







 本文详细介绍Elasticsearch的安装配置及使用方法,包括增删改查、分词器配置、简单及复杂搜索技巧等内容。
本文详细介绍Elasticsearch的安装配置及使用方法,包括增删改查、分词器配置、简单及复杂搜索技巧等内容。
文章目录
ElasticSearch
一、安装
安装前最好更新一下npm:
npm install -g npm
同时,要求jdk版本 >= 1.8
1、es 安装
我选择的是7.8.1版本,在官网下载自己需要的版本即可:
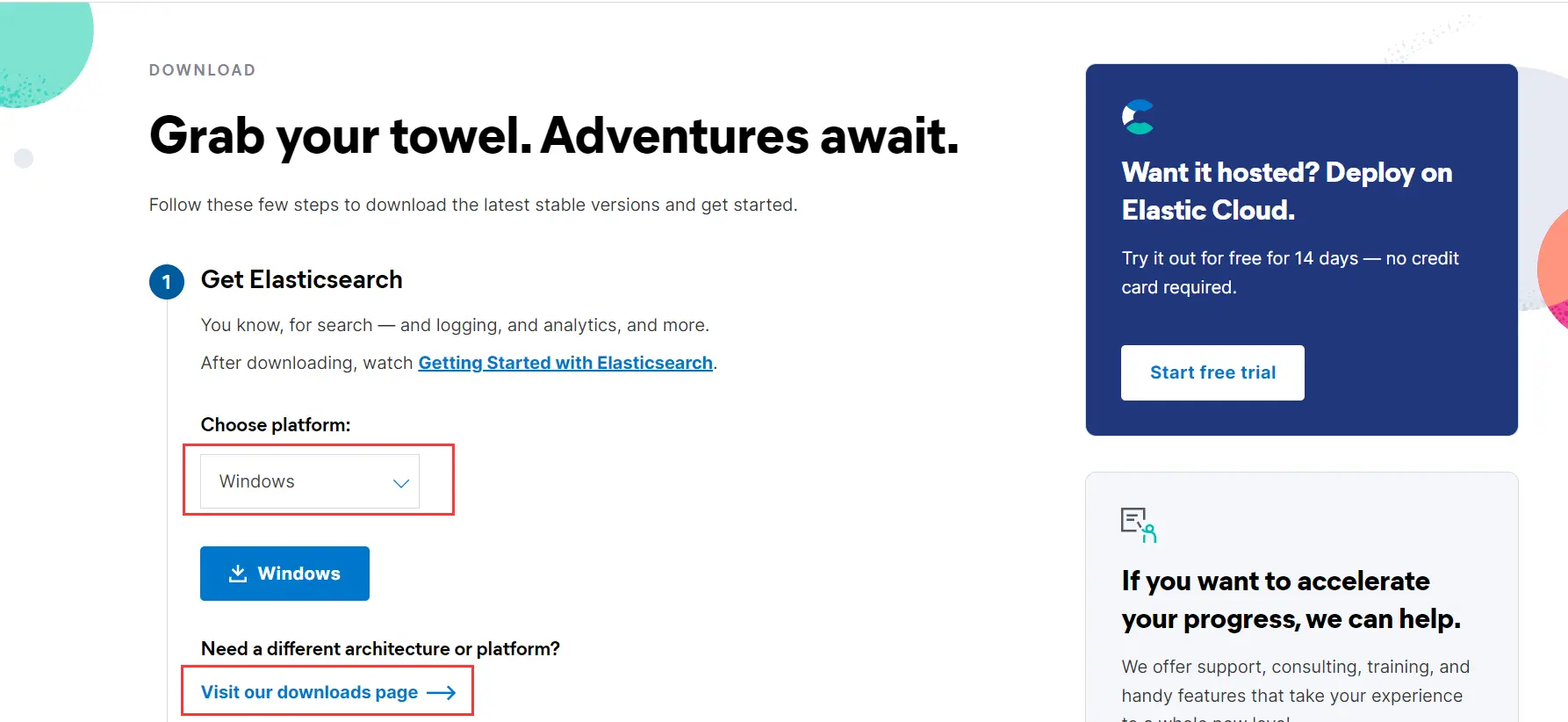
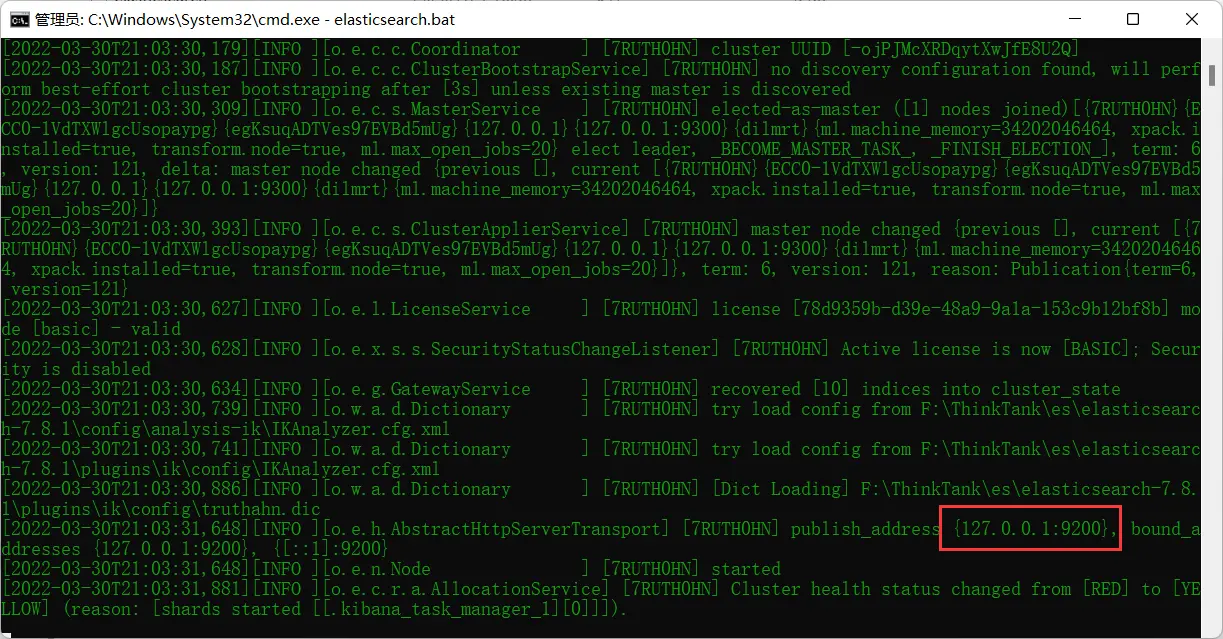
下载完解压,在bin目录下双击elasticsearch.bat,等待一会,会出现9200端口,即es运行的端口:
我们访问网站,若成功显示如下信息,则表示启动成功:
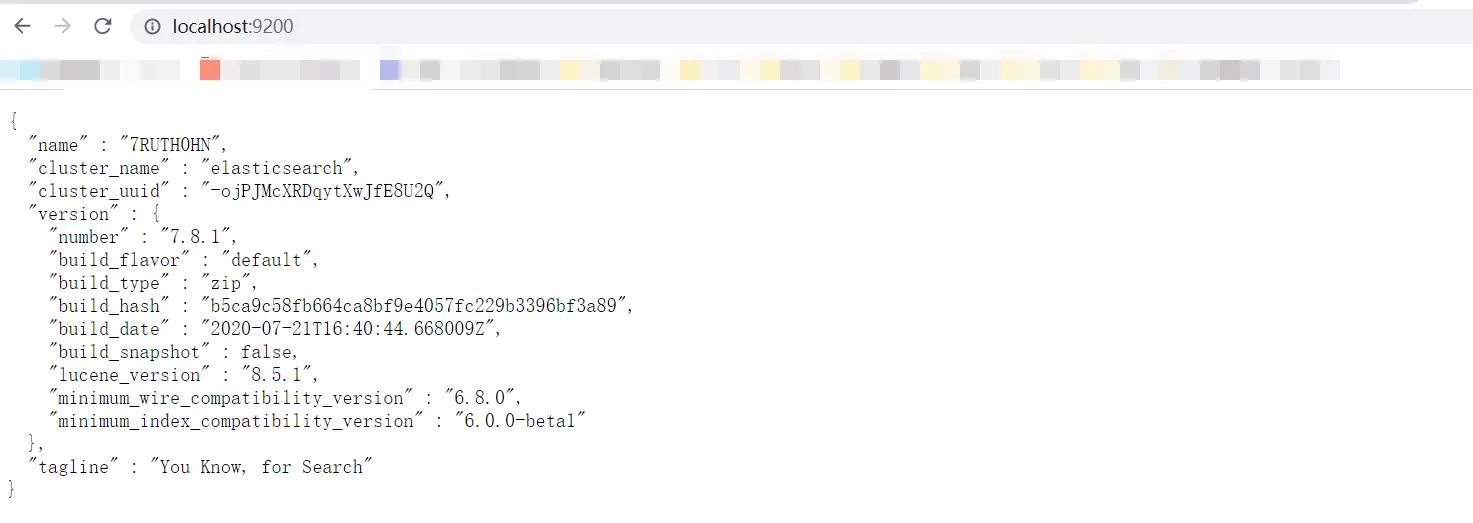
出现了,“You Know, for Search”。
接下来解决跨域问题:
在es的config目录下,我们编辑elasticsearch.yml:
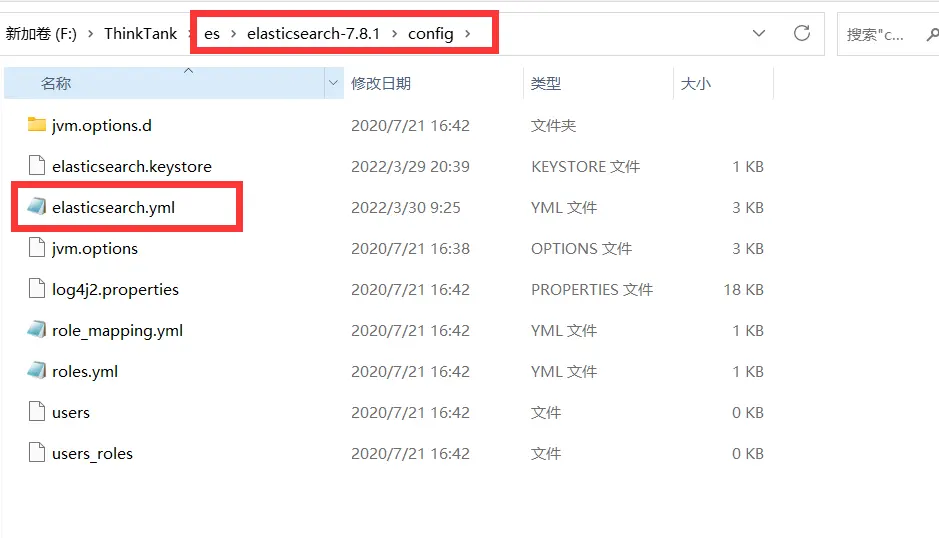
在最后添加这两句:
http.cors.enabled: true
http.cors.allow-origin: "*"
然后重启es即可。
2、es-head 安装
es-head可以与es建立连接,即时查看es相关信息。
最简单的方法是在chrome的商店里添加elastcisearch-head
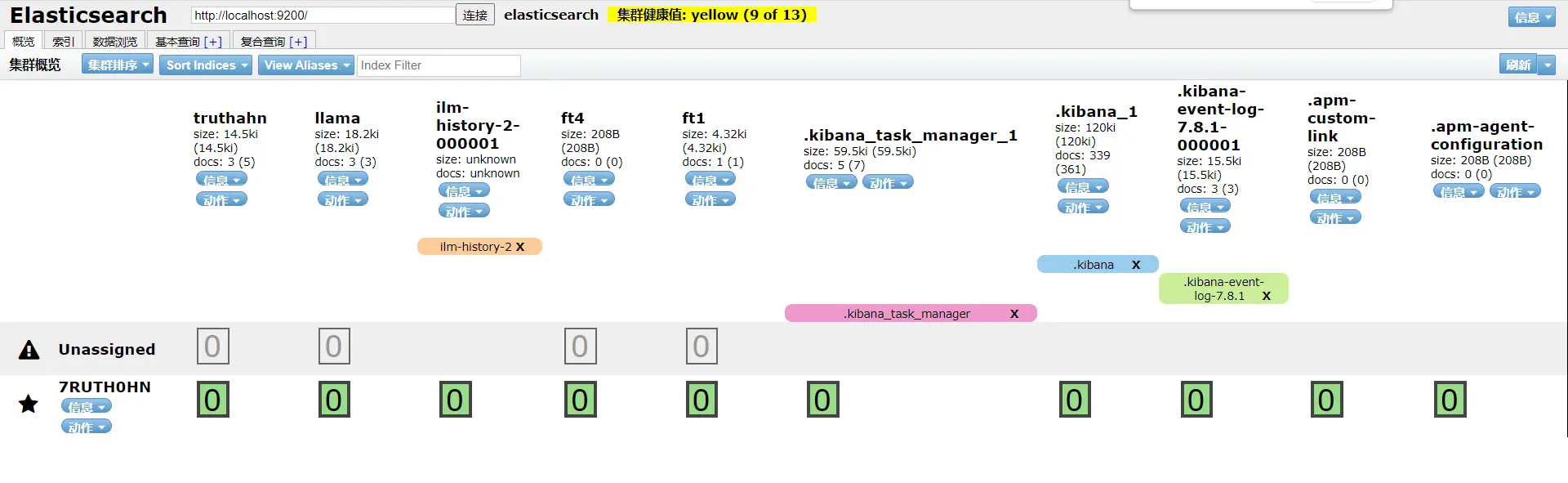
与es连接后大概是这样(我之前已经创建了一些索引):
也可以在github上下载对应版本的release,下载解压后按照readme的步骤安装启动即可,默认使用的端口为9100
3、Kibana 安装
Kibana是es配套的可视化工程模块。
注意要选择对应版本的Kibana:
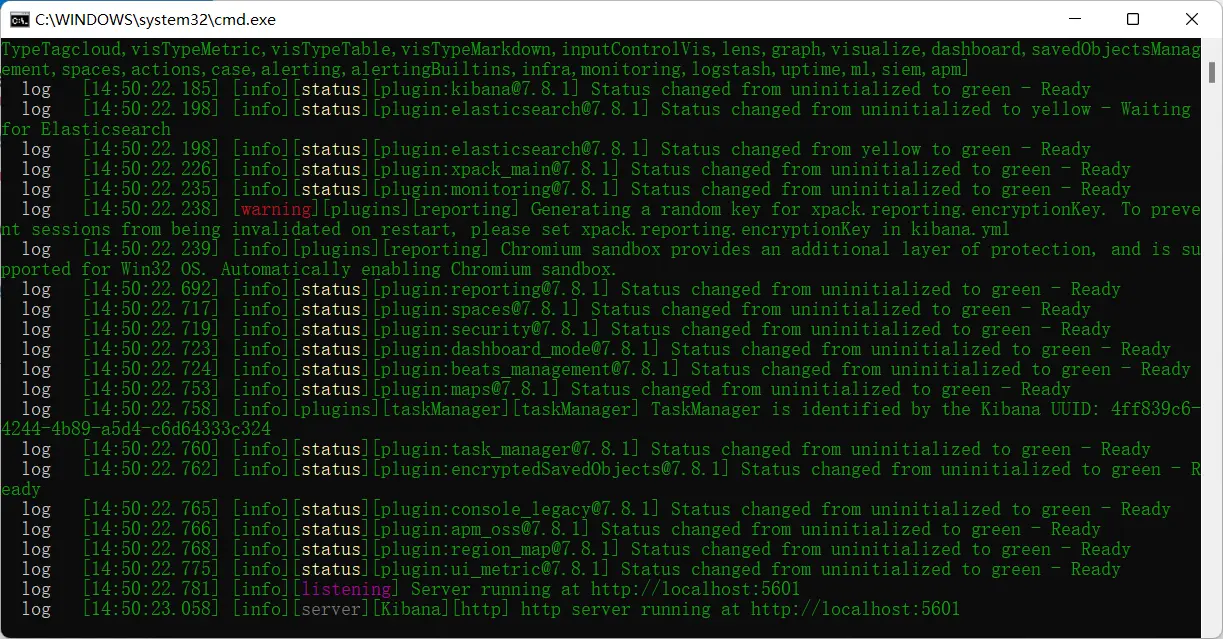
下载解压后,在对应的bin目录下,运行kibana.bat。等待一段时间(有warning不用管),出现5601端口:
