








代码地址->https://github.com/cug-ygh/TMT
abstract
多模态情感识别是一项复杂的挑战,因为它涉及到使用各种模式(如视频、文本和音频)识别人类情感。现有方法主要关注多模态数据的融合信息,但忽略了对情绪有不同贡献的模态特定异质性特征的相互作用,导致结果不理想。为了解决这一挑战,我们提出了一种新的Token-disentangling Mutual Transformer (TMT),通过有效地分离和交互模态间的情感一致性特征和模态内的情感异质性特征,用于鲁棒的多模态情感识别。
具体来说,TMT包括两个主要模块:多模态情感Token解纠缠和Token相互转换。
在多模态情感Token解纠缠中,我们引入了一种具有精细Token解纠缠正则化的Token分离编码器,有效地将模态间情感一致性特征Token与各模态内情感异质性特征Token分离开来;因此,情绪相关的一致性和异质性信息可以独立和全面地执行。此外,我们设计了带有两个跨模态编码器的Token互转换器,通过双向查询学习来交互和融合分离的特征Token,从而为多模态情感识别提供更全面和互补的多模态情感表示。我们在三个流行的三模态情感数据集(即CMU-MOSI, CMU-MOSEI和CH-SIMS)上对我们的模型进行了评估,实验结果证实了我们的模型与目前最先进的方法相比具有优越的性能,实现了最先进的识别性能。
Q:什么叫token分离?什么是异质性token和一致性token?
A:token分离指的是在多模态情感识别中,通过特定的算法或模型结构(如transformer编码器)将输入的多模态数据中的特征向量进行分离和重组,使得这些特征向量更好地反映出数据的内在情感状态。这种分离过程能够将不同模态间共有的情感特征(一致性特征)与每个模态特有的情感特征(异质性特征)区分开来,从而为进一步的情感分析和识别提供更准确的信息。
异质性token:这类Token代表了每个模态内部独有的情感信息,即在多模态数据中,各个模态所表达的情感特征可能会有所不同,异质性Token就是为了捕捉这种在特定模态中独特的情感或信息特点。例如,在一段视频中,视觉信息可能显示一个人在笑,而音频信息中的语调则可能传达出悲伤,这种情况下视觉和音频的特征就是异质性的。
一致性token:这类Token代表了不同模态间共享的、相互一致的情感信息。例如,视频、音频和文本可能都在表达同一种情感如快乐或悲伤,一致性Token的目的就是捕捉并表达这种跨模态的共同情感。
intro
情绪识别是人工智能和情感计算领域的研究热点(Sun et al ., 2020a;安万忠,2023;辛格和卡普尔,2023)。传统的单模态情绪识别只关注从单一模态识别情绪(Chen and Joo, 2021),与之相比,利用不同数据源(如视频、音频和文本)的多模态情绪识别在提高对人类情绪的理解方面具有显著优势,并且更符合现实世界的情绪交互和应用(Zadeh et al ., 2017a);Tsai et al ., 2019a;Lv等,2021;Hazarika等,2020a;袁等,2021a;Yan et al ., 2023a,b)。从互联网上的视频、帖子和评论中获得的情感信息可以用于许多目的(Liu et al ., 2023;钟等人,2022)。例如,政府可以利用这些信息来预测人们想要如何投票。电影制片人可以根据评论预测电影的最终票房方向。公司可以根据用户反馈改进产品(Zeng et al ., 2024)。
为了满足真实应用场景的情感交互需求,多模态情感识别通过对不同模态的情感信息进行提取和融合,越来越受到研究者的关注。例如,Sun等人(2020b)引入了深度典型相关分析(DCCA)来捕捉模态之间的相关特征。Liang等人(2021)开发了一个模型,解决了模态不变空间中的分布差异,从而减少了模态间的异质性。Zadeh等人(2017b)将多模态特征向量融合为张量,并对模态之间的相互作用进行动态建模,成功克服了多模态场景下融合的挑战。
上述方法取得的进展主要集中在通过多模态融合技术对共同的情感信息进行建模,而忽略了不同模态的独特信息。这使得这些方法难以有效地模拟不同模态之间的情感关系,从而影响了多模态情感识别的性能
