




 本文围绕多模态大语言模型展开研究。探讨了建立高性能MLLMs的关键设计,分析资源节约型战略应对大型模型资源挑战,还介绍了多对象图像生成代理、统一多模态模型等。此外,研究了基于Transformer的扩散模型,以及视觉语音处理和多语言视觉语音识别的新框架与策略。
本文围绕多模态大语言模型展开研究。探讨了建立高性能MLLMs的关键设计,分析资源节约型战略应对大型模型资源挑战,还介绍了多对象图像生成代理、统一多模态模型等。此外,研究了基于Transformer的扩散模型,以及视觉语音处理和多语言视觉语音识别的新框架与策略。
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
在这项工作中,我们讨论了建立高性能的多模态大型语言模型(MLLMs)。特别是,我们研究了各种模型结构组件和数据选择的重要性。通过对图像编码器、视觉语言连接器和各种预训练数据选择的仔细而全面的验证,我们确定了几个关键的设计教训。
例如,我们证明,与其他已发表的多模式预训练结果相比,对于使用图像字幕、交错图像文本和纯文本数据的仔细混合的大规模多模态预训练,在多个基准上实现最先进的(SOTA)few-shot结果是至关重要的。
此外,我们还表明,图像编码器以及图像分辨率和图像令牌计数具有实质性影响,而视觉语言连接器设计的重要性相对可以忽略不计。
通过扩大所提出的方案,我们构建了MM1,这是一个多模态模型家族,包括高达30B的密集变体和高达64B的专家混合变体,它们在预训练指标中是SOTA,并在对一系列已建立的多模式基准进行监督微调后实现竞争性能。得益于大规模的预训练,MM1具有增强的上下文学习和多图像推理等吸引人的特性,能够实现少镜头的思维链提示。
A survey of resource-efficient llm and multimodal foundation models
大型基础模型,包括大型语言模型(LLM)、Vision-Transformer(ViT)、Diffusion模型和基于LLM的多模态模型,正在彻底改变从训练到部署的整个机器学习生命周期。
然而,这些模型在多功能性和性能方面的实质性进步在硬件资源方面付出了巨大成本。为了以可扩展和环境可持续的方式支持这些大型模型的增长,人们非常重视制定资源节约型战略。
这项调查深入探讨了此类研究的关键重要性,考察了算法和系统方面。它提供了从现有文献中收集到的全面分析和有价值的见解,涵盖了从尖端模型架构和训练/服务算法到实用系统设计和实现的广泛主题。这项调查的目标是对当前方法如何应对大型基础模型带来的资源挑战进行总体了解,并有可能激发该领域的未来突破。
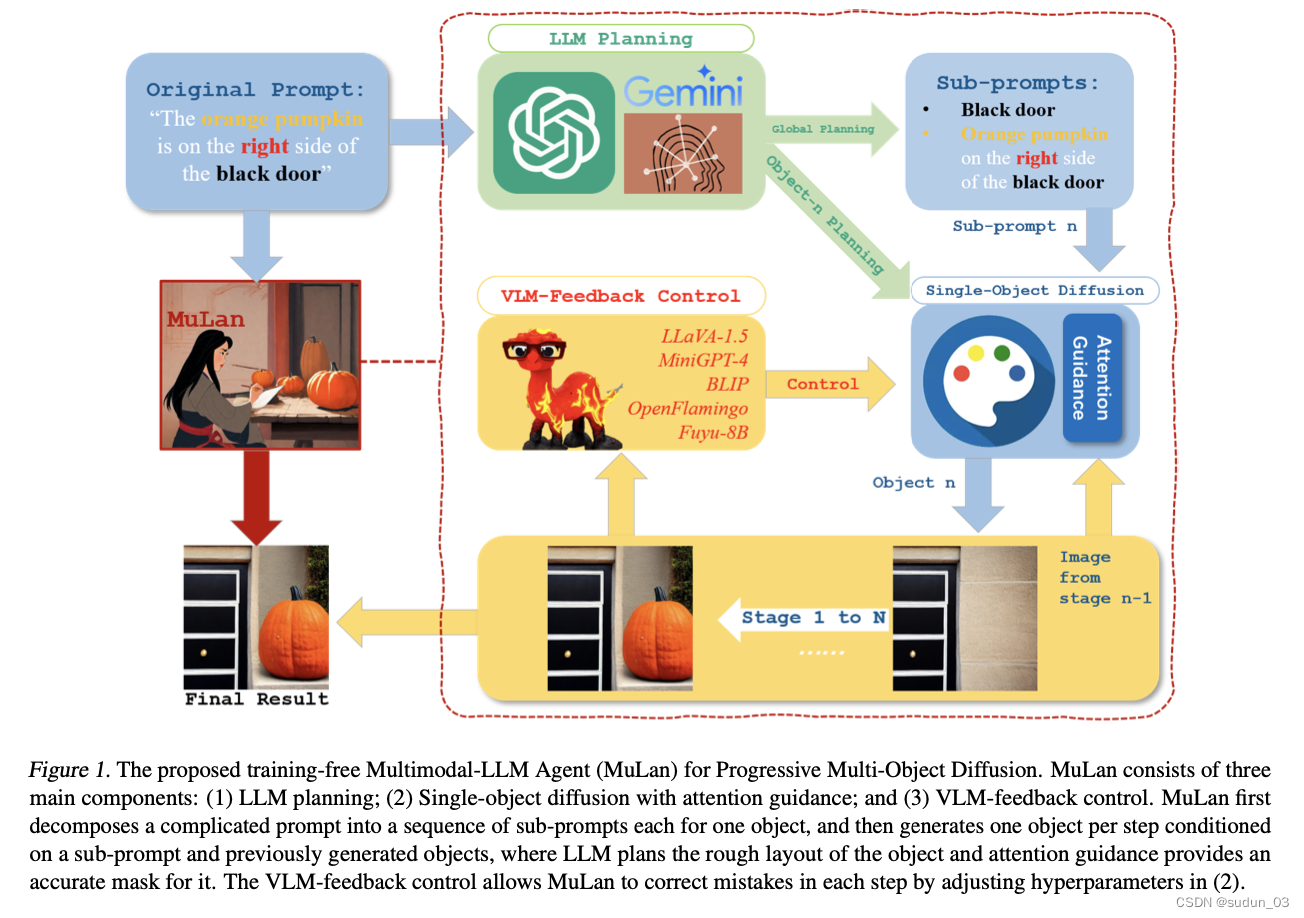
Mulan: Multimodal-llm agent for progressive multi-object diffusion
现有的文生图模型仍然很难生成多个对象的图像,特别是在处理其空间位置、相对大小、重叠和属性绑定时。在本文中,我们开发了一种无需训练的多模式LLM代理(MuLan),通过具有规划和反馈控制的渐进式多对象生成来应对这些挑战,就像人类画家一样。