我们访问网站,出现如下界面即代表启动成功
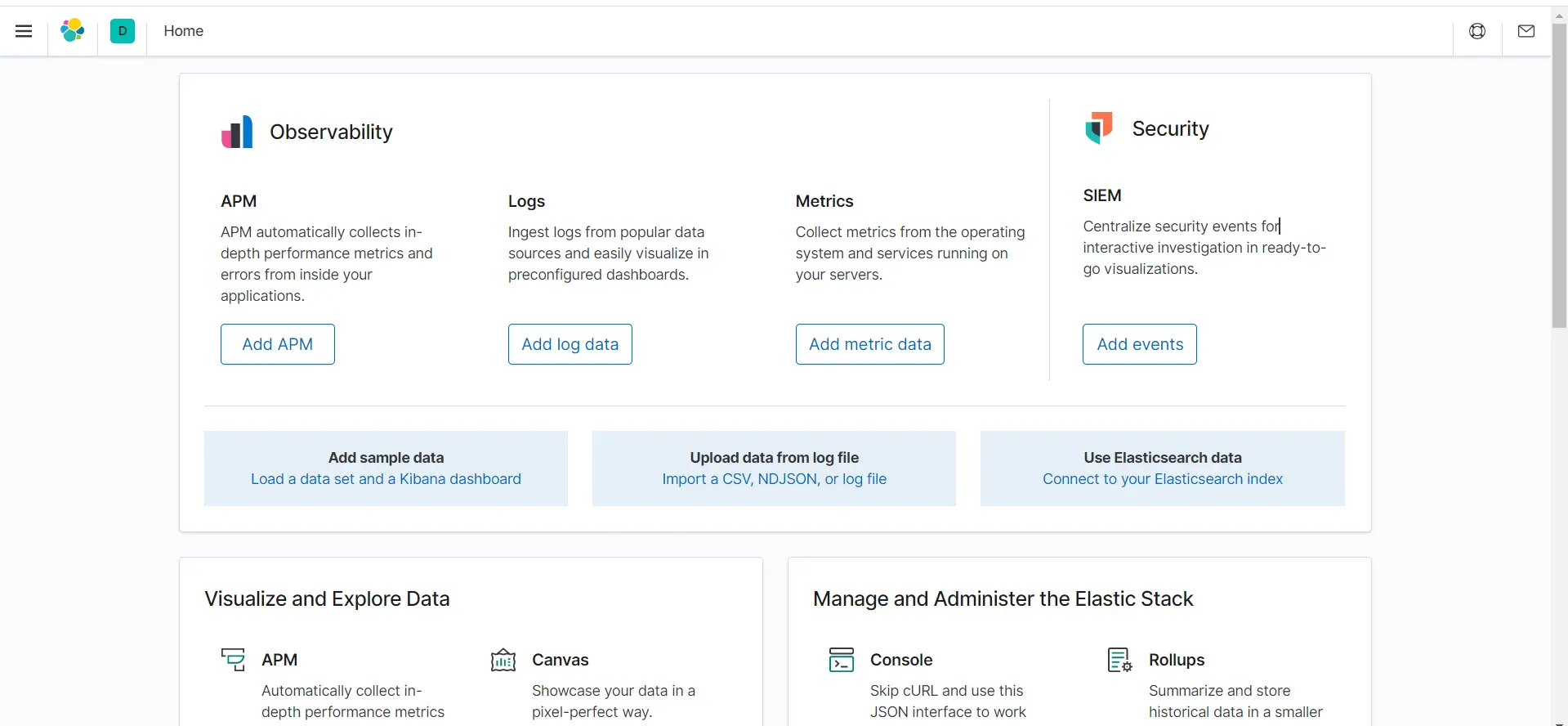
右下角的console则是我们学习es主要使用的工具
4、es-analysis-ik 插件安装
es-analysis-ik为es扩展的分词器。
现在es安装目录的plugins目录下新建一个名为 ik 的文件夹,然后在github上下载对应版本的release,将下载的zip解压到我们新建的文件夹内即可。
重启es,可以在终端看到 ik 被启用:

二、使用
1、analysis-ik 的使用和配置
- 配置
a.ik分词器增加字典条目
在es主目录的plugins/ik/config目录下:
我们可以更改IKAnalyzer.cfg.xml文件来增加自定义字典(这里添加的扩展字典为我们自己创建的文件:truthahn.dic):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">truthahn.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 使用
es-analysis-ik分词器有ik_smart(最粗粒度拆分)和ik_max_word(最细粒度拆分)两种模式。示例:
进入Kibana的console界面,
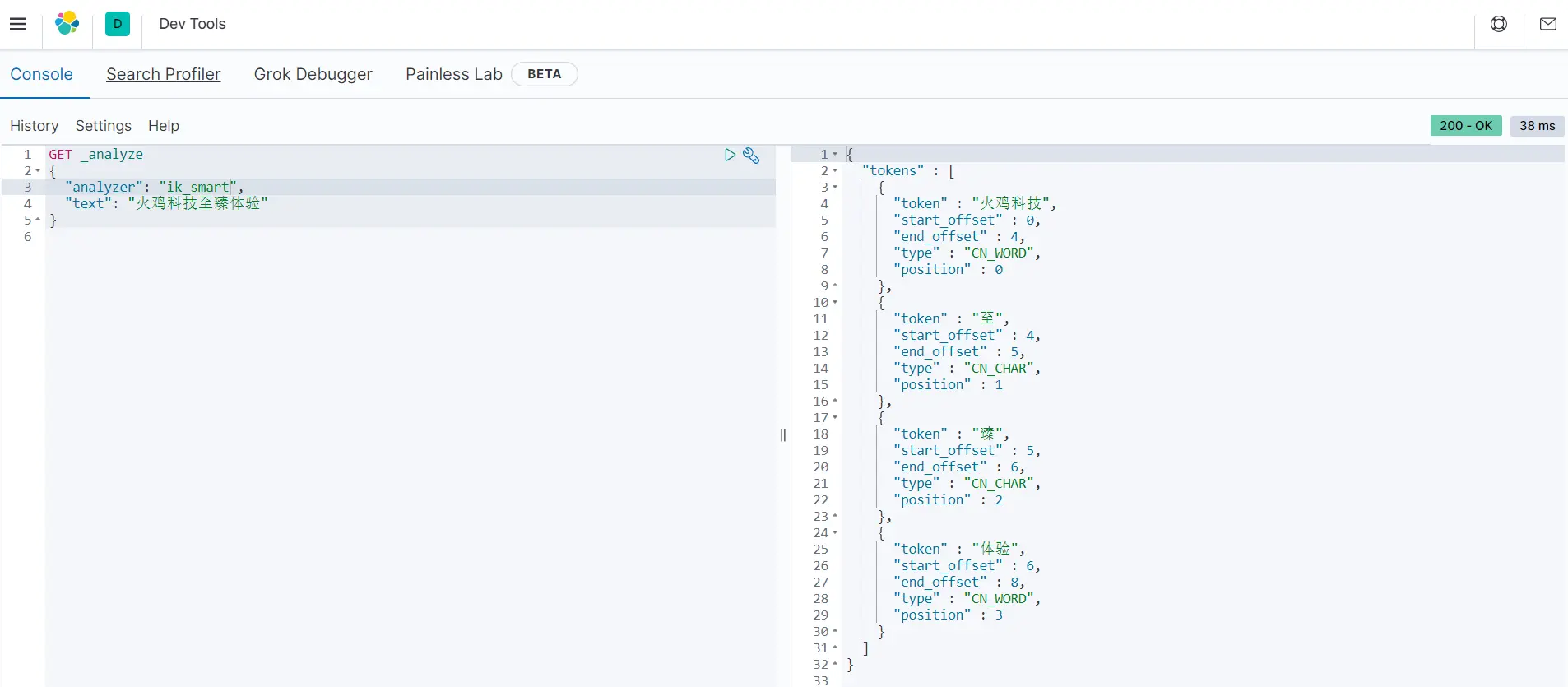
ik_smart:
GET _analyze
{
"analyzer": "ik_smart",
"text": "火鸡科技至臻体验"
}
ik_max_word:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "火鸡科技至臻体验"
}
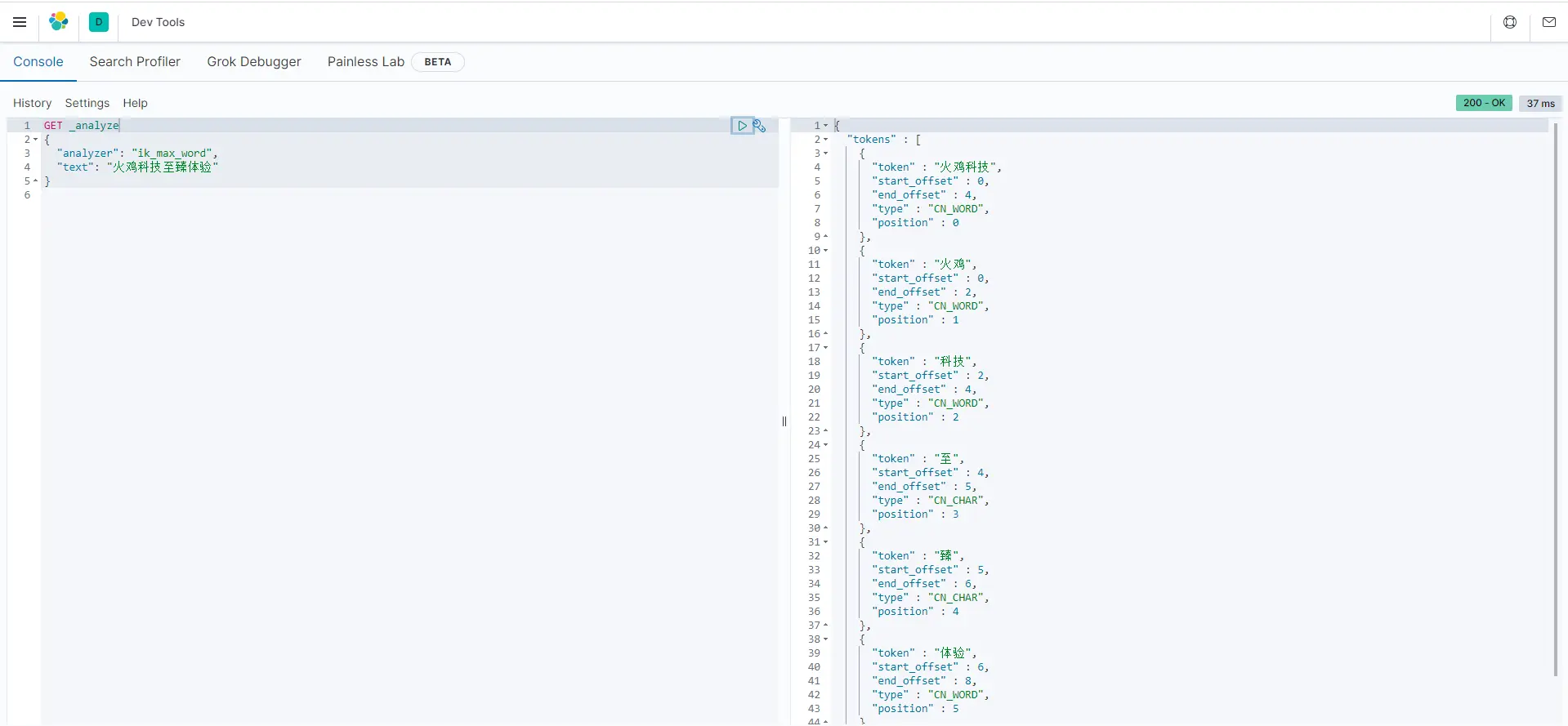
由于我们之前添加的truthahn.dic字典中有“火鸡科技”的条目,若没有添加,ik分词器只会识别出“火鸡”和“科技”。
可以看出,相较于ik_smart,ik_max_word会将字典定义的名词进行进一步的拆分。
2、四大操作:增删改查
- 前置知识:
ES五种method:
