







 本文详细介绍KMP算法的匹配过程和next数组的计算,通过避免不必要的字符比较,提升字符串匹配的效率,从暴力O(nm)降低至O(n)。重点讲解如何利用next数组实现高效匹配,并给出了相关代码示例。
本文详细介绍KMP算法的匹配过程和next数组的计算,通过避免不必要的字符比较,提升字符串匹配的效率,从暴力O(nm)降低至O(n)。重点讲解如何利用next数组实现高效匹配,并给出了相关代码示例。
KMP算法的两部分
字符串匹配的暴力做法:
const int maxn=1e6+10;
char p[maxn],s[maxn]; //p为原串,s为模板串
for(int i=1;i<=m;i++){
bool flag=true;
for(int j=1;j<=n;j++){
if(p[i]!=s[j]) flag=false;
}
if(flag) cout<<i-j+1;
//输出匹配成功的串初始位置,p下标为0时不加1,下标1开始时加1;
}
时间复杂度为O(nm)当n,m大于10^4时程序将无法承受
那么如何降低时间复杂度就需要KMP算法进行优化了
KMP算法的两个部分
第一部分:KMP算法的匹配过程
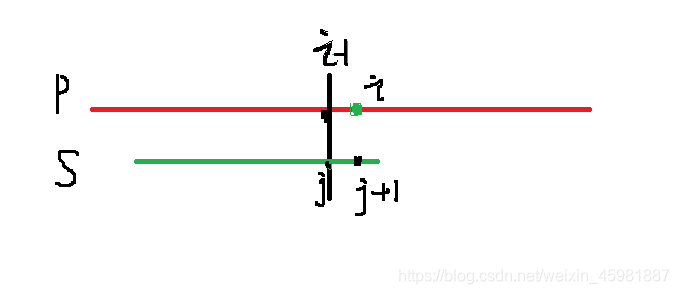
KMP算法的实质就是,省去不必要的匹配比较,当前位置字符不匹配的时候,移动匹配串s使得p与s跳过一些不必要的匹配,进而提高了时间效率。
p,s 下标都从1开始,这里为了方便代码的编写,将s提前一个位置进行比较,所以在循环时j从0开始,i从1开始,这样就保证了 i 与 j+1 对应了 i 与 j的比较。
比较思路:
1 : 当 i 与 j+1 相等时继续比较 j++,i++
2: 当 i 与 j+1 不相等时移动匹配串s 使得j 移动到新的位置与p进行匹配,如果 i 与 j+1 还不相等则继续移动,直到匹配成功或者 j 为0时意味着s不能在进行回退移动了,此时应该结束循环了。
3: j==n时意味着匹配成功,输出匹配字符串初始位置即可
代码:
for(int i=1,j=0;i<=m;i++){
while(j&&p[i]!=s[j+1]) j=ne[j];
if(p[i]==s[j+1]) j++;
if(j==n){
cout<<i-n<<' ';
j=ne[j];
}
}
第一部分:KMP算法的next数组得出过程
next数组的获得和匹配过程类似
注意要根据前缀和后缀匹配的特点进行错位处理:即 遍历一个串s 的 i从2开始 遍历第二个串的 j 从0开始;
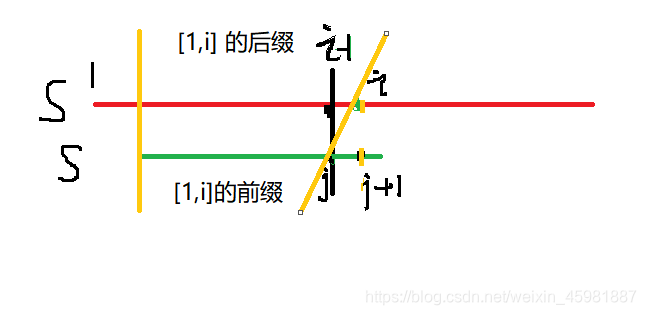
表示了前缀和后缀的匹配,s[i]==s[j+1] 时此时j++ 切记此时i不等于j因为 i 是从2开始,这保正了第二个串 后面一定有字符,保诚了串前缀匹配的要求
for(int i=2,j=0;i<=n;i++){
while(j && s[i]!=s[j+1]) j=ne[j];
if(s[i]==s[j+1]) j++;
ne[i]=j;
}
所有代码:时间复杂度O(n)
题目链接:KMP字符串匹配
#include <bits/stdc++.h>
#include <string.h>
#include <queue>
#include <stack>
using namespace std;
const int maxn=1e5+10;
int n,m;
char s[maxn],p[maxn];
int ne[maxn];
int main(){
cin>>n>>s+1 >> m >> p+1;
for(int i=2,j=0;i<=n;i++){
while(j && s[i]!=s[j+1]) j=ne[j];
if(s[i]==s[j+1]) j++;
ne[i]=j;
}
for(int i=1,j=0;i<=m;i++){
while(j&&p[i]!=s[j+1]) j=ne[j];
if(p[i]==s[j+1]) j++;
if(j==n){
cout<<i-n<<' ';
j=ne[j];
}
}
system("pause");
return 0;
}

















 1360
1360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









