







使用python进行描述统计:单变量
3-1-1统计分析与scipy
import scipy as sp
3-1-2单变量的操作
只有一种类型的数据
import scipy as sp
import numpy as np
fish_data = np.array([2,3,3,4,4,4,4,5,5,6])
print(fish_data)
#[2 3 3 4 4 4 4 5 5 6]
3-1-3总和与样本容量
计算数据总和
同时sp.num()被np.sum()代替
print(sp.sum(fish_data))#40
#DeprecationWarning: scipy.sum is deprecated and will be removed in SciPy 2.0.0, use numpy.sum instead
print(np.sum(fish_data))#40
求样本容量
N = len(fish_data)
print(N)#10
3-1-4均值(期望值)
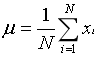
N = len(fish_data)
sum_value = np.sum(fish_data)
mu = sum_value / N
print(mu)#4.0
print(np.mean(fish_data))#4.0快速求平均值
#DeprecationWarning: scipy.mean is deprecated and will be removed in SciPy 2.0.0, use numpy.mean instead
3-1-5协方差
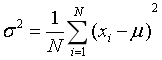
方差用来表示数据距离均值有多远
参考期望mu
sigma_2_sample = np.sum((fish_data - mu) ** 2)/N
print(sigma_2_sample)#1.2
3-1-6无偏方差

样本方差是利用样本均值计算而来的,这个结果存在偏差,过小地推断了总体方差,无偏方差比样本方差较大。
class 类名:
sigma_2 = np.sum((fish_data - mu) ** 2)/(N-1)
print(sigma_2)#1.3333333333333333
使用np.var()将参数ddof设为1,也可得出无偏方差
print(np.var(fish_data,ddof = 1))#1.3333333333333333
3-1-7标准差
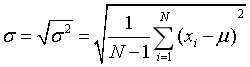
print(np.sqrt(sigma_2))#1.1547005383792515
3-1-8标准化
标准化就是把均值化为0,把标准差(方差)化为1.均值不相等的随机变量放在一起很难把握其特征,所以先进行标准化。
要使均值为0,只需要用所有样本减去均值即可,
print(fish_data-mu)#[-2. -1. -1. 0. 0. 0. 0. 1. 1. 2.]
print(np.mean(fish_data-mu))#0.0
使得数据的标准差为1,所有样本除于标准差
np.std(arr) 将输入数组视为扁平化数组,并计算这个一维扁平化数组的标准差。 np.std(arr, axis=0) 计算沿列的标准差。
但是想要正确调用np.std()标准差函数,必须使ddof=1:
sigma = np.sqrt(sigma_2)
print(fish_data/sigma)
#[1.73205081 2.59807621 2.59807621 3.46410162 3.46410162 3.46410162
# 3.46410162 4.33012702 4.33012702 5.19615242]
#标准差是1
print(np.std(fish_data/sigma,ddof = 1))#1.0
#不适用ddof的标准差函数
print(np.std(fish_data/sigma))#0.9486832980505138
综合
standard = (fish_data-mu)/sigma
print(standard)
# [-1.73205081 -0.8660254 -0.8660254 0. 0. 0.
# 0. 0.8660254 0.8660254 1.73205081]
sigma = np.sqrt(sigma_2)
standard = (fish_data - mu)/sigma
print(np.mean(standard))#2.2204460492503132e-17
#2.2204460492503132e-17数字极小,可以看似为0
print(np.std(standard,ddof=1))#1.0
3-1-9其他统计量
最大值
print(sp.amax(fish_data))#6
#DeprecationWarning: scipy.amax is deprecated and will be removed in SciPy 2.0.0, use numpy.amax instead
最小值
print(np.amin(fish_data))#2
中位数
数据升序排列,位置在最中间的数就是中位数
print(np.median(fish_data))#4.0
中位数对于极端值更有稳健性
3-1-10scipy.stats与四分位数
导入用于统计分析函数
from scipy import stats
将数据按升序排列,处在25%和75%位置的数就是四分位数
from scipy import stats
fish_data_3 = np.array([1,2,3,4,5,6,7,8,9])
print(stats.scoreatpercentile(fish_data_3, 25))#3.0
print(stats.scoreatpercentile(fish_data_3, 75))#7.0
参考资料
[日] 马场真哉 著, 吴昊天 译. 用Python动手学统计学[M]. 1. 人民邮电出版社, 2021-06-01.
菜鸟网站python3
基于python 3.9,使用pycharm community实现,本人水平非常菜,想要开始学习知识。
内容基于这本书和一些网上资料如菜鸟网站等进行补充
数学公式使用mathtype


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