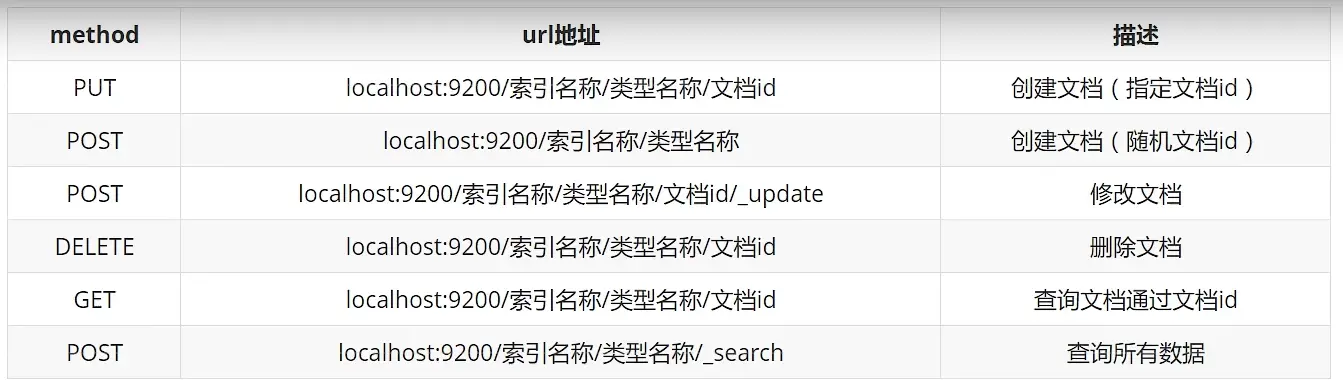
ES类型:

- PUT:
进入Kibana的console界面,创建索引:
PUT /ft1/type1/1
{
"name": "火鸡科技",
"text": "火鸡科技至臻体验"
}
注意:type类型已经逐渐被丢弃,可以将上面的type1更改为:_doc
PUT /索引名/_doc/文档ID
{请求体}
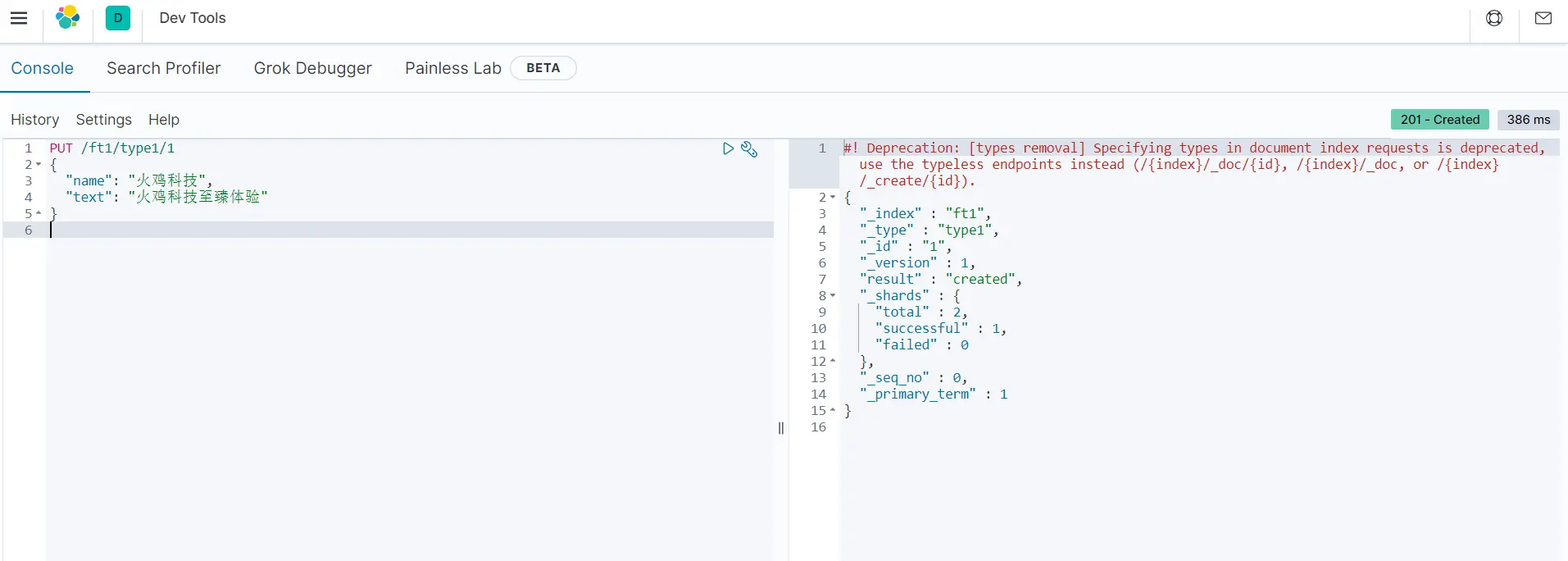
在es-head中可以看到索引创建成功并且写入了数据:
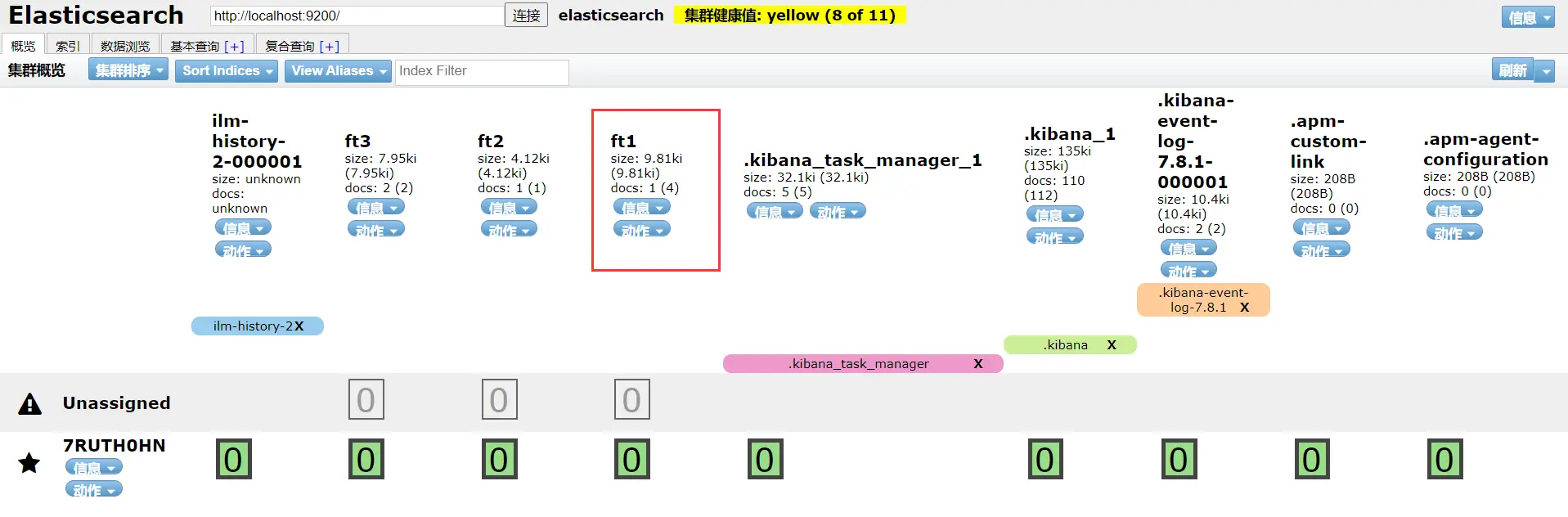
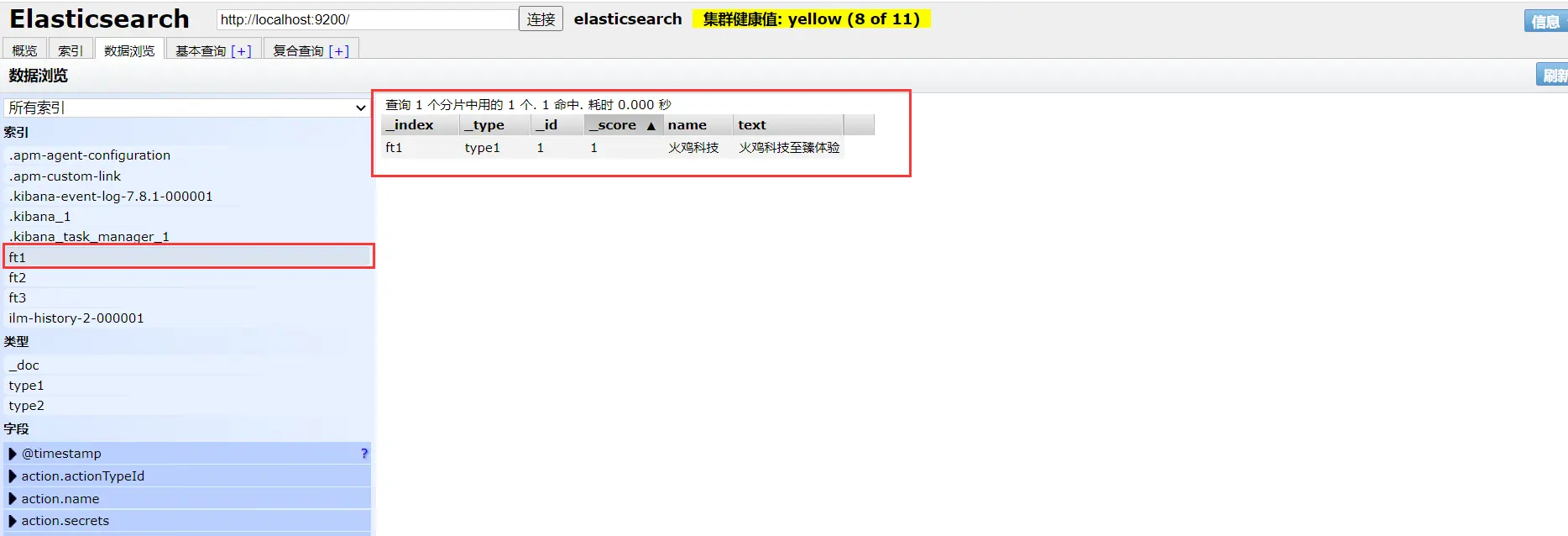
具体内容:
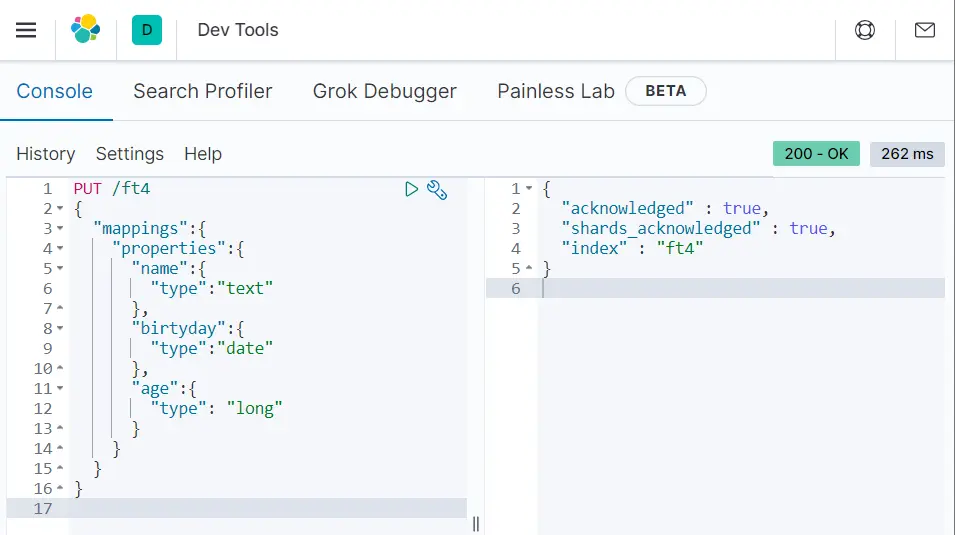
同时,我们也可以使用mapping设置索引的一些数据的类型:
PUT /ft4
{
"mappings":{
"properties":{
"name":{
"type":"text"
},
"birtyday":{
"type":"date"
},
"age":{
"type": "long"
}
}
}
}
- DELETE:
删除索引
DELETE ft2
- POST:
更新索引:
POST /ft1/_update/1/
{
"doc":{
"name":"火鸡PLUS+"
}
}
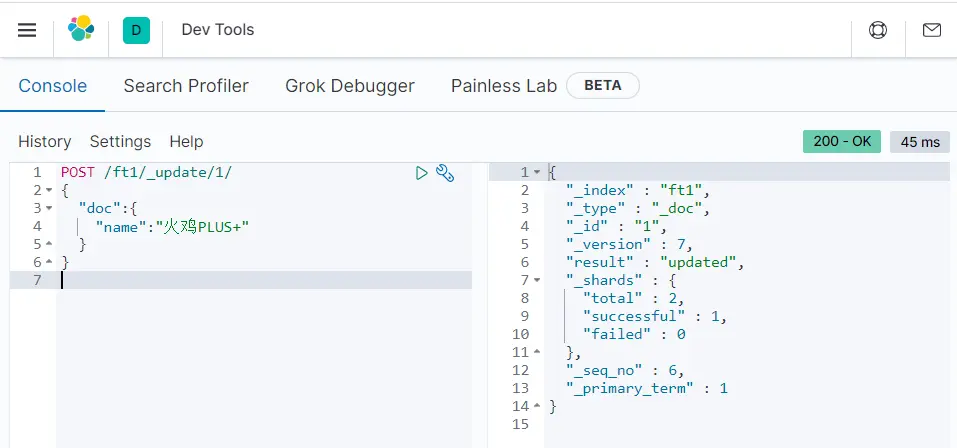
可以看到,更新时索引ft1的_version会递增,同时result返回的也是updated
- GET:
获取索引规则信息
GET ft1
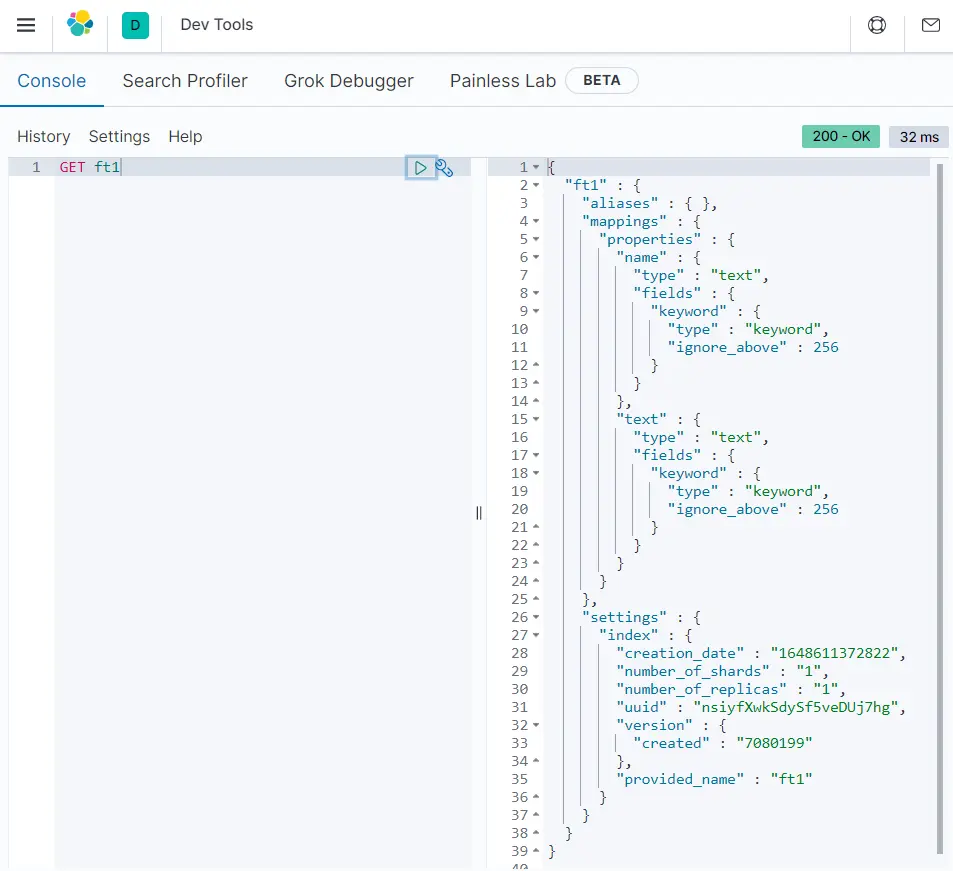
另外,可以用GET _cat/获取es的其他信息:
GET _cat/health
GET _cat/master
GET _cat/aliases
GET _cat/count
GET _cat/indices
3、简单搜索
我们先创建一系列索引:
PUT /truthahn/_doc/1
{
"title":"荷塘月色",
"author":"朱自清",