最近,Transformer由于其对序列数据的关系学习和建模能力,在计算机视觉、自然语言处理和多模态识别领域得到了广泛的应用(Dosovitskiy等;Liu et al ., 2021;Liang等,2021;Lin等,2021;Zhang et al, 2024)。例如,Delbrouck等人(2020)在Transformer模型的基础上引入了一种新的编码架构,利用模块化注意力机制对多模态的关系进行编码。Han等人(2021)采用不同的模态作为Transformer翻译模型的输入源和目标源,通过建模它们与情绪的关系来实现模态融合。Wang等人(2020)分别引入了文本音频融合模块和文本视频融合模块,利用Transformer的门控机制增强了两个模块的输出结果。
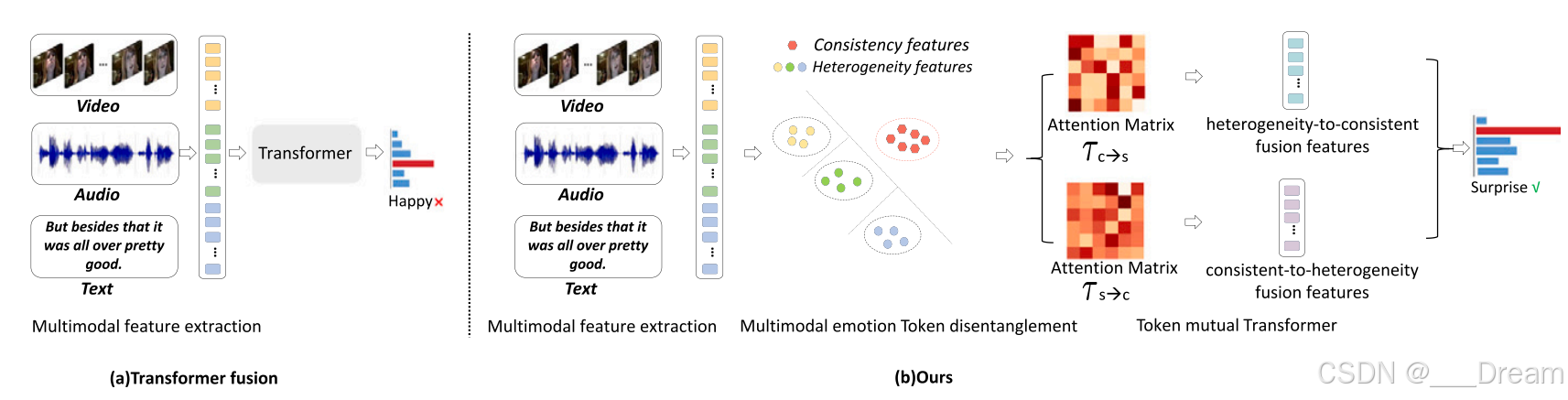
对现有的基于Transformer融合的多模态情感识别方法与基于TMT的多模态情感识别方法进行了比较。
(a)基于Transformer fusion的多模态情感识别,
(b) Our基于TMT的多模态情感识别。TMT通过联合多模态情感Token解纠缠和Token互变,实现更全面、互补的多模态情感表示,实现鲁棒性情感识别。
尽管利用Transformer进行多模态特征融合在建模不同模态之间的情感关系方面是有效的,但它们仍然没有考虑到特定模态对情感交互的微妙异构特征,从而导致次优性能(见图1)。
为此,一种策略是引入对抗学习(Yang et al ., 2022b),分别提取多模态的一致性信息和各模态的异质性信息。Park和Im(2016)将对抗性学习应用于多模态情感表示学习,仅使用类别信息进行多模态嵌入。他等人(2023)提出了对抗性不变性表征融合模型,通过缩小不同模态之间的分布差距来实现模态不变性表征。尽管取得了进展,但不同模态之间微妙的异质性相互作用仍然使我们感到困惑,并且很容易构成学习综合多模态表征的障碍。
例如,音频情态包含独特的语调情感信息,这在其他情态(如图像和文本)中很难匹配。因此,目前直接使用普通Transformer (Vaswani et al ., 2017)或多层感知器(Tolstikhin et al ., 2021)来执行异构和一致特征融合的基于对抗性学习的方法很难捕捉到它们之间微妙的异质性情感交互。也就是说,微妙但有意义的情态信息仍然会被忽略。
此外,基于对抗性学习的方法(Yang et al ., 2022b;Park and Im, 2016;他等人,2023;Liu et al ., 2023b)也需要额外的精心设计的网络模块和大量的训练数据来进行适当的训练。这可能导致巨大的模型容量,使得实现鲁棒和高效的多模态情感识别变得具有挑战性。
为了解决上述问题,我们提出了一种新的用于多模态情感识别的Token-disentangling互变器(TMT)。TMT通过引入多模态情感Token解纠缠和Token互变两个主要模块,可以有效地分离模态间情感一致性特征和模态内情感异质性特征,并将它们相互融合,形成更全面的多模态情感表征。TMT的动机以及与现有融合方法的比较如图1所示。具体而言,多模态情感Token解纠缠模块首先通过一种新颖的Token分离编码器及其Token解纠缠正则化,将模态间情感一致性特征Token与每个模态内情感异质性特征Token彻底解纠缠。然后,为了全面探索解纠缠特征Token之间的情感交互,我们进一步设计Token互转换器,通过在两个跨模态编码器中进行两次双向查询学习,将解纠缠特征整合为更全面的多模态情感表示。
结合这两个模块,我们的TMT可以实现最先进的多模态情感识别性能。综上所述,本文的重要贡献可以概括如下:
•我们提出了一种用于鲁棒多模态情感识别的新型TMT。引入多模态情感Token解纠缠模块和Token互转换模块,有效挖掘和整合多模态情感信息,实现鲁棒多模态情感识别。在三个广泛使用的数据集(CMU-MOSI, CMU-MOSEI, CH-SIMS)上的实验证明,我们的方法在多模态情感识别方面优于现有的最先进的方法。
•我们提出了一种新颖且易于实现的多模态情感Token解纠缠模块,可以有效地将模态间情感一致性特征Token与每个模态内情感异质性特征Token分离开来。为了实现这一点,我们在模块中引入了一个令牌分离编码器及其令牌解纠缠正则化,以帮助Transformer在不增加额外参数和计算复杂性的情况下分离四组特征。