MuLan利用大型语言模型(LLM)将提示分解为一系列子任务,每个子任务仅生成一个对象,条件是之前通过稳定扩散生成的对象。与现有的LLM基础方法不同,MuLan只在开始时生成高级计划,而每个对象的确切大小和位置由LLM和每个子任务的注意力指导决定。
此外,MuLan采用视觉语言模型(VLM)为每个子任务中生成的图像提供反馈,并控制扩散模型,以便在违反原始提示符时重新生成图像。因此,MuLan每个步骤中的每个模型只需要解决它专门针对的简单子任务。我们收集了200个提示,其中包含来自不同基准的具有空间关系和属性绑定的多对象,以评估MuLan。结果表明,MuLan在生成多个对象方面优于基线。该代码可在此https URL上找到。
Large Multimodal Agents: A Survey
Large language models (LLMs) have achieved superior performance in powering text-based AI agents, endowing them with decision-making and reasoning abilities akin to humans. Concurrently, there is an emerging research trend focused on extending these LLM-powered AI agents into the multimodal domain. This extension enables AI agents to interpret and respond to diverse multimodal user queries, thereby handling more intricate and nuanced tasks. In this paper, we conduct a systematic review of LLM-driven multimodal agents, which we refer to as large multimodal agents ( LMAs for short). First, we introduce the essential components involved in developing LMAs and categorize the current body of research into four distinct types. Subsequently, we review the collaborative frameworks integrating multiple LMAs , enhancing collective efficacy. One of the critical challenges in this field is the diverse evaluation methods used across existing studies, hindering effective comparison among different LMAs . Therefore, we compile&n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