"text":"这几天心里颇不宁静。今晚在院子里坐着乘凉,忽然想起日日走过的荷塘,在这满月的光里,总该另有一番样子吧。月亮渐渐地升高了,墙外马路上孩子们的欢笑,已经听不见了;妻在屋里拍着闰儿,迷迷糊糊地哼着眠歌。我悄悄地披了大衫,带上门出去。沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。今晚却很好,虽然月光也还是淡淡的。"
}
PUT /truthahn/_doc/2
{
"title":"背影",
"author":"朱自清",
"text":"我与父亲不相见已二年余了,我最不能忘记的是他的背影。那年冬天,祖母死了,父亲的差使也交卸了,正是祸不单行的日子。我从北京到徐州,打算跟着父亲奔丧回家。到徐州见着父亲,看见满院狼藉的东西,又想起祖母,不禁簌簌地流下眼泪。父亲说,“事已如此,不必难过,好在天无绝人之路!”回家变卖典质,父亲还了亏空;又借钱办了丧事。这些日子,家中光景很是惨淡,一半为了丧事,一半为了父亲赋闲。丧事完毕,父亲要到南京谋事,我也要回北京念书,我们便同行。"
}
PUT /truthahn/_doc/3
{
"title":"曲院风荷",
"author":"陈璨",
"text":"六月荷花香满湖,红衣绿扇映清波。木兰舟上如花女,采得莲房爱子多。"
}
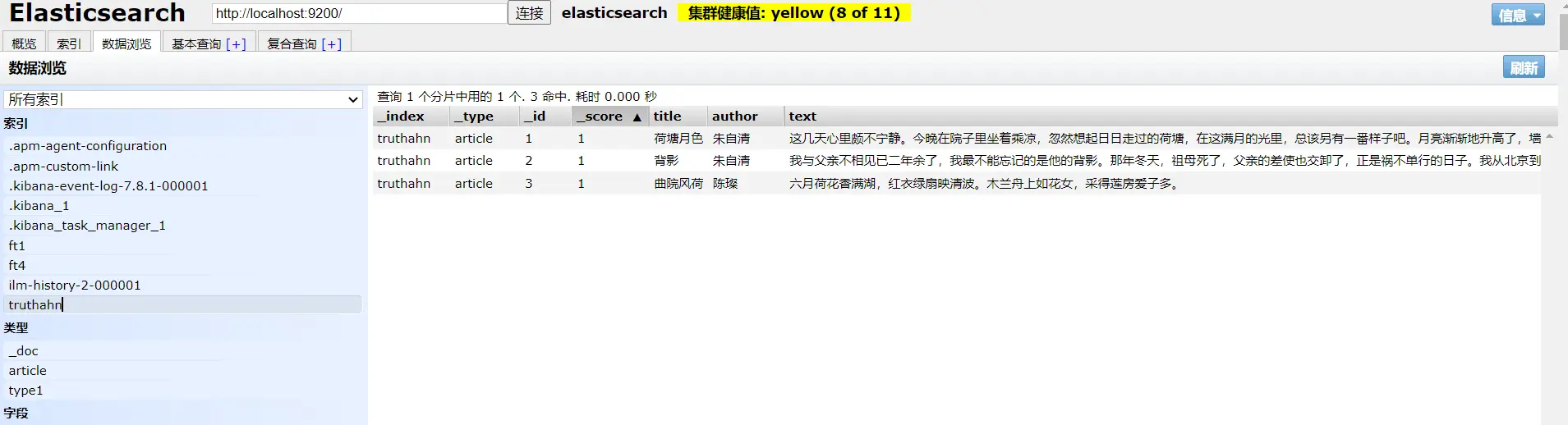
然后我们可以开始简单的搜索:
GET /truthahn/_search?q=title:荷塘月色
结果:
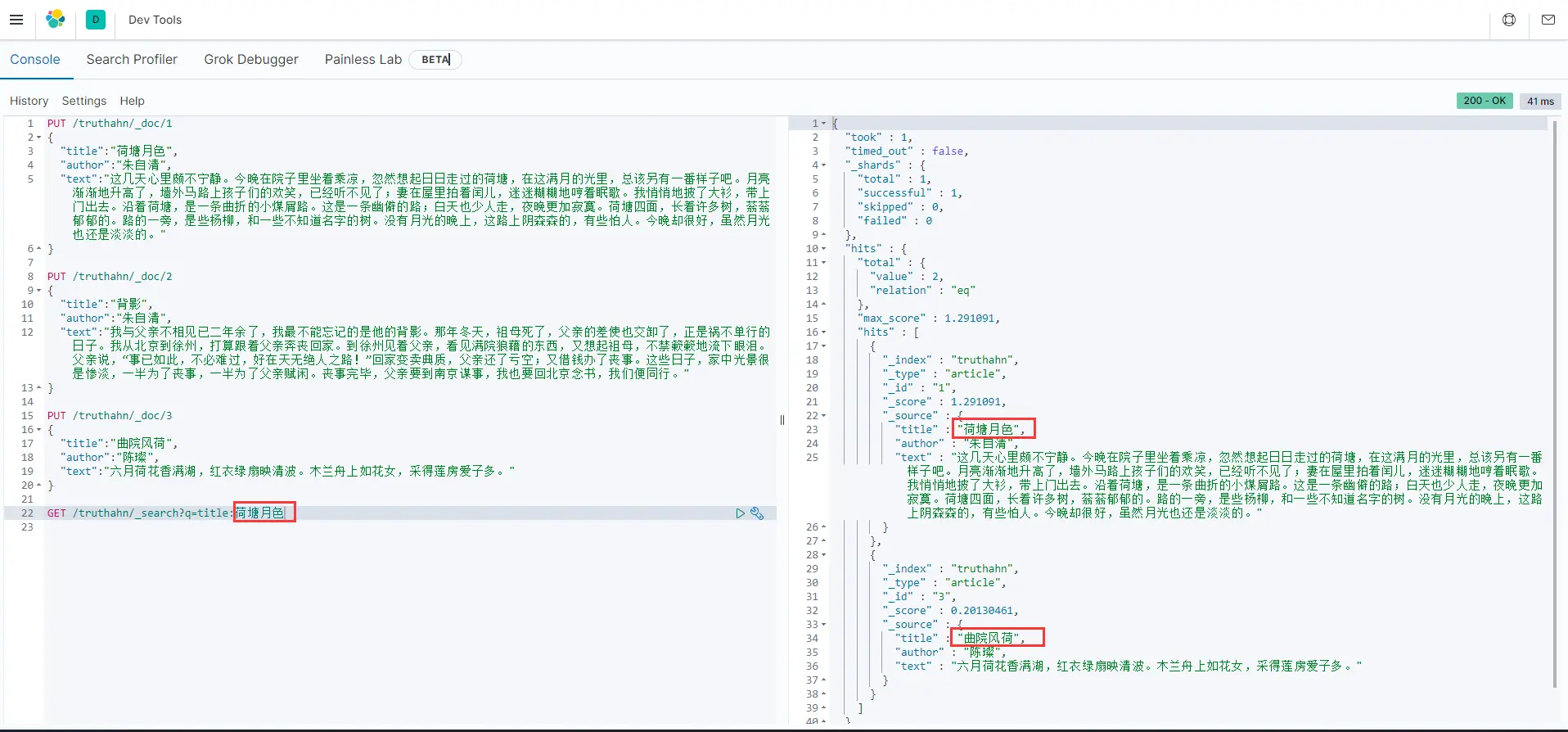
发现title中包含关键字“荷”的索引都被查询到了(PS:十分推荐朱良志教授的《曲院风荷》);
如果搜索“月光”,会发现三个索引同时被查询到:
GET /truthahn/_search?q=text:月光
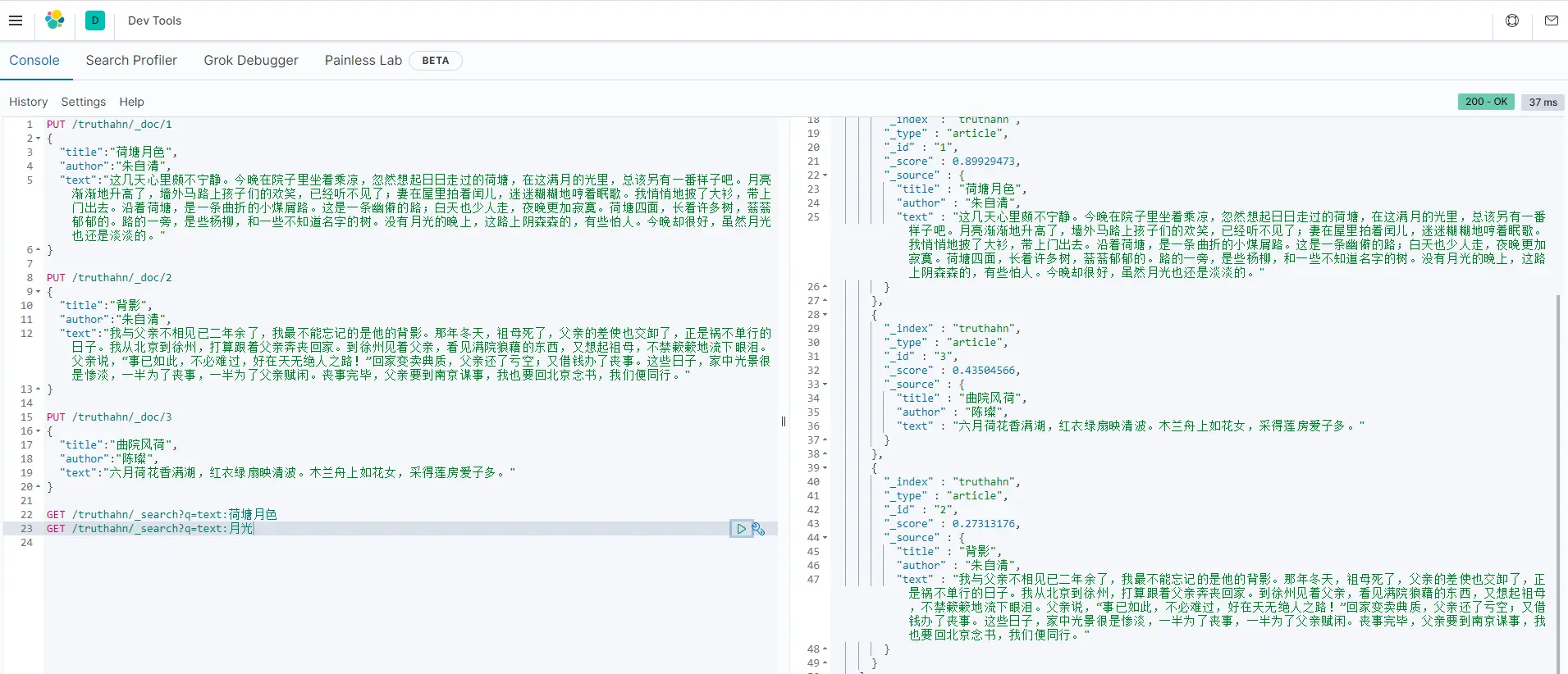
这是因为上述字段text的类型为text(es会自动识别数据的类型),所以es会对数据使用分词器进行分词,只要包含关键字的一部分即可匹配,同时,我们看到返回的结果中有 _score 字段,"_score"的值越高,则数据与关键字的匹配度越高。