•我们设计了一个双向查询学习的Token互变器,通过探索情感一致性和异质性信息在情感交互中的相互作用,充分交互和整合情感一致性和异质性信息,从而获得更全面、互补的多模态情感表征。例如,音频情态包含独特的语调情感信息,这在其他情态(如图像和文本)中很难匹配。因此,目前直接使用普通Transformer (Vaswani et al ., 2017)或多层感知器(Tolstikhin et al ., 2021)来执行异构和一致特征融合的基于对抗性学习的方法很难捕捉到它们之间微妙的异质性情感交互。也就是说,微妙但有意义的情态信息仍然会被忽略。
此外,基于对抗性学习的方法(Yang et al ., 2022b;Park and Im, 2016;他等人,2023;Liu et al ., 2023b)也需要额外的精心设计的网络模块和大量的训练数据来进行适当的训练。这可能导致巨大的模型容量,使得实现鲁棒和高效的多模态情感识别变得具有挑战性。
related work
多模态情绪识别
大多数现有的多模态情感识别方法可以大致分为两大类:基于表示学习的方法和基于多模态融合的方法。
基于表征学习的方法侧重于通过考虑不同模态的差异性和一致性来学习模态表征,从而提高多模态情感识别。例如,Yang等人(2022a)使用编码器和鉴别器通过对抗性学习学习多种模式的一致性和异质性特征。Hazarika等人(2020a)使用度量学习来学习多模态情感识别任务的模态特定和模态不变表征。Han等人(2021b)提出了一个名为MMIM的框架,该框架通过分层互信息最大化来改进多模态表示。Zhao等人(2020)提出了一种新的基于注意力的vanet,该vanet集成了空间、通道和时间注意力,用于音视频情感识别。Lv等人(2021)引入了一个消息中心,通过向每个模态发送共同的消息并加强其特征,与每个模态交换信息。Zeng等人(2024)提出了一种基于特征的多模态情感分析恢复动态交互网络。近年来,特征解缠方法已被应用于情感识别中,以实现与情感相关的特征对齐。例如,Hazarika等人(2020b)提出的MISA方法涉及通过应用精心设计的约束和编码器将每种模态投影到两个不同的子空间中。类似地,Yang等人(2022a)引入了特征分离多模态情感识别(FDMER)方法,通过将每个模态映射到模态不变子空间和模态特定子空间来解决模态异质性。
通过对抗性学习策略的结合,他们改进了特征分离的公共和私有表示。
另一个值得注意的贡献是Yang等人(2022b)提出的多模态特征分离方法(MFSA),该方法提出了一种在异步序列中获取有效多模态表示的方法,特别强调了实现特征解纠缠。
然而,这些方法主要集中在不同模态的情感表征上,忽略了进行全面特征学习的模态融合,导致性能不佳。
基于多模态融合的方法主要是为了减少模态之间的异质性,获得更全面的多模态情感特征。Zadeh等(2017b)提出了一种张量融合方法(TFN),通过计算笛卡尔积对不同模态之间的关系进行建模。Liang等(2018)提出了递归多级融合方法,通过将融合分为多个阶段,不断融合多模态信号子集来解决融合问题,完成最终的融合任务。Lv等人(2021)提出了渐进式模态强化(Progressive modal Reinforcement, PMR)方法,该方法引入模态强化单元来学习跨模态元素之间的定向配对注意,以实现模态异步融合。尽管取得了进步,但目前的许多方法主要强调多个特征的集成,很少深入研究这些特征的相互作用,并且经常忽略微妙的异构特征
多模态transformer
Transformer是Vaswani等人(2017)引入的一种基于注意力的机器翻译模块。它通过聚合整个序列的数据来学习token之间的关系,在语音处理、自然语言处理和计算机视觉等各种任务中表现出出色的建模能力(Kenton and Toutanova, 2019;Carion等,2020;Chen et al ., 2022;刘等,2023a;Tang et al ., 2023, 2022)。Dosovitskiy等人提出了一种方法,该方法包括在序列中添加一个额外的可学习令牌,以捕获
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1788
1788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









