n*np.log2(o_s_n))*(5/14)
0.3467680694480959
rain
(-o_r_y*np.log2(o_r_y) -o_r_n*np.log2(o_r_n))*(5/14)
0.3467680694480959
overcast
o_o-_y = 1
0
# outlook + play 后的信息熵
(play? | outlook)
(play & outlook)=(0.3467680694480959+0.3467680694480959+0)
0.6935361388961918
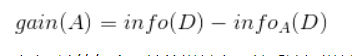
play的信息熵为:0.9402859586706311
outlook= play - outlook
outlook = 0.9402859586706311 - 0.6935361388961918
0.24674981977443933
这个结果叫做 !! 熵增益
也就是说你加了一个条件消除了不确定性
这个值越大说明你加入的条件消除的不确定性越高
因此我们需要找出所有的列的熵增益将最高的作为 !! 根节点
"""
{'city': '北京','pos':'北方','temp': 100},
{'city': '上海','pos':'南方','temp':60},
{'city': '深圳','pos':'南方','temp': 30},
{'city': '重庆','pos':'西方','temp': 70}
"""
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
import numpy as np
df = pd.read_csv('dtree.csv')
#one-hot 独热编码
# datas = np.array([{'city': '北京','pos':'北方','temp': 100},
# {'city': '上海','pos':'南方','temp':60},
# {'city': '深圳','pos':'南方','temp': 30},
# {'city': '重庆','pos':'西方','temp': 70}])
#
# dict_vect = DictVectorizer(sparse=False)
# data_dict = dict_vect.fit_transform(datas)
# print(dict_vect.feature_names_)
# print(data_dict)
#print(df)
#{'Outlook': 'sunny', 'Temperature': 85, 'Humidity': 85, 'Windy': False}
#将datafrme转换为字典格式
datas = df.loc[:,["Outlook","Temperature","Humidity","Windy"]].to_dict(orient="record")
target = df.loc[:,["Play"]].to_dict(orient="record")
#数据向量化器
data_vector = DictVectorizer(sparse=False)
train_data = data_vector.fit_transform(datas)
#target向量化器
target_vector = DictVectorizer(sparse=False)
target_data = target_vector.fit_transform(target)
#构建决策树模型
dt = DecisionTreeClassifier()
dt.fit(train_data,target_data)
print(data_vector.feature_names_)
print("特征重要性",dt.feature_importances_)
#应用模型
# sample = {'Outlook': 'ranny', 'Temperature': 65, 'Humidity': 90, 'Windy': True}
# sample_vector = data_vector.transform(sample)
#
# print("预测结果是:::",target_vector.inverse_transform(dt.predict(sample_vector)))
决策树的分裂
- ID3
- C4.5
- CART

















 2482
2482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