而当我们将对应数据的类型更改为keyword时,es会对keyword类型的数据进行完全匹配:
创建新的索引,所有数据的类型都为keyword:
PUT /llama
{
"mappings":{
"properties": {
"title":{
"type":"keyword"
},
"author":{
"type": "keyword"
},
"text":{
"type": "keyword"
}
}
}
}
PUT /llama/_doc/1
{
"title":"荷塘月色",
"author":"朱自清",
"text":"这几天心里颇不宁静。今晚在院子里坐着乘凉,忽然想起日日走过的荷塘,在这满月的光里,总该另有一番样子吧。月亮渐渐地升高了,墙外马路上孩子们的欢笑,已经听不见了;妻在屋里拍着闰儿,迷迷糊糊地哼着眠歌。我悄悄地披了大衫,带上门出去。沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。今晚却很好,虽然月光也还是淡淡的。"
}
PUT /llama/_doc/2
{
"title":"背影",
"author":"朱自清",
"text":"我与父亲不相见已二年余了,我最不能忘记的是他的背影。那年冬天,祖母死了,父亲的差使也交卸了,正是祸不单行的日子。我从北京到徐州,打算跟着父亲奔丧回家。到徐州见着父亲,看见满院狼藉的东西,又想起祖母,不禁簌簌地流下眼泪。父亲说,“事已如此,不必难过,好在天无绝人之路!”回家变卖典质,父亲还了亏空;又借钱办了丧事。这些日子,家中光景很是惨淡,一半为了丧事,一半为了父亲赋闲。丧事完毕,父亲要到南京谋事,我也要回北京念书,我们便同行。"
}
PUT /llama/_doc/3
{
"title":"曲院风荷",
"author":"陈璨",
"text":"六月荷花香满湖,红衣绿扇映清波。木兰舟上如花女,采得莲房爱子多。"
}
truthahn和llama的索引信息:
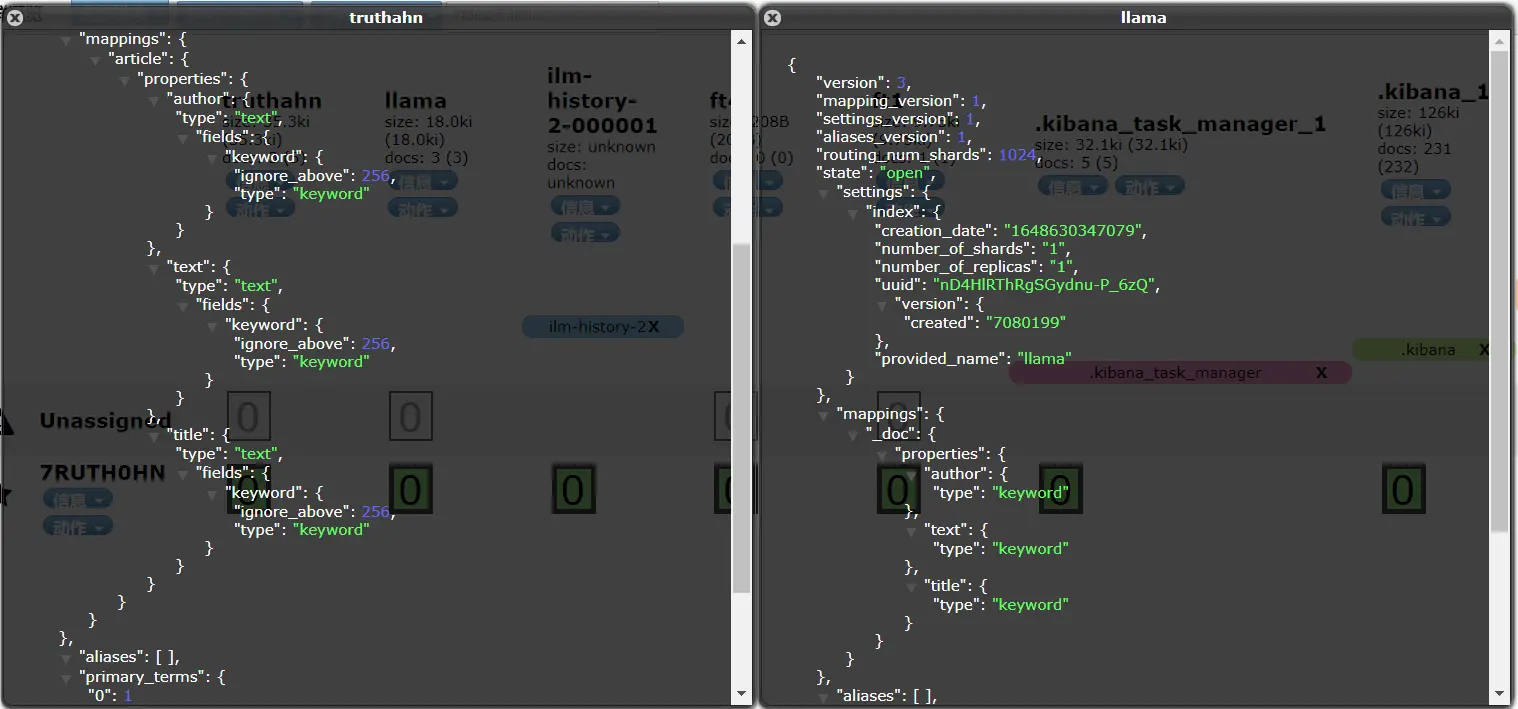
当执行
GET /truthahn/_search?q=title:荷塘月色
GET /llama/_search?q=title:荷塘月色
时前者返回结果中value为2,而后者则为1
当执行
GET /truthahn/_search?q=text:荷塘月色
GET /llama/_search?q=text:荷塘月色
时前者返回结果中value为2,而后者则为0
我们也可以通过设置分词器的类型来验证:
keyword类型:
GET _analyze
{
"analyzer":"keyword",
"text":"火鸡科技 至臻体验"
}
结果:
{
"tokens" : [
{
"token" : "火鸡科技 至臻体验",
"start_offset" : 0,
"end_offset" : 9,
"type" : "word",
"position" : 0
}
]
}
standard类型:
GET _analyze
{
"analyzer":"standard",
"text":"火鸡科技至臻体验"
}
结果:
{
"tokens" : [
{
"token" : "火",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "鸡",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "科",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "技",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "至",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "臻",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "体",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "验",
"start_offset" : 7,
"end_offset" : 8,
"type" : "<IDEOGRAPHIC>",
"position" : 7
}
]
4、复杂搜索
还是使用上面创建的索引truthahn的数据,进行复杂搜索:
- match
GET /truthahn/_search
{
"query": {
"match": {
"text": "月光"
}
},
"_source": ["text"]
}
这里的match与
GET /truthahn/_search?q=月光
的规则类似。都是模糊匹配,会先把查询条件进行分词,然后逐个查询。
不同的是"_source"用来规定返回哪些字段,
"_source": ["text"]
说明只返回text字段,而author和name则不返回
- term
与match相反,term为完全匹配,要求必须包含全部的term字段:
GET /truthahn/_search
{
"query": {
"term": {
"text": "月光"
}
}
}
结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
这是因为term默认使用标准分词器,这样原文就会被拆分成一个个单字,匹配不到“月光”。如果将条件改为:
"text": "月"
或
"text": "光"
就可以搜索到了。
- sort
GET /truthahn/_search
{
"query": {
"match": {
"text": "月光"
}
},
"_source": ["text"],
"sort": [
{
"text.keyword": {
"order": "asc"
}
}
]
}
添加“sort”规则,sort能够对返回的数据进行排序,此时返回的_score为null。
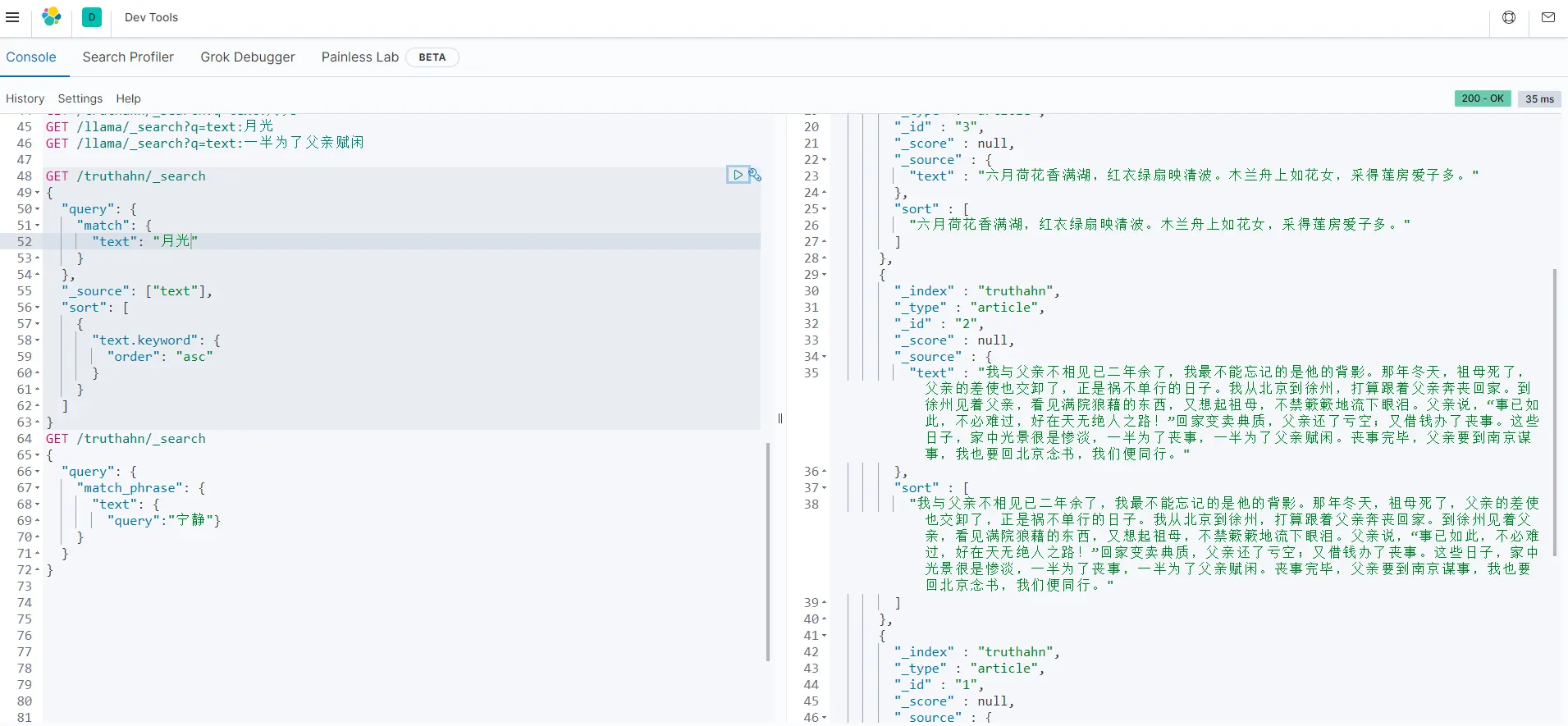
- from&size
GET /truthahn/_search
{
"query": {
"match": {
"text": "月光"
}
},
"_source": ["text"],
"sort": [
{
"text.keyword": {
"order": "asc"
}
}
],
"from":0,
"size":1
}
添加from和size规则,这两个规则规定返回结果的范围,可以理解成sql语句中的limit,
"from":0,
"size":1
能够获取返回的第一个结果,就类似于
select ... from ... where ... limit 0,1
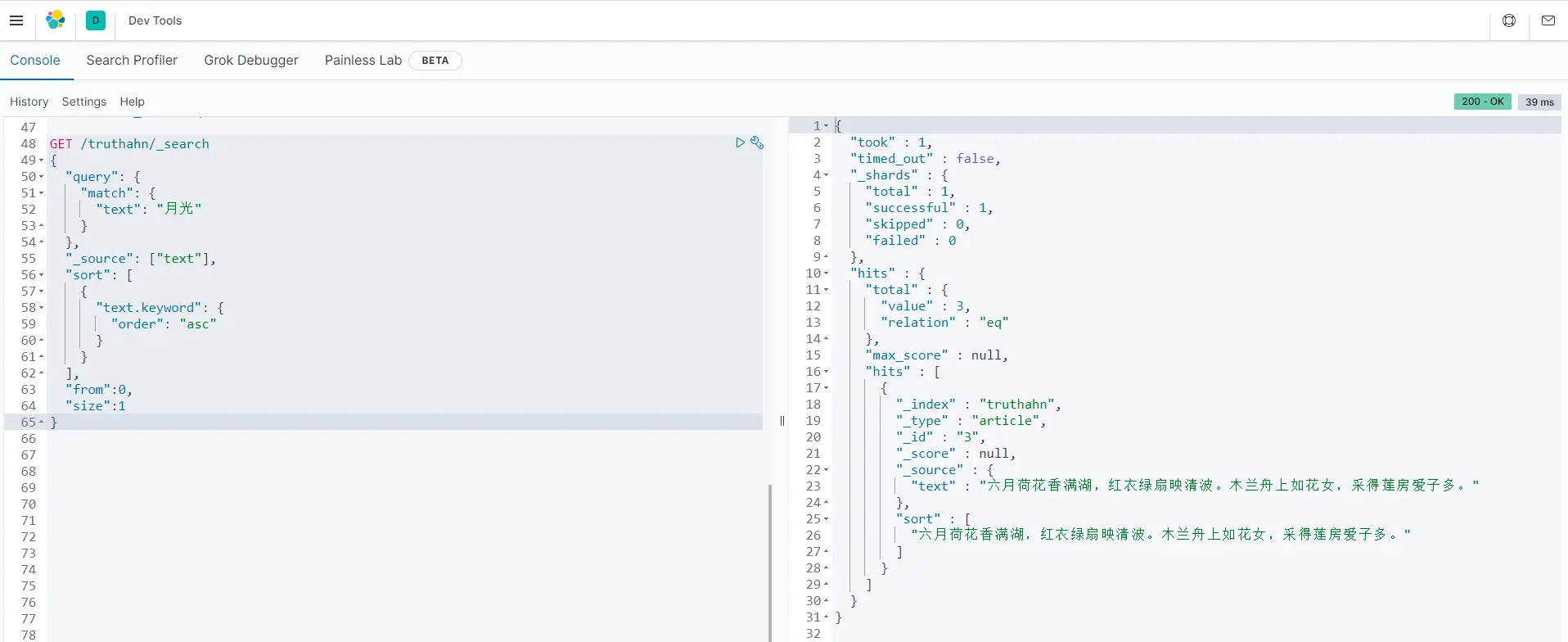
- bool
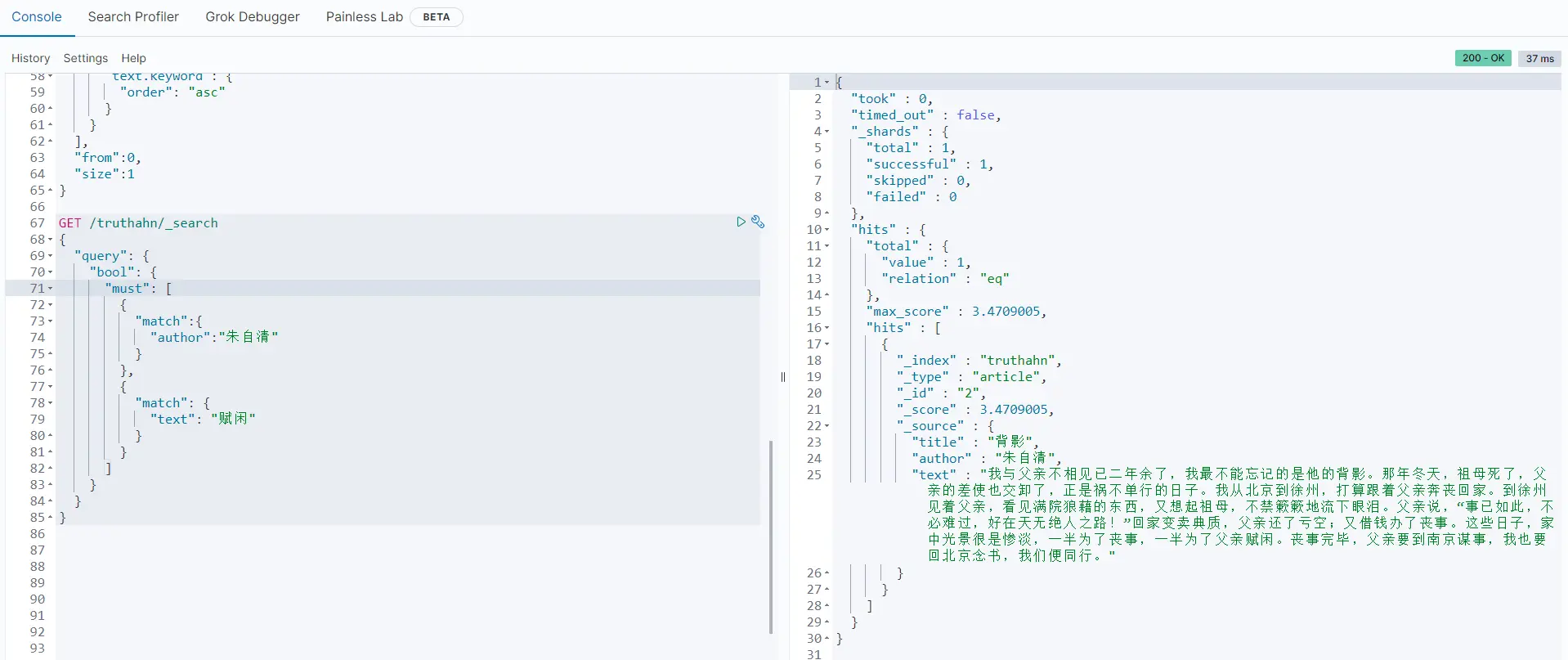
bool规则有must、must_not、should、boost、filter、mininum_should_match等判断逻辑,可以进行多条件查询:
must类似于and、且:
GET /truthahn/_search
{
"query": {
"bool": {
"must": [
{
"match":{
"author":"朱自清"
}
},
{
"match": {
"text": "赋闲"
}
}
]
}
}
}
should类似于or、或:
GET /truthahn/_search
{
"query": {
"bool": {
"should": [
{
"match":{
"author":"朱自清"
}
},
{
"match": {
"text": "赋闲 变卖"
}
}
]
}
}
}
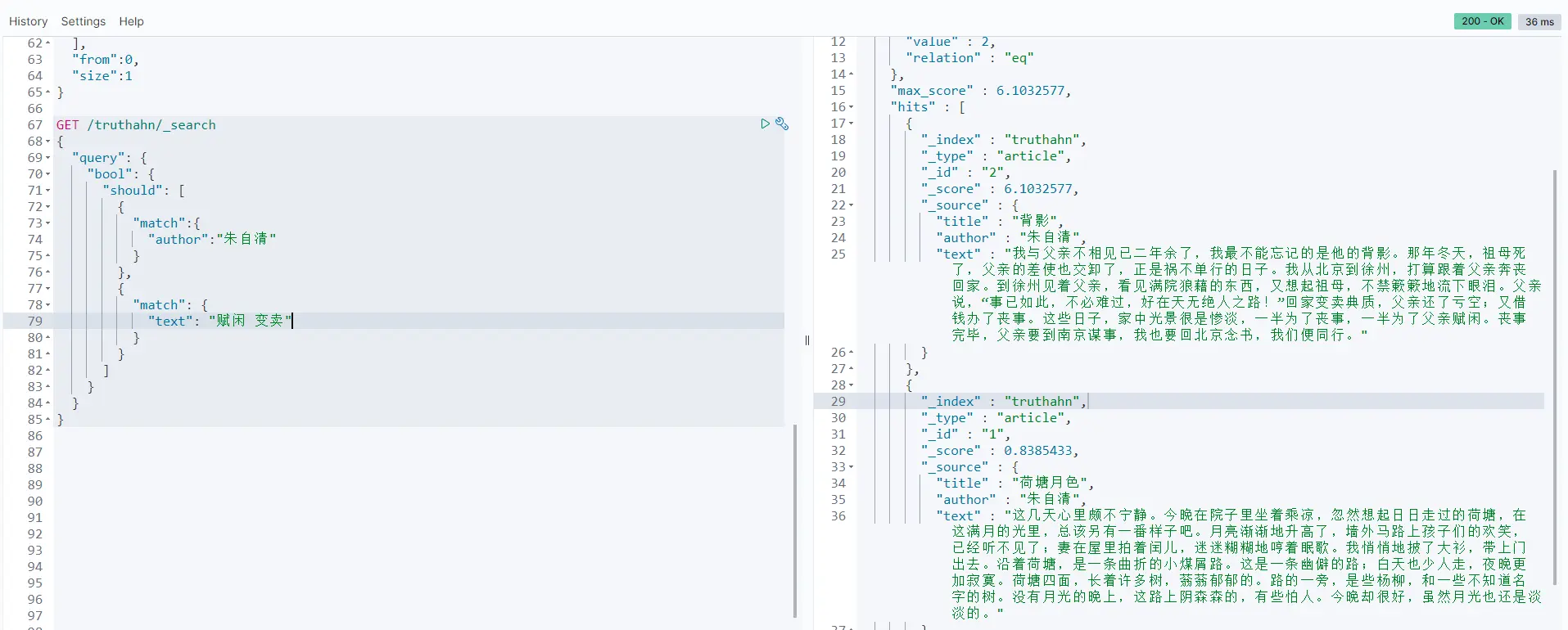
不知大伙有没有注意到,这里的match里可以用空格分隔查询多个条件,实现多条件查询。同时,虽然是should逻辑,但背影的_scroe为6.10,而荷塘月色只有0.83,说明更加匹配。
- highlight
GET /truthahn/_search
{
"query": {
"term": {
"text": "月"
}
},
"highlight": {
"fields": {
"title": {},
"author": {},
"text": {}
}
}
}

可以看到,满足条件的数据都添加了em标签
结语
好久没发博客了,有些写了一半没写完,就搁置了。这次由于工作需要,系统学习了elasticsearch,狂神讲得很好,收获满满。接下来会开始结合es进行相关前后端交互的开发。
感谢
全文搜索引擎 ElasticSearch 还是 Solr?
B站BV号:BV17a4y1x7zq


















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











